深入理解异步编程
同步、异步,并发、并行、串行,这些名词在我们的开发中会经常遇到,这里对异步编程做一个详细的归纳总结,希望可以对这方面的开发有一些帮助。
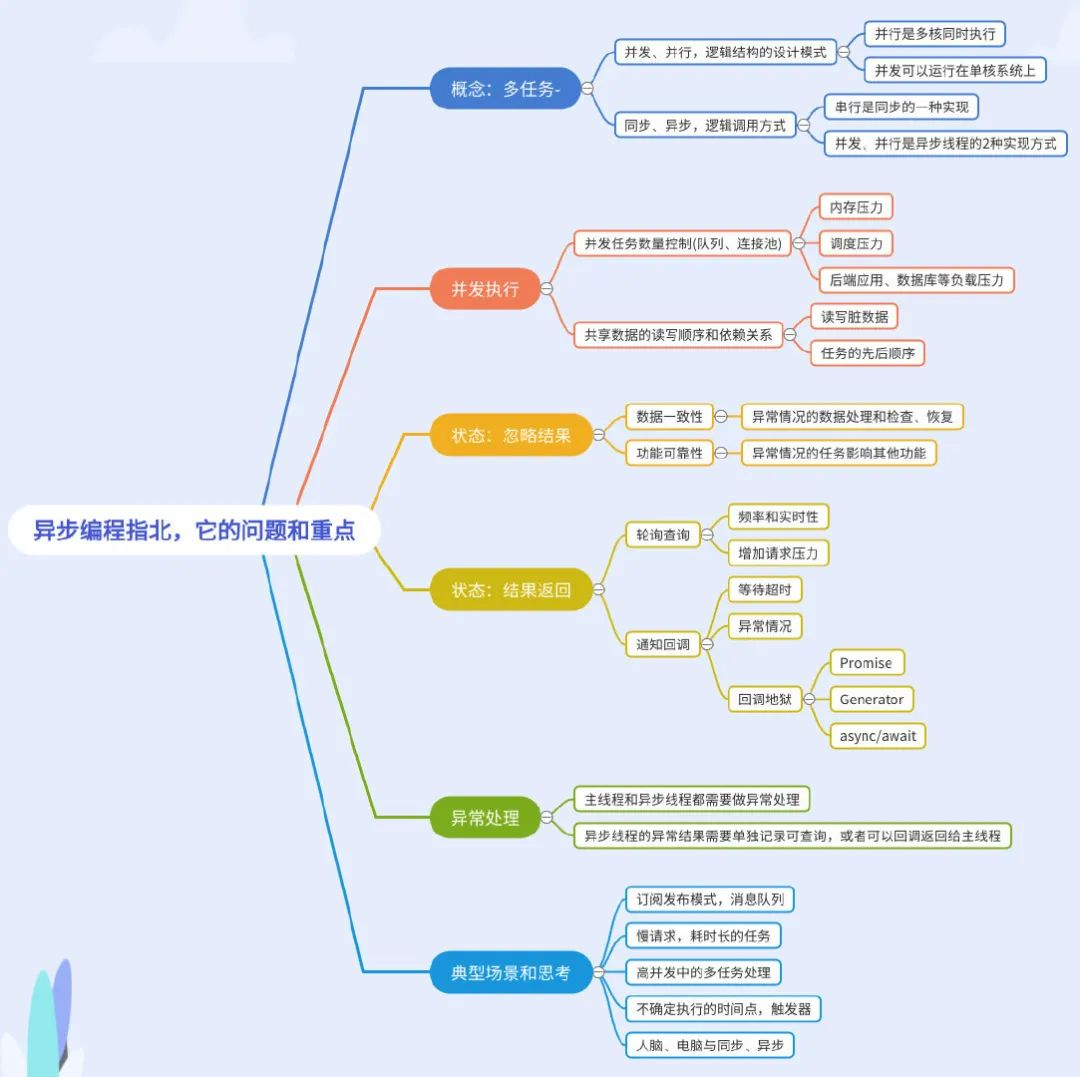
1 几个名词的概念
多任务的时候,才会遇到的情况,如:同步、异步,并发、并行。
1.1 理清它们的基本概念
| 逻辑调用方式 | 逻辑结构的设计模式 |
|---|---|
同步:多任务开始执行,任务 A、B、C 全部执行完成后才算是结束。异步:多任务开始执行,只需要主任务 A 执行完成就算结束,主任务执行的时候,可以同时执行异步任务 B、C,主任务 A 可以不需要等待异步任务 B、C 的结果。 | 并发:多个任务在同一个时间段内同时执行,如果是单核心计算机,CPU 会不断地切换任务来完成并发操作。并行:多任务在同一个时刻同时执行,计算机需要有多核心,每个核心独立执行一个任务,多个任务同时执行,不需要切换。 |
串行是同步的一种实现,就是没有并发,所有任务一个一个执行完成。 | 并发、并行是异步的 2 种实现方式。 |
1.2 举一个例子
你的朋友在广州,但是有 2 辆小汽车在深圳,需要你帮忙把这 2 辆小汽车送到广州去。
同步的方式,你先开一辆小汽车到广州,然后再坐火车回深圳,再开另外一辆小汽车去广州。这是串行的方法,2 辆车需要的时间也就更长了。
异步的方式,你开一辆小汽车从深圳去广州,同时请一个代驾开另外一辆小汽车从深圳开去广州。这也就是并行方法,两个人两辆车,可以同时行驶,速度很快。
并发的方式,你一个人,先开一辆车走 500 米,停车跑回来,再开另外一辆车前行 1000 米,停车再跑回来,循环从深圳往广州开。并发的方式,你可以把 2 辆车一块送到朋友手里,但是过程还是很辛苦的。
1.3 思考问题
你找一家汽车托运公司,把 2 辆车一起托运到广州。这种方式是同步、异步,并发、并行的哪种情况呢?
2 并发/并行执行会遇到的问题
2.1 问题 1:并发的任务数量控制

假设:某个接口的并发请求会达到 1 万的 qps,所以对接口的性能、响应时长都要求很高。
