linux ext3/ext4文件系统(part1格式化)
ext4文件系统结构
ext3的代码已经在v4.3被删除掉了(ARM: tegra: Rebuild default configuration on v4.3-rc1 · torvalds/linux@241e077 · GitHub)
ext4格式化的代码可以参考e2fsprogs的实现:mke2fs.c
格式化后的文件系统结构如下图:
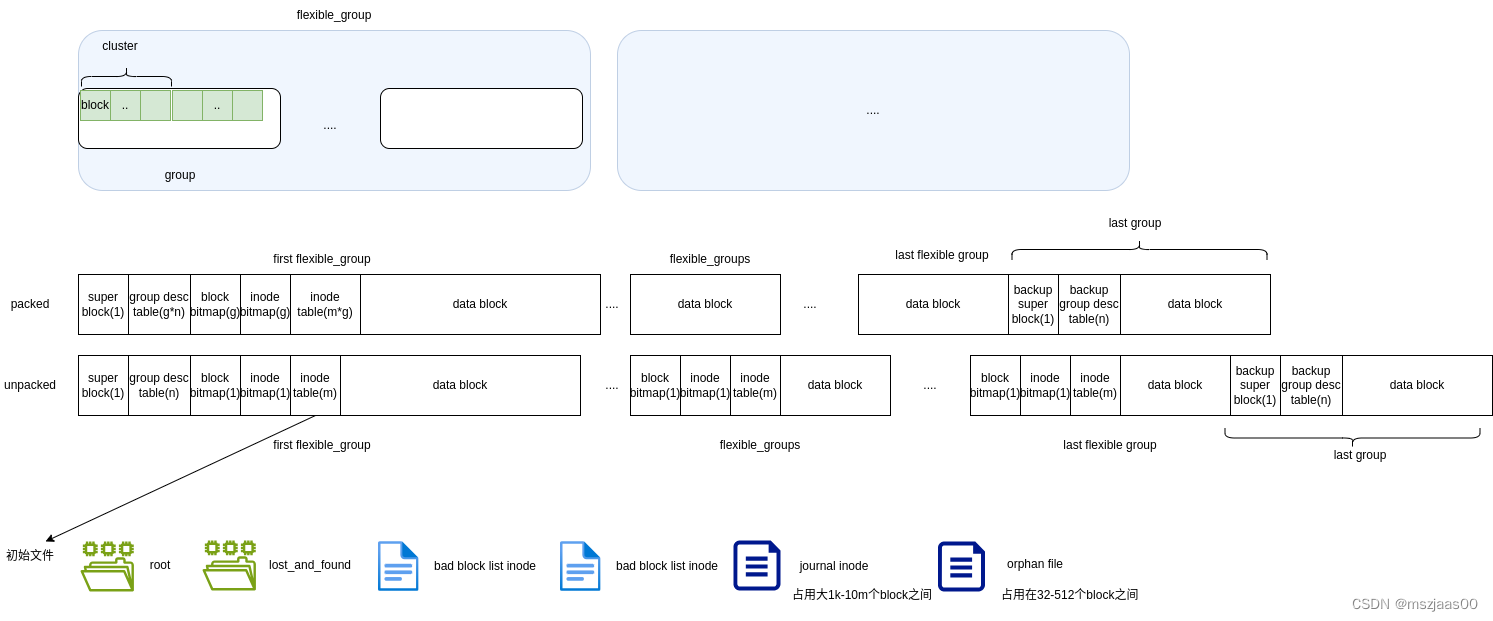
flexible group
如果支持flexible group功能,默认可将16个group打包为一个flexible group。
每个group 都有四个主要区域:
- block bitmap
- inode bitmap
- inode table
- data
其中前三部分是元数据,元数据在 flexible 模式下有两种布局方式:
- 一种是全部放在第一个flexible group的第一个group上。
- 另一种是每个flexible group中第一个group上存放这个flexible group 的元数据
当元数据占用达到一个group的四分之三时,会将这个group的全部作为元数据存储,称meta_group。
如果不启用flexible,则每个group维护自己的元数据(参考:linux 中 ext2文件系统实现)
group 中块数在256~8*block_size之间,默认8 * block_size(比如一块4096大小的话,一个group有32k个block)。
元数据备份
ext2支持为0、1、3/5/7的n次方块加入super block 与group desc block的备份 (参考:linux 中 ext2文件系统实现)。ext4将这标记成了deprecated。如果开启备份,则只备份一份,默认备份在最后一个group上。
block cluster
ext4将block打包成了cluster(默认16个block 为一个cluster),在分配块时,以cluster为最小单位去分配。格式化过程中会先在内存中存一个 block bitmap, 以block为最小单位去分配块,在分配完block/inode bitmap和inode table 后,会将bitmap将为以 cluster 为单位,存到磁盘上。
初始文件
初始文件至少有root 和 lost_and_found目录,其它:
- 如果有bad block,会将bad block 的位置以数组形式存到bad block inode上
- 如果启用日志功能,则生成日志文件,它包含了fast commit 日志和普通的日志(fast commit 记录更精练,是一种优化的日志,具体实现还没有看,参考:LWN: ext4 文件系统的快速提交!-CSDN博客)两部分日志的大小的和限制在1k-10m个block之间。
- 如果启用orphan file 功能(删除文件时,先将inode记入orphan file,在inode的data块完全释放后才将inode从orphan file移除,防止系统崩溃后文件删除了,但内容块没有回收的情况),创建orphan file 它的大小在32-512个block之间(总块数除以4k)。
e2fsprogs对ext4格式化的实现
main():
// 1、解析用户参数,有些参数从profile读
PRS(argc, argv):
blocksize:1024~65536之间
block per group:默认8 * block_size块
inodes_count:默认第8192字节对应一个inode
meta group:是否指定了完全存元数据的 group
num_backups: super + group desc 的备份group号,默认是1号和最后一个group
cluster_size:默认16个block
// 2、计算参数
ext2fs_initialize():
计算 s_clusters_per_group
计算 desc_blocks:每个group一个desc
计算 s_inodes_count 默认平均4096byte一个inode
计算 s_inodes_per_group
计算 s_reserved_gdt_blocks:为以后扩展ext4大小预留的group desc,预计filesystem大小可以增长到1024倍
group desc block 大于3/4的group时,启用meta block group,并 s_reserved_gdt_blocks为0
最后一个group要装备份super + group desc block,如是太小,要删掉最后一个group重算上面的参数
在分配内存记录格式化占用的block,此时的block bitmap单位是block,不是cluster
分配其它内存,比如inode bitmap,group desc
3、检测标记坏块,并标记在block bitmap上
4、分配block bitmap、 inode bitmap、 inode table,有两种模式packed/unpacked(packed_allocate_tables、ext2fs_allocate_tables)
5、将block bitmap 转为以cluster 为单位的bitmap
6、分配inode初始文件
root lost_and_found
标记reserve inode
创建bad block inode 记录哪些块不能用
添加journal inode 占用1k-10m个块之间
添加orphan file 最多32-512个block