Flink的异步I/O及Future和CompletableFuture
1 概述
Flink在做流数据计算时,经常要外部系统进行交互,如Redis、Hive、HBase等等存储系统。系统间通信延迟是否会拖慢整个Flink作业,影响整体吞吐量和实时性。
如需要查询外部数据库以关联上用户的额外信息,通常的实现方式是向数据库发送用户a的查询请求(如在MapFunction中),然后等待结果返回,返回之后才能进行下一次查询请求,这是一种同步访问的模式,如下图左边所示,网络等待时间极大的阻碍了吞吐和延迟。
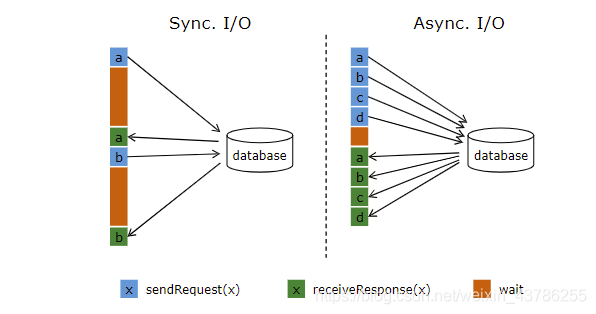
Flink从1.2版本开始就引入了Async I/O(https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/stream/operators/asyncio.html)。异步模式可以并发的处理多个请求和回复,也就是说,你可以连续的向数据库发送用户a、b、c、d等的请求,与此同时,哪个请求的回复先返回了就处理哪个回复,从而连续的请求之间不需要阻塞等待,如上图右边所示,这也是Async I/O的实现原理。
2 Future和CompletableFuture
先了解一下Future和CompletableFuture
2.1 Future
从JDK1.5开始,提供了Future来表示异步计算的结果,一般需要结合ExecutorService(执行者)和Callable(任务)来使用。Future的get方法是阻塞的
package com.quinto.flink;
import java.util.concurrent.*;
public class FutureTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 核心线程池大小5 最大线程池大小10 线程最大空闲时间60 时间单位s 线程等待队列
ThreadPoolExecutor executor = new ThreadPoolExecutor(5, 10, 60L, TimeUnit.SECONDS, new ArrayBlockingQueue<>(10));
Future<Long> future = executor.submit(() -> {
// 故意耗时
Thread.sleep(3000);
return System.currentTimeMillis();
});
System.out.println(future.get());
System.out.println("因为get是阻塞的,所以这个消息在数据之后输出");
executor.shutdown();
}
}
结果为
1612337847685
因为get是阻塞的,所以这个消息在数据之后输出
Future只是个接口,实际上返回的类是FutureTask:
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task);
execute(ftask);
return ftask;
}
protected <T> RunnableFuture<T> newTaskFor(Callable<T> callable) {
return new FutureTask<T>(callable);
}
FutureTask的get方法如下
private volatile int state;
private static final int NEW = 0;
private static final int COMPLETING = 1;
private static final int NORMAL = 2;
private static final int EXCEPTIONAL = 3;
private static final int CANCELLED = 4;
private static final int INTERRUPTING = 5;
private static final int INTERRUPTED = 6;
public V get() throws InterruptedException, ExecutionException {
int s = state;
// 首先判断FutureTask的状态是否为完成状态,如果是完成状态,说明已经执行过set或setException方法,返回report(s)。任务的运行状态。最初是NEW == 0。运行状态仅在set、setException和cancel方法中转换为终端状态。
if (s <= COMPLETING)
//如果get时,FutureTask的状态为未完成状态,则调用awaitDone方法进行阻塞
s = awaitDone(false, 0L);
return report(s);
}
/**
* awaitDone方法可以看成是不断轮询查看FutureTask的状态。在get阻塞期间:①如果执行get的线程被中断,则移除FutureTask的所有阻塞队列中的线程(waiters),并抛出中断异常;②如果FutureTask的状态转换为完成状态(正常完成或取消),则返回完成状态;③如果FutureTask的状态变为COMPLETING, 则说明正在set结果,此时让线程等一等;④如果FutureTask的状态为初始态NEW,则将当前线程加入到FutureTask的阻塞线程中去;⑤如果get方法没有设置超时时间,则阻塞当前调用get线程;如果设置了超时时间,则判断是否达到超时时间,如果到达,则移除FutureTask的所有阻塞列队中的线程,并返回此时FutureTask的状态,如果未到达时间,则在剩下的时间内继续阻塞当前线程。
*/
private int awaitDone(boolean timed, long nanos)
throws InterruptedException {
final long deadline = timed ? System.nanoTime() + nanos : 0L;
WaitNode q = null;
boolean queued = false;
for (;;) {
if (Thread.interrupted()) {
removeWaiter(q);
throw new InterruptedException();
}
int s = state;
if (s > COMPLETING) {
if (q != null)
q.thread = null;
return s;
}
else if (s == COMPLETING) // cannot time out yet
Thread.yield();
else if (q == null)
q = new WaitNode();
else if (!queued)
queued = UNSAFE.compareAndSwapObject(this, waitersOffset,
q.next = waiters, q);
else if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
removeWaiter(q);
return state;
}
LockSupport.parkNanos(this, nanos);