接口内部又有大量 redis、mysql 数据读写,程序中还有很多处理逻辑。如果接口内的所有逻辑处理、数据调用都是串行化,那么单个请求耗时可能会超过 100ms,为了性能优化,就会把数据读取的部分与逻辑计算的部分分开来考虑和实现,能够独立的部分单独剥离出来作为异步任务来执行,这样就把串行化的耗时优化为并发执行,充分利用多核计算机的性能,减少单个接口请求的耗时。
假设的数据具体化,如:这个接口的数据全部是可以独立获取(支持并发),需要读取来自不同数据结构的 redis 共 10 个,读取不同数据表的数据共 10 个。那么一次请求,数据获取就会启动 10 个 redis 读取任务,10 个 mysql 读取任务。每秒钟 1 万接口请求,会有 10 万个 redis 读取任务和 10 万个 mysql 读取任务。这 21 万的并发任务,在一秒钟内由 16/32 核的后端部署单机来完成,虽然在同一时刻的任务数量不一定会是 21 万(速度快的话会少于 21 万,如果处理速度慢,出现请求积压拥堵,会超过 21 万)。
这时候,会遇到的瓶颈。
内存,如果每个任务需要 500k 内存,那么 210k0.5M=2100.5G=105G.
CPU,任务调度,像 golang 的协程可能开销还小一些,如果是 java 的线程调度,操作系统会因为调度而空转。
网络,每次数据读取 5k,那么 200k5k=2005M=1G.
端口,端口号最多能分配出来 65536 个,明显不够用了。
数据源,redis 可以支持 10 万 qps 的请求,但是 mysql 就难以支持 10 万 qps 了。
上面可能出现的瓶颈中,通过计算机资源扩容可以解决大部分问题,比如:部署 50 个后端实例,每个实例只需要应对 200 的 qps,压力就小了很多。对于数据源,mysql 可以有多个 slave 来支持只读的请求。
但是,如果接口的并发量更大呢?或者某个/某些数据源读取出现异常,需要重试,或者出现拥堵,接口响应变慢,任务数量也就会出现暴增,后端服务的各方面瓶颈又会随之出现。
所以,我们需要特别注意和关心后端开启的异步任务数量,要做好异常情况的防范,及时中断掉拥堵/超时的任务,避免任务暴增导致整个服务不可用。
2.2 思考问题
你要如何应对这类并发任务暴增的情况呢?如何提前预防?如何及时干预呢?
