clickhouse(一)两分片两副本集群搭建
最近工作中遇到了clickhouse副本存储的问题,所以准备搭建一套clickhouse集群研究下,这里将搭建的过程和遇到的坑记录下,便于以后使用。下面是集群的大致分布以及具体的搭建流程。
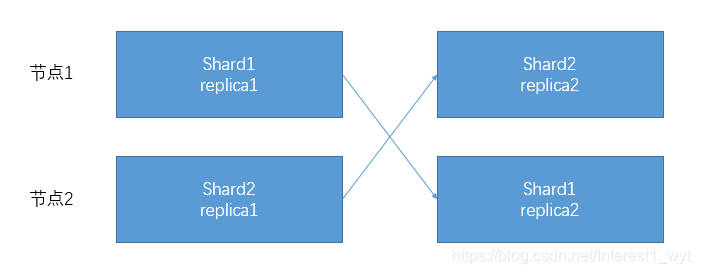
1、准备两台虚拟机,分别安装clickhouse的服务端和客户端
准备的虚拟机是centos7。这里的安装过程是纯粹拷贝的官网命令,首先 验证虚拟机是否支持clickhouse的安装:
grep -q sse4_2 /proc/cpuinfo && echo "SSE 4.2 supported" || echo "SSE 4.2 not supported"
其次,安装clickhouse需要的依赖:
sudo yum install yum-utils
sudo rpm --import https://repo.clickhouse.tech/CLICKHOUSE-KEY.GPG
sudo yum-config-manager --add-repo https://repo.clickhouse.tech/rpm/stable/x86_64
最后,一条语句安装clickhouse的服务端和客户端:
sudo yum install clickhouse-server clickhouse-client
官网还有更多安装方式(参考地址:https://clickhouse.tech/docs/en/getting-started/install/),特别是如果最后一条安装客户端服务端命令失败时,可以直接下载对应的rpm包,常见的下载client、server、common三个包,因为正常yum命令安装也是安装这三个包,官网点击位置如下:
下载的样例如下:
下载完后,rpm安装命令如下:
rpm -ivh clickhouse-common-static-21.7.2.7-2.x86_64.rpm clickhouse-client-21.7.2.7-2.noarch.rpm clickhouse-server-21.7.2.7-2.noarch.rpm
安装时,可能会需要输入默认用户的密码,一般是为空直接回车,如果设置了也没事,可以在安装完成后进入/etc/clickhouse-server/users.d/目录下,删除里面的文件即可。
2、启动和验证
这里仅是用于启动和验证刚才安装的服务是否可用,集群的验证在集群搭起来后进行。完成后,使用官网命令启动服务:
clickhouse-server --config-file=/etc/clickhouse-server/config.xml
这个命令会把clickhouse-server进程的信息持续打印在当前窗口,如果报用户权限问题,如下:
Effective user of the process (root) does not match the owner of the data (clickhouse). Run under 'sudo -u clickhouse'
可以进入/var/lib/目录,通过如下命令修改文件的访问权限为root(我测试用的是root,所以这块要看不同人的配置)。
chown -R root:root /var/lib/clickhouse
其实报错中还提示了一种解决方式就是通过sudo命令切换账号,但是我切换后,有些root可以访问的文件是clickhouse用户访问不了,所以我采用了修改clickhouse相关文件的访问用户为root的方式。所以如果启动没报错,可以另开一个窗口,输入clickhouse-client看看能否正确进入客户端。另外如果嫌弃上述启动clickhouse服务的方式需要占用一个命令窗不安全和方便,可以通过在命令后添加 --daemon 参数来设置linux服务器后来启动clickhouse-server
这里再说一个坑,就是使用sytemctl命令启动服务:
systemctl start clickhouse-server
单节点单实例这个命令不会有任何问题,也就是不会出现上面所说的用户访问权限问题,但是单节点多实例,这个命令就会出现用户组和用户的权限问题。所以该命令方式尽量慎用,尽量采用官网推荐方式(具体原因好像和systemctl的机制有关,后面有时间再研究)
最后验证结束即可关闭运行窗口,开始进行后续的多实例集群配置。
3、安装zookeeper集群
clickhouse对zookeeper的依赖很重,所以必须要有zookeeper集群。
因为之前三个节点已经有zk集群,所以这里我没有专门安装部署,如果没部署可以任意搜篇文章参考部署(下面我简述下自己zk的配置,用于以后个人参考,大家如果看着条理不清晰,建议上网查专门的文章参考)。
zk的安装部署很简单,主要是下载对应的包,然后解压,重命名zoo.cfg文件,在配置末尾加上集群信息(这里我用的是host映射方式,没有直接写ip):
server.1=bigdata.node1:2888:3888
server.2=bigdata.node2:2888:3888
server.3=bigdata.node3:2888:3888
最后再zoo.cfg中 dataDir=*** 指定的目录下创建myid文件,里面加上zk节点的序号,注意每个节点都不一样。
另外如果想修改zk的日志存储地址,可以修改log4j.properties中的相关属性配置