}
else
LockSupport.park(this);
}
}
Future的局限性:
①可以发现虽然 Future接口可以构建异步应用,但是对于结果的获取却是很不方便,只能通过阻塞或者轮询的方式得到任务的结果。阻塞的方式显然和我们的异步编程的初衷相违背,轮询的方式又会耗费无谓的 CPU 资源,而且也不能及时地得到计算结果。
②它很难直接表述多个Future 结果之间的依赖性。实际开发中,经常需要将多个异步计算的结果合并成一个,或者等待Future集合中的所有任务都完成,或者任务完成以后触发执行动作
2.2 CompletableFuture
JDk1.8引入了CompletableFuture,它实际上也是Future的实现类。这里可以得出:
CompletableFuture有一些新特性,能完成Future不能完成的工作。
public class CompletableFuture<T> implements Future<T>, CompletionStage<T> {
首先看类定义,实现了CompletionStage接口,这个接口是所有的新特性了。
对于CompletableFuture有四个执行异步任务的方法:
public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier)
public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier, Executor executor)
public static CompletableFuture<Void> runAsync(Runnable runnable)
public static CompletableFuture<Void> runAsync(Runnable runnable, Executor executor)
supply开头的带有返回值,run开头的无返回值。如果我们指定线程池,则会使用我么指定的线程池;如果没有指定线程池,默认使用ForkJoinPool.commonPool()作为线程池。
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 核心线程池大小5 最大线程池大小10 线程最大空闲时间60 时间单位s 线程等待队列
ThreadPoolExecutor executor = new ThreadPoolExecutor(5, 10, 60L, TimeUnit.SECONDS, new ArrayBlockingQueue<>(10));
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
return "hello";
}, executor);
System.out.println(future.get());
executor.shutdown();
}
上面只是对执行异步任务,如果要利用计算结果进一步处理使用,进行结果转换有如下方法:①thenApply (同步)②thenApplyAsync(异步)
// 同步转换
public <U> CompletableFuture<U> thenApply(Function<? super T,? extends U> fn)
// 异步转换,使用默认线程池
public <U> CompletableFuture<U> thenApplyAsync(Function<? super T,? extends U> fn)
// 异步转换,使用指定线程池
public <U> CompletableFuture<U> thenApplyAsync(Function<? super T,? extends U> fn, Executor executor)
package com.quinto.flink;
import java.util.concurrent.*;
public class FutureTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 核心线程池大小5 最大线程池大小10 线程最大空闲时间60 时间单位s 线程等待队列
ThreadPoolExecutor executor = new ThreadPoolExecutor(5, 10, 60L, TimeUnit.SECONDS, new ArrayBlockingQueue<>(10));
CompletableFuture<Long> future = CompletableFuture
// 执行异步任务
.supplyAsync(() -> {
return System.currentTimeMillis();
}, executor)
// 对前面的结果进行处理
.thenApply(n -> {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
Long time = System.currentTimeMillis();
System.out.println("如果是同步的,这条消息应该先输出");
return time-n;
});
System.out.println("等待2秒");
System.out.println(future.get());
executor.shutdown();
}
}
结果为
如果是同步的,这条消息应该先输出
等待2秒
2017
如果把thenApply换成thenApplyAsync,结果如下
等待2秒
如果是同步的,这条消息应该先输出
2008
处理完任务以及结果,该去消费了有如下方法:①thenAccept(能够拿到并利用执行结果) ② thenRun(不能够拿到并利用执行结果,只是单纯的执行其它任务)③thenAcceptBoth(能传入另一个stage,然后把另一个stage的结果和当前stage的结果作为参数去消费。)
public CompletableFuture<Void> thenAccept(Consumer<? super T> action)
public CompletableFuture<Void> thenAcceptAsync(Consumer<? super T> action)
public CompletableFuture<Void> thenAcceptAsync(Consumer<? super T> action, Executor executor)
public CompletableFuture<Void> thenRun(Runnable action)
public CompletableFuture<Void> thenRunAsync(Runnable action)
public CompletableFuture<Void> thenRunAsync(Runnable action, Executor executor)
public <U> CompletableFuture<Void> thenAcceptBoth(CompletionStage<? extends U> other, BiConsumer<? super T, ? super U> action)