2.3 问题 2:共享数据的读写顺序和依赖关系
共享数据的并发读写,是并发编程中的老大难问题,如:读写脏数据,旧数据覆盖新数据等等。
而数据的依赖关系,也就决定了任务的执行先后顺序。
为了避免共享数据的竞争读写,为了保证任务的先后关系,就需要用到锁、队列等手段,这时候,并发的过程又被部分的拉平为串行化执行。
2.4 举个例子
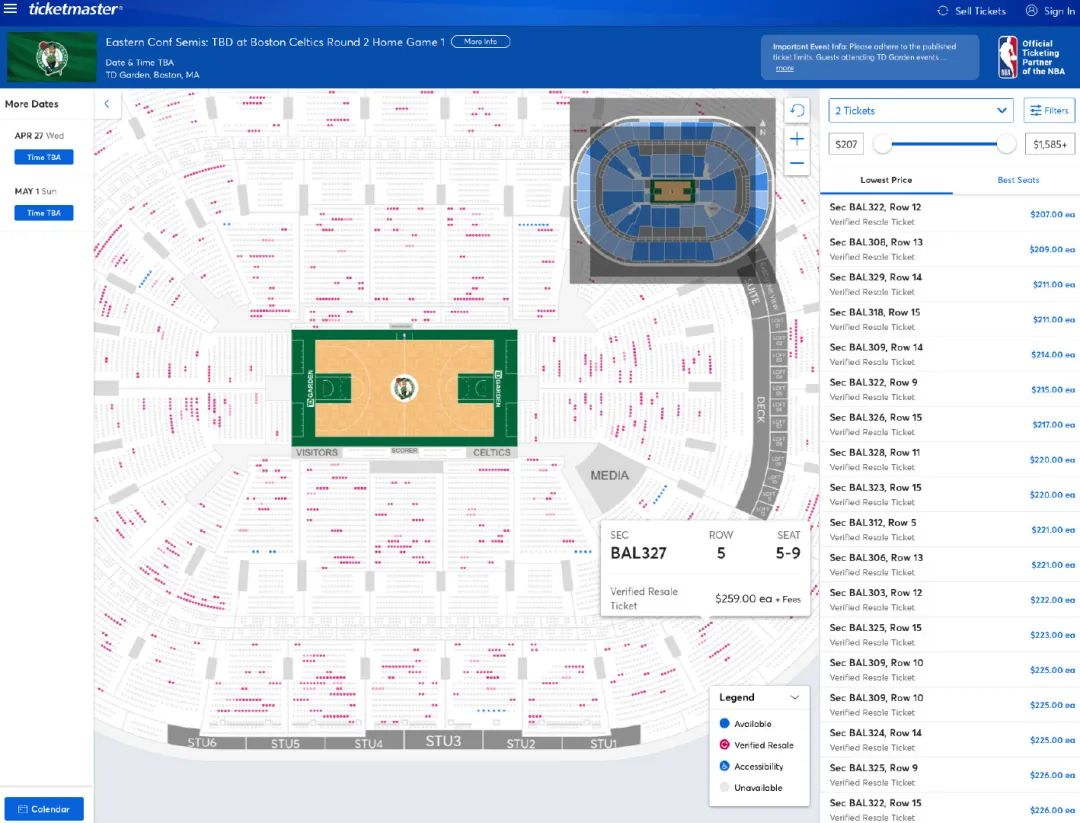
https://www.ticketmaster.com/eastern-conf-semis-tbd-at-boston-boston-massachusetts/event/01005C6AA5531A90
NBA 季后赛,去现场看球,要抢购球票,体育馆最多容纳 1 万人(1 万张球票)。
体育馆不同距离、不同位置的票,价格和优惠都不相同。有单人位、有双人位,也有 3、4 人位。你约着朋友共 10 个人去看球,要买票,要选位置。这时候抢票就会很尴尬,因为位置连着的可能会被别人抢走,同时买的票越多,与人冲突的概率就越大,会导致抢票特别困难。
同时,这个系统的开发也很头大,抢购(秒杀)的并发非常大,预计在开始的一秒钟会超过 10 万人同时进来,再加上刷票的机器人,接口请求量可能瞬间达到 100 万的 QPS。
较简单的实现方式,所有的请求都异步执行,订单全部进入消息队列,下单马上响应处理中,请等待。然后,后端程序再从消息队列中串行化处理每一个订单,把出现冲突的订单直接报错,这样,估计 1 秒钟可以处理 1000 个订单,10 秒钟可以处理 1 万个订单。考虑订单的冲突问题,1 万张球票的 9000 张可能在 30 秒内卖出去,此时只处理了 3 万个订单,第一秒钟进来的 100 万订单已经在消息队列中堆积,又有 30 秒钟的新订单进来,需要很久才可以把剩下的 1000 张球票卖出去啊。同理,下单的用户需要等待太久才知道自己的订单结果,这个过程轮询的请求也会很多很多。
换一种方案,不使用队列串行化处理订单,直接并发的处理每一个订单。那么处理流程中的数据都需要梳理清楚。
1 针对每一个用户的请求加锁,避免同一个用户的重入;
2 每一个/组座位预生成一个 key:0,默认 0 说明没有下单;
3 预估平均每一个订单包含 2 个/组座位,需要更新 2 个座位 key;
4 下单的时候给座位 key 执行 INCR key 数字递增操作,只有返回 1 的订单才是成功,其他都是失败;
5 如果同一个订单中的座位 key 有冲突的情况下,需要回滚成功 key(INCR key = 1)重置(SET key 0);
6 订单成功/失败,处理完成后,去掉用户的请求锁;
7 订单数据入库到 mysql(消息队列,避免 mysql 成为瓶颈);