4、修改配置文件
clickhouse-server的配置文件一般有两个,都位于/etc/clickhouse-server目录下,名称分别为config.xml,users.xml,后者用于配置clickhouse的账号密码等用户访问权限,前者则是配置除此外的其它所有配置。这里不准备修改用户账号信息,所以不准备修改users.xml文件,下面仅仅是修改config.xml文件。
另外,网上很多文章配置集群时都会新建一个metrika.xml文件,这是因为在config.xml中可以使用<include_from>标签引入外部XML文件的配置,如集群、ZooKeeper配置等,并在其他标签中使用incl属性直接引用之(千万要记得用incl属性引入,仅仅用<include_from>标签引入不会生效)。但这并非强制的规范,我这里为了减少配置的文件数,所以都是直接在config.xml中配置。
为了防止浏览配置文件不清晰主机名,这里提一下,我个人大数据集群有node1、node2、node3三个节点,后两个节点用来安装的clickhouse双分片双副本集群。
这里首先在每个节点通过
cp /etc/clickhouse-server/config.xml /etc/clickhouse-server/config2.xml
命令生成第二个实例的配置文件,配置的内容主要由三块,分别是:
4.1、日志、数据存储路径以及各种端口号
这些内容在单节点单实例集群中其实不用修改,单节点多实例为了避免冲突,所以需要配置一下:
节点1(节点2的config.xml与这个相同) config.xml
<logger>
<level>trace</level>
<log>/var/log/clickhouse-server/clickhouse-server.log</log>
<errorlog>/var/log/clickhouse-server/clickhouse-server.err.log</errorlog>
<size>1000M</size>
<count>10</count>
</logger>
<http_port>8123</http_port>
<tcp_port>9001</tcp_port>
<mysql_port>9004</mysql_port>
<postgresql_port>9005</postgresql_port>
<interserver_http_port>9009</interserver_http_port>
<listen_host>::</listen_host>
<path>/var/lib/clickhouse/</path>
<tmp_path>/var/lib/clickhouse/tmp/</tmp_path>
<user_files_path>/var/lib/clickhouse/user_files/</user_files_path>
节点1(节点2的config2.xml与这个相同) config2.xml
<logger>
<level>trace</level>
<log>/var/log/clickhouse-server2/clickhouse-server.log</log>
<errorlog>/var/log/clickhouse-server2/clickhouse-server.err.log</errorlog>
<size>1000M</size>
<count>10</count>
</logger>
<http_port>8124</http_port>
<tcp_port>9002</tcp_port>
<mysql_port>9010</mysql_port>
<postgresql_port>9011</postgresql_port>
<interserver_http_port>9012</interserver_http_port>
<listen_host>::</listen_host>
<path>/var/lib/clickhouse2/</path>
<tmp_path>/var/lib/clickhouse2/tmp/</tmp_path>
<user_files_path>/var/lib/clickhouse2/user_files/</user_files_path>
这里需要留意的是两个点,一个是端口的设置,设置端口前可以用lsof -i:port命令来查端口使用情况。如果没有任何提示信息则表明端口未被使用。另一个要留意的则是config2.xml中新增了/var/lib/clickhouse2文件夹和/var/log/clickhouse-server2文件夹,如果启动的时候报文件夹不存在或上述的用户访问权限问题,则可以先通过mkdir以及chown -R命令来创建和更改文件访问用户。我是先建立的文件夹然后再更改用户访问,所以启动的时候没有遇到访问限制。
4.2、clickhouse和zookeeper集群配置
这里需要留意的是clickhouse副本和分片的定义问题,通过配置可以看到,分片shard里面直接就是副本replica的信息,简单理解为分片由副本组成,所以双分片双副本也可以简单看做两分片一副本。
所有配置文件中相同
<remote_servers>
<!-- 集群名称,可以自定义修改 -->
<ck_2shard_2replica_cluster>