public <U> CompletableFuture<Void> thenAcceptBothAsync(CompletionStage<? extends U> other, BiConsumer<? super T, ? super U> action)
public <U> CompletableFuture<Void> thenAcceptBothAsync(CompletionStage<? extends U> other, BiConsumer<? super T, ? super U> action, Executor executor)
如果要组合两个任务有如下方法:①thenCombine(至少两个方法参数,一个为其它stage,一个为用户自定义的处理函数,函数返回值为结果类型) ;② thenCompose(至少一个方法参数即处理函数,函数返回值为stage类型)
public <U,V> CompletionStage<V> thenCombine(CompletionStage<? extends U> other, BiFunction<? super T,? super U,? extends V> fn)
public <U,V> CompletionStage<V> thenCombineAsync(CompletionStage<? extends U> other, BiFunction<? super T,? super U,? extends V> fn)
public <U,V> CompletionStage<V> thenCombineAsync(CompletionStage<? extends U> other, BiFunction<? super T,? super U,? extends V> fn, Executor executor)
public <U> CompletionStage<U> thenCompose(Function<? super T, ? extends CompletionStage<U>> fn)
public <U> CompletionStage<U> thenComposeAsync(Function<? super T, ? extends CompletionStage<U>> fn)
public <U> CompletionStage<U> thenComposeAsync(Function<? super T, ? extends CompletionStage<U>> fn, Executor executor)
如果有多条渠道去完成同一种任务,选择最快的那个有如下方法:①applyToEither (有返回值)②acceptEither(没有返回值)
public <U> CompletionStage<U> applyToEither(CompletionStage<? extends T> other, Function<? super T, U> fn)
public <U> CompletionStage<U> applyToEitherAsync(CompletionStage<? extends T> other, Function<? super T, U> fn)
public <U> CompletionStage<U> applyToEitherAsync(CompletionStage<? extends T> other, Function<? super T, U> fn, Executor executor)
public CompletionStage<Void> acceptEither(CompletionStage<? extends T> other, Consumer<? super T> action)
public CompletionStage<Void> acceptEitherAsync(CompletionStage<? extends T> other, Consumer<? super T> action)
public CompletionStage<Void> acceptEitherAsync(CompletionStage<? extends T> other, Consumer<? super T> action, Executor executor)
Future和CompletableFuture对比:
Future:只能通过get方法或者死循环判断isDone来获取。异常情况不好处理。
CompletableFuture:只要设置好回调函数即可实现:①只要任务完成,就执行设置的函数,不用考虑什么时候任务完成②如果发生异常,会执行处理异常的函数③能应付复杂任务的处理,如果有复杂任务,比如依赖问题,组合问题等,同样可以写好处理函数来处理
3 使用Aysnc I/O的条件
(1)具有对外部系统进行异步IO访问的客户端API,如使用vertx,但是目前只支持scala 2.12的版本,可以使用java类库来做
(2)没有这样的客户端,可以通过创建多个客户端并使用线程池处理同步调用来尝试将同步客户端转变为有限的并发客户端,如可以写ExecutorService来实现。但是这种方法通常比适当的异步客户端效率低。
4 Aysnc I/O的案例
4.1 有外部系统进行异步IO访问的客户端API的方式
// 这个例子实现了异步请求和回调的Futures,具有Java8的Futures接口(与Flink的Futures相同)
class AsyncDatabaseRequest extends RichAsyncFunction<String, Tuple2<String, String>> {
// 定义连接客户端,并且不参与序列化
private transient DatabaseClient client;
@Override
public void open(Configuration parameters) throws Exception {
// 创建连接
client = new DatabaseClient(host, post, credentials);
}
@Override
public void close() throws Exception {
client.close();
}
@Override
public void asyncInvoke(String key, final ResultFuture<Tuple2<String, String>> resultFuture) throws Exception {
// 用连接进行查询,查询之后返回的是future,有可能有,有可能没有
final Future<String> result = client.query(key);
// 如果有结果返回的话会通知你(有个回调方法),这里可以设置超时时间,如果超过了一定的时间还没有返回相当于从这里取一取就会抛异常,结果就会返回null
CompletableFuture.supplyAsync(new Supplier<String>() {
@Override
public String get() {
try {
return result.get();
} catch (InterruptedException | ExecutionException e) {
// Normally handled explicitly.