综上,需要用到 1 个锁(2 次操作),平均 2 个座位 key(每个座位号 1-2 次操作),这里只有 2 个座位 key 可以并发更新。为了让 redis 不成为数据读写的瓶颈(超过 100w 的 QPS 写操作),不能使用单实例模式,而要使用 redis 集群,使用由 10-20 个 redis 实例组成的集群,来支持这么高的 redis 数据读写。
算上 redis 数据读写、参数、异常、逻辑处理,一个请求大概耗时 10ms 左右,单核至少可以支持 100 并发,由于这里有大量 IO 处理,后端服务可以支持的并发可以更高些,预计单核 200 并发,16 核就可以支持 3200 并发。总共需要支持 100 万并发,预计需要 312 台后端服务器。
这种方案比队列的方案需要的服务器资源更多,但是用户的等待时间很短,体验就好很多。
2.5 思考问题
实际情况会是怎样呢?会有 10 万人同时抢票吗?会有 100 万的超高并发吗?订票系统真的会准备 300 多台服务器来应对抢票吗?
3 状态处理:忽略结果
3.1 使用场景和案例
使用场景,主流程之外的异步任务,可能重要程度不高,或者处理的复杂度太高,有时候会忽略异步任务的处理结果。
案例 1:异步的数据上报、数据存储/计算/统计/分析。
案例 2:模板化创建服务,有很多个任务,有前后关联任务,也有相互独立任务,有些执行速度很慢,有些任务失败后也可以手动重试来修复。
忽略结果的情况,就会遇到下面的问题。
3.2 问题 1:数据一致性
看下案例 1 的情况。
异步的日志上报,是否成功发送到服务端呢?
异步的指标数据上报,是否正确汇总统计和发送到服务端呢?
异步的任务,数据发送到消息队列,是否被后端应用程序消费呢?
服务端是否正常存储和处理完成呢?
如果因为网络原因,因为并发量太大导致服务负载问题,因为程序 bug 的原因,导致数据没能正确上报和处理,这时候的数据不一致、丢失的问题,就会难以及时排查和事后补发。
如果在本地完整记录一份数据,以备数据审查,又要考虑高并发高性能的瓶颈,毕竟本地日志读写性能受到磁盘速度的影响,性能会很差。
3.3 问题 2:功能可靠性
看下案例 2 的情况。
创建服务的过程中,有创建代码仓库、开启日志采集和自定义镜像中心,CI/CD 等耗时很长的任务。这里开启日志采集和自定义镜像中心如果出现异常,对整个服务的运行没有影响,而且开发者发现问题后也可以自己手动操作下,再次开启日志采集和自定义镜像功能。所以在模板化处理中,这些异步处理任务就没有关注任务的状态。
那么问题就很明显,模板化创建服务的过程中,是不能保证全部功能都正常执行完成的,会有部分功能可能有异常,而且也没有提示和后续指引。
当然模板化创建服务的程序,也可以把全部任务的状态都检查结果,只是会增加一些处理的复杂度和难度。
3.4 思考问题
实际开发中,有遇到类似上面的两个案例吗?你会如何处理呢?所有的异步任务,都会检查状态结果吗?为什么呢?
