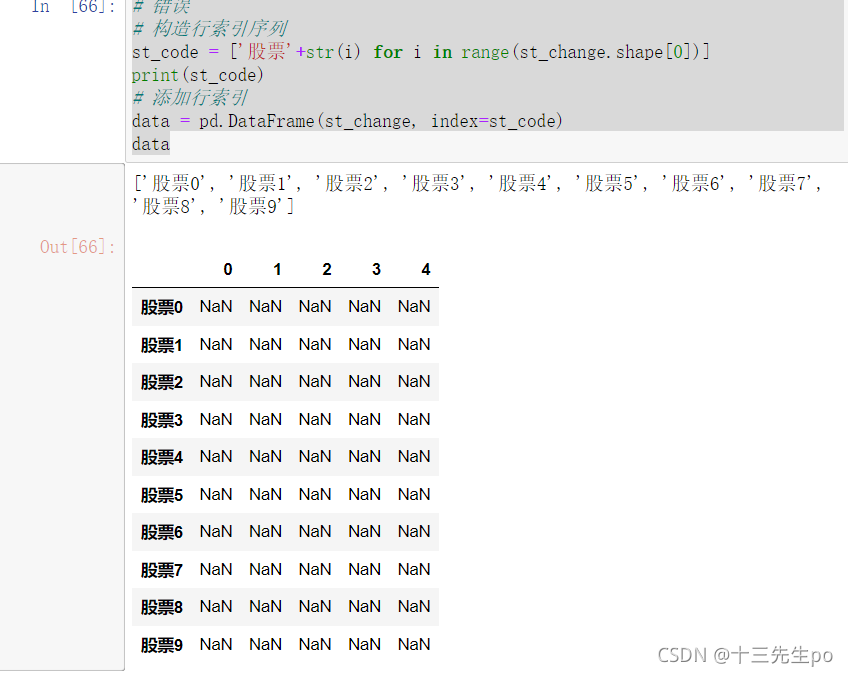
python使用pandas模块设置行列索引后单元数值全变Nan值
问题背景
使用pandas模块设置行列索引后单元数值全变Nan值
代码如下
# 错误
# 构造行索引序列
st_code = ['股票'+str(i) for i in range(st_change.shape[0])]
print(st_code)
# 添加行索引
data = pd.DataFrame(st_change, index=st_code)
data
解决问题
原因分析
这种写法可能不适用
正确写法:
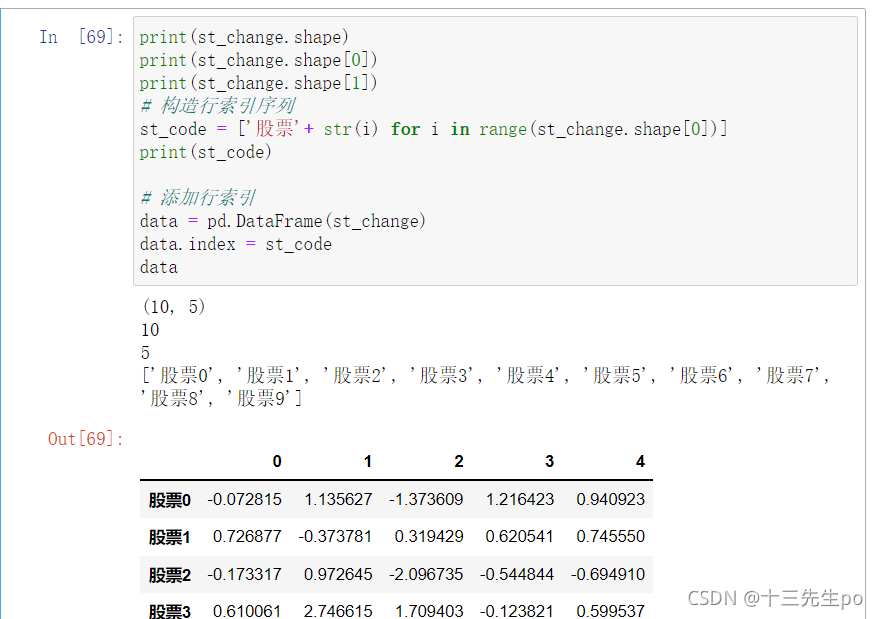
方法1:对dataframe结构的行索引index直接更改,有可能出问题,取决于赋什么值。以前这样做可以,现在不太推荐了
print(st_change.shape)
print(st_change.shape[0])
print(st_change.shape[1])
# 构造行索引序列
st_code = ['股票'+ str(i) for i in range(st_change.shape[0])]
print(st_code)
# 添加行索引
data = pd.DataFrame(st_change)
data.index = st_code
data
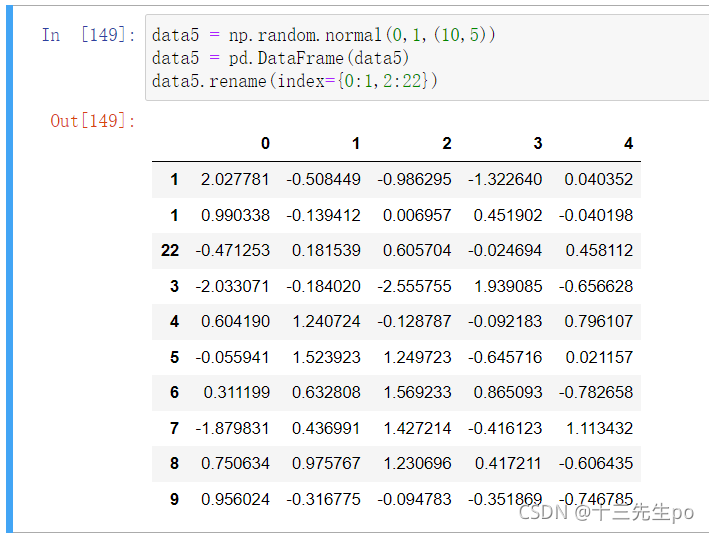
方法2:用rename方法改
df.rename(index={原行索引名:替换行索引名})
data5 = np.random.normal(0,1,(10,5))
data5 = pd.DataFrame(data5)
data5.rename(index={0:1,2:22})