return null;
}
}
//如果它已经执行完了,就会把结果放到Collections里面
}).thenAccept( (String dbResult) -> {
resultFuture.complete(Collections.singleton(new Tuple2<>(key, dbResult)));
});
}
}
// create the original stream
DataStream<String> stream = ...;
// unorderedWait这个是不在乎请求返回的顺序的,里面用到的是阻塞队列,队列满了会阻塞,队列里面一次最多可以有100个异步请求,超时时间是1000毫秒
DataStream<Tuple2<String, String>> resultStream =
AsyncDataStream.unorderedWait(stream, new AsyncDatabaseRequest(), 1000, TimeUnit.MILLISECONDS, 100);
4.2 没有外部系统进行异步IO访问的客户端API的方式
package com.quinto.flink;
import com.alibaba.druid.pool.DruidDataSource;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.async.ResultFuture;
import org.apache.flink.streaming.api.functions.async.RichAsyncFunction;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.Collections;
import java.util.concurrent.*;
import java.util.function.Supplier;
class AsyncDatabaseRequest extends RichAsyncFunction<String,String> {
// 这里用到了连接池,以前查询是阻塞的,查询完这个下一个还是同个连接,
// 现在要发送多个请求不能用同个连接,每个请求都会返回一个结果。这里不但要用到连接池,还要用到线程池。
private transient DruidDataSource druidDataSource;
private transient ExecutorService executorService;
@Override
public void open(Configuration parameters) throws Exception {
executorService = Executors.newFixedThreadPool(20);
druidDataSource = new DruidDataSource();
druidDataSource.setDriverClassName("com.mysql.jdbc.Driver");
druidDataSource.setUsername("root");
druidDataSource.setPassword("root");
druidDataSource.setUrl("jdbc:mysql:..localhost:3306/bigdata?characterEncoding=UTF-8");
druidDataSource.setInitialSize(5);
druidDataSource.setMinIdle(10);
druidDataSource.setMaxActive(20);
}
@Override
public void close() throws Exception {
druidDataSource.close();
executorService.shutdown();
}
@Override
public void asyncInvoke(String input,final ResultFuture<String> resultFuture) {
// 向线程池丢入一个线程
Future<String> future = executorService.submit(() -> {
String sql = "SELECT id,name FROM table WHERE id = ?";
String result = null;
Connection connection = null;
PreparedStatement stmt = null;
ResultSet rs = null;
try {
connection = druidDataSource.getConnection();
stmt = connection.prepareStatement(sql);
rs = stmt.executeQuery();
while (rs.next()){
result = rs.getString("name");
}
}finally {
if (rs!=null){
rs.close();
}
if (stmt!=null){
stmt.close();
}
if (connection!=null){
connection.close();
}
}
return result;
});
// 接收任务的处理结果,并消费处理,无返回结果。
CompletableFuture.supplyAsync(new Supplier<String>() {
@Override
public String get() {
try {
// 从future里面把结果取出来,如果有就返回,没有的话出异常就返回null
return future.get();
} catch (Exception e) {
return null;
}
}
// 拿到上一步的执行结果,进行处理
}).thenAccept((String result)->{
// 从future里面取出数据会有一个回调,然后会把他放到resultFuture,complete中要求放的是一个集合,所以需要进行转换
resultFuture.complete(Collections.singleton(result));
});
}
}
这样mysql的API还是用他原来的,只不过把mysql的查询使用把要查询的功能丢线程池。以前查询要好久才返回,现在来一个查询就丢到线程池里面,不需要等待结果,返回的结果放在future里面。原来查询是阻塞的,现在开启一个线程查,把查询结果丢到future里面。相当于新开一个线程让他帮我查,原来是单线程的,现在开多个线程同时查,然后把结果放future,以后有结果了从这里面取。