4 状态处理:结果返回
4.1 使用场景和案例
大部分的异步任务对于状态结果还是很关注的,比如:后续的处理逻辑或者任务依赖某个异步任务,或者异步任务非常重要,需要把结果返回给请求方。
案例 1:模板化创建服务的过程中,需要异步创建服务的 git 代码仓库,还要给仓库添加成员、webhook、初始化代码等。整个过程全部串行化作为一个任务的话,耗时会比较长。可以把创建服务的 git 代码仓库作为一个异步任务,然后得到成功的结果后再异步的发起添加成员、加 webhook、初始化代码等任务。同时,这里的 CI/CD 有配置相关,有执行相关,整个过程也很长,CD 部署成功之后才可以开启日志采集等配置,所以也需要关注 CD 部署的结果。
案例 2:各种 webhook、callback 接口和方法,就是基于回调的方式,如:golang 中的 channel 通知,工蜂中的代码 push 等 webhook,监控告警中的 callback 等。
案例 3:发布订阅模式,如引入消息队列服务,主程序把数据发送给消息队列,异步任务订阅相应的主题然后处理。处理完成后也可以把结果再发送给消息队列,或者把结果发送给主调程序的接口,或者等待主调程序来查询结果,当然也可能是上面的忽略结果的情况。
从上可以总结出来,对于异步任务的状态处理,需要关注结果的话,有两种主要的方法,分别是:轮询查询和等待回调。
4.2 方法 1:轮询查询
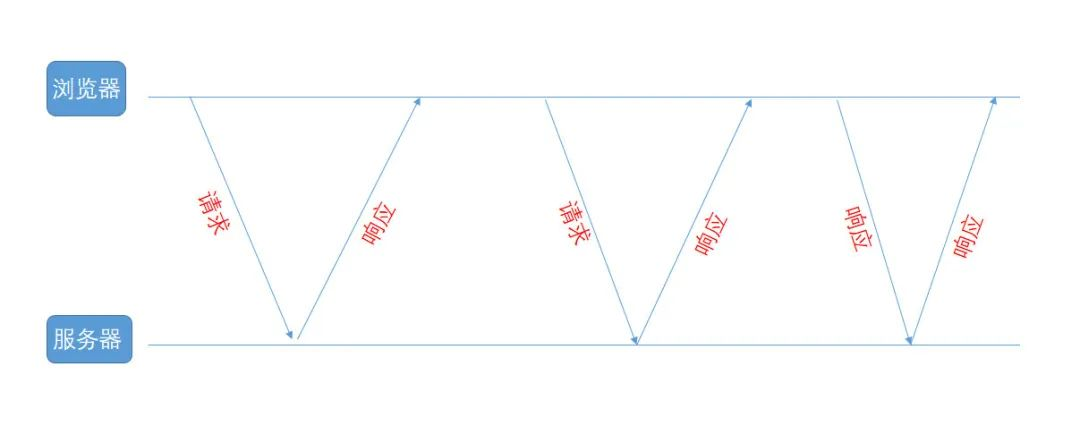
上面的案例 1 中,模板化创建服务的过程很慢,所以整个功能都是异步的,用户大概要等待 10s 左右才知道最后的结果。所以,用户在创建服务之后,浏览器会不断轮询服务端接口,看看创建服务的结果,各个步骤的处理结果,服务配置是否都成功完成了。
类似的功能实现应该有很多,比如:服务构建、部署、创建镜像仓库、抢购买票等,把任务执行和任务结果通过异步的方式强制分离开,用户可以等待,但是不用停留在当前任务中持续等待,而是可以去做别的事情,随时回来关注下这个任务的处理结果就好了。大部分执行时间很长的任务都会放到异步线程中执行,用户关注结果的话,就可以通过查询的方式来获取结果,程序自动来返回结果的话,就可以用到轮询查询了。
局限性 1:频率和实时性
轮询的方式延时可能会比较高,因为跟定时器的间隔时间有关系。
局限性 2:增加请求压力
因为轮询,要不断地请求服务端,所以对后端的请求压力也会比较大。
4.3 方法 2:通知回调
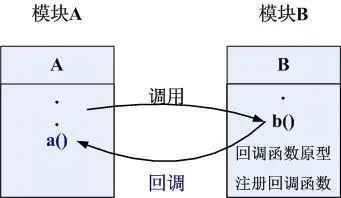
等待回调几乎是实时的,处理有结果返回就马上通过回调通知到主程序/用户,那么效率和体验上就会好很多。
但是这里也有一个前提要求,回调的时候,主程序必须还在运行,否则回调也就没有了主体,也就无效了。所以要求主程序需要持续等待异步任务的回调,不能过早的退出。
一般程序中使用异步任务,需要得到任务状态的结果,使用等待回调的情况更多一些。