<shard>
<!-- 每个分片的写入权重值,数据写入时会有较大概率落到weight值较大的分片,这里全
部设为1,即所有分片写入的概率相同 -->
<weight>1</weight>
<!-- 是否启用内部复制。true 代表写入数据时选择第一个健康的副本进行写入,其余
副本以该表本身进行复制,保证复制表的一致性。false(默认) 代表将数据直接写入所
有副本,如果有节点数据出现不一致,将不会自动修复 -->
<internal_replication>true</internal_replication>
<replica>
<host>node2</host>
<port>9001</port>
<user>default</user>
<password></password>
</replica>
<replica>
<host>node3</host>
<port>9002</port>
<user>default</user>
<password></password>
</replica>
</shard>
<shard>
<weight>1</weight>
<internal_replication>true</internal_replication>
<replica>
<host>node3</host>
<port>9001</port>
<user>default</user>
<password></password>
</replica>
<replica>
<host>node2</host>
<port>9002</port>
<user>default</user>
<password></password>
</replica>
</shard>
</ck_2shard_2replica_cluster>
</remote_servers>
<zookeeper>
<node>
<host>node1</host>
<port>2181</port>
</node>
<node>
<host>node2</host>
<port>2181</port>
</node>
<node>
<host>node3</host>
<port>2181</port>
</node>
</zookeeper>4.3、宏定义
可以简单理解为一种全局变量,使用时可以仅使用变量名,clickhouse服务器会替换成我们设定的变量值,目前用的最多的就是定义分片副本宏变量,然后再创建副本表时使用。
节点1 config.xml
<!-- 宏定义,子标签有:
1、{layer} - ClickHouse集群的昵称,用于区分不同集群之间的数据。
2、{shard} - 分片编号或符号引用。
3、{replica} - 副本的名称(唯一),通常与主机名匹配,macros为可选定义。
-->
<macros>
<shard>01</shard>
<replica>01-1</replica>
</macros>
节点1 config2.xml
<macros>
<shard>02</shard>
<replica>02-2</replica>
</macros>
节点2 config.xml
<macros>
<shard>02</shard>
<replica>02-1</replica>
</macros>
节点2 config2.xml
<macros>
<shard>01</shard>
<replica>01-2</replica>
</macros>6、验证集群是否被定义好
每个节点分别执行下面两条命令,将4个实例启动起来:
clickhouse-server --config-file=/etc/clickhouse-server/config.xml
clickhouse-server --config-file=/etc/clickhouse-server/config2.xml
通过clickhouse-client --port 9001进入任一节点实例,通过如下命令查看已定义集群信息:
select * from system.clusters;
出现下图则说明两分片两副本的集群正常定义和加载:
7、验证集群副本能力
首先建立具有副本能力的ReplicatedMergeTree引擎表:
create table goods3_cluster on cluster ck_2shard_2replica_cluster(
id int,
name String,
price int
)ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/default/goods3_cluster','{replica}')
ORDER BY id
然后插入一条测试数据:
insert into goods3_cluster values(1,'92号牛奶',88)
在当前节点查询: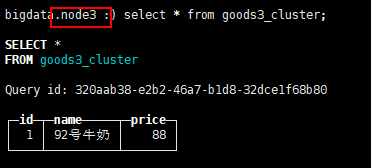
在另一节点副本实例上查询: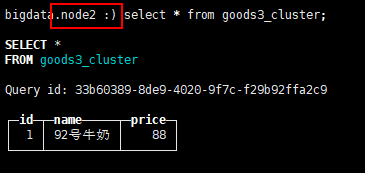
我们在一个节点插入数据,对应的副本上同样会有数据,可以看到集群的功能已经基本正常。
参考文章:
clickhouse安装部署详细步奏,让你学习之路少走坑_clickhouse tar包部署-CSDN博客
ClickHouse高可用集群的安装与部署 - 简书