特别注意 1:等待超时
等待的时间,一般不能是无限长,这样容易造成某些异常情况下的任务爆炸,内存泄露。所以需要对异步任务设置一个等待超时,过期后就要中断任务了,也就不能通过回调来得到结果了,直接认为是任务异常了。
特别注意 2:异常情况
当主程序在等待异步任务的回调时,如果异步任务自身有异常,无法成功执行,也无法完成回调的操作,那么主程序也就无法得到想要的结果,也不知道任务状态的结果是成功还是失败,这时候也就会遇到上面等待超时的情况了。
特别注意 3:回调地狱
使用 nodejs 异步编程的时候,所有的 io 操作都是异步回调,于是就很容易陷入 N 层的回调,代码就会变得异常丑陋和难以维护。于是就出现了很多的异步编程框架/模式,像:Promise,Generator,async/await 等。这里不做过多讲解。
4.4 思考问题
实际工作中,还有哪些地方需要处理异步任务的状态结果返回呢?除了轮询和回调,还有其他的方法吗?
5 异常处理
同步的程序,处理异常情况,在 java 中只需要一个 try catch 就可以捕获到全部的异常。
5.1 重点 1:分别做异常处理
异步的程序,try catch 只能捕获到当前主程序的异常,主程序中的异步线程是无法被捕获的。这时候,就需要针对异步线程中的异步任务也要单独进行 try catch 捕获异常。
在 golang 中,开启协程,还是需要在异步任务的 defer 方法中,加入一个 recover() ,以避免没有处理的异常导致整个进程的 panic。
5.2 重点 2:异常结果的记录,查询或者回调
当我们把异步任务中的异常情况都处理好了,不会导致异步线程把整个进程整奔溃了,那么还有问题,怎么把异常的结果返回给主进程。这就涉及到上面的状态处理了。
如果可以忽略结果,那么只需要写一下错误日志就好了。
如果需要处理状态,那就要记录下异常信息或者通知回调给到主进程。
5.3 思考问题
实际工作中,你会对所有的可能异常情况都做相应的处理吗?异常结果,都是怎么处理的呢?
6 典型场景和思考
前面已经讲到一些案例,总结下来的典型场景有如下几种
6.1 订阅发布模式,消息队列
6.2 慢请求,耗时长的任务
6.3 高并发、高性能要求时的多任务处理
6.4 不确定执行的时间点,触发器
人脑(单核)不擅长异步思考,电脑(多核)却更适合。
编程的时候,是人脑适配电脑,还是电脑服务人脑?
在大部分的编程中,大家都只需要考虑同步的方式来写代码逻辑。少部分时候,就要考虑使用异步的方式。而且,有很多的开发框架、类库已经把异步处理封装,可以简化异步任务的开发和调试工作。
所以,对于开发者来说,默认还是同步方式思考和开发,当不得不使用异步的时候,才会考虑异步的方式。毕竟让人脑适配电脑,这个过程还是有些困难的。
[原文https://mp.weixin.qq.com/s/C8OelR_O7DOBXpeUko_ETw]