Docker技术原理
一、Docker架构
Docker包括三个基本概念:
- 镜像(Image): Docker 镜像(Image),就相当于是一个 root 文件系统。比如官方镜像 ubuntu:16.04 就包含了完整的一套 Ubuntu16.04 最小系统的 root 文件系统。
- 容器(Container):镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的类和实例一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等。
- 仓库(Repository):仓库可看成一个代码控制中心,用来保存镜像。
Docker 容器通过 Docker 镜像来创建,容器与镜像的关系类似于面向对象编程中的对象与类。
Docker 使用客户端-服务器 (C/S) 架构模式,使用远程API来管理和创建Docker容器。TestContainer就是通过Docker Engine的API来创建和操作容器的。Docker架构模式结构如下图所示:
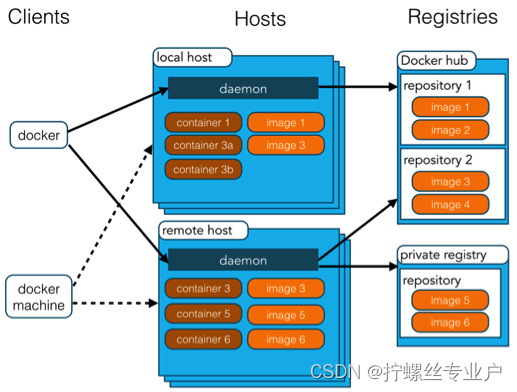
下表介绍了架构模式图中涉及到的概念:
| 概念 | 说明 |
|---|---|
| Docker 镜像(Images) | Docker 镜像是用于创建 Docker 容器的模板,比如 Ubuntu 系统。 |
| Docker 容器(Container) | 容器是独立运行的一个或一组应用,是镜像运行时的实体。 |
| Docker 客户端(Client) | Docker 客户端通过命令行或者其他工具使用 Docker SDK (https://docs.docker.com/develop/sdk/) 与 Docker 的守护进程通信。 |
| Docker 主机(Host) | 一个物理或者虚拟的机器用于执行 Docker 守护进程和容器。 |
| Docker Registry | Docker 仓库用来保存镜像,可以理解为代码控制中的代码仓库。Docker Hub(https://hub.docker.com) 提供了庞大的镜像集合供使用。一个 Docker Registry 中可以包含多个仓库(Repository);每个仓库可以包含多个标签(Tag);每个标签对应一个镜像。通常,一个仓库会包含同一个软件不同版本的镜像,而标签就常用于对应该软件的各个版本。我们可以通过 <仓库名>:<标签> 的格式来指定具体是这个软件哪个版本的镜像。如果不给出标签,将以 latest 作为默认标签。 |
| Docker Machine | Docker Machine是一个简化Docker安装的命令行工具,通过一个简单的命令行即可在相应的平台上安装Docker,比如VirtualBox、 Digital Ocean、Microsoft Azure。 |
二、Docker 镜像
我们都知道,操作系统分为 内核 和 用户空间。对于 Linux 而言,内核启动后,会挂载 root文件系统为其提供用户空间支持。而 Docker 镜像(Image),就相当于是一个 root文件系统。比如官方镜像 ubuntu:18.04 就包含了完整的一套 Ubuntu 18.04 最小系统的 root 文件系统。
Docker 镜像 是一个特殊的文件系统,除了提供容器运行时所需的程序、库、资源、配置等文件外,还包含了一些为运行时准备的一些配置参数(如匿名卷、环境变量、用户等)。镜像 不包含 任何动态数据,其内容在构建之后也不会被改变。
rootfs 根文件系统
Linux文件系统
文件系统是os用来明确存储设备(常见的是磁盘,也有基于NAND Flash的固态硬盘)或分区上的文件的方法和数据结构;即在存储设备上组织文件的方法。操作系统中负责管理和存储文件信息的软件机构称为文件管理系统,简称文件系统。
文件系统由三部分组成:文件系统的接口,对对象操作和管理的软件集合,对象及属性。从系统角度来看,文件系统是对文件存储设备的空间进行组织和分配,负责文件存储并对存入的文件进行保护和检索的系统。具体地说,它负责为用户建立文件,存入、读出、修改、转储文件,控制文件的存取,当用户不再使用时撤销文件等。
尽管内核是linux的核心,但文件却是用户与操作系统交互所采用的主要工具。这对linux来说尤其如此,这是因为在UNIX传统中,它使用文件I/O机制管理硬件设备和数据文件。
根文件系统
根文件系统首先是内核启动时所mount的第一个文件系统,内核代码映像文件保存在根文件系统中,而系统引导启动程序会在根文件系统挂载之后从中把一些基本的初始化脚本和服务等加载到内存中去运行。
根文件系统首先是一种文件系统,该文件系统不仅具有普通文件系统的存储数据文件的功能,但相对于普通的文件系统,它是内核启动时挂载(mount)的第一个文件系统,内核代码的映像文件保存在根文件系统中,系统引导启动程序会在根文件系统挂载之后从中把一些初始化脚本(如rcS,inittab)和服务加载到内存中去运行。 文件系统和内核是完全独立的两个部分。在嵌入式中移植的内核下载到开发板上,是没有办法真正的启动Linux操作系统的,会出现无法加载文件系统的错误。
根文件系统为什么重要?
根文件系统之所以在前面加一个”根“,说明它是加载其它文件系统的”根“,那么如果没有这个根,其它的文件系统也就没有办法进行加载的。
根文件系统包含系统启动时所必须的目录和关键性的文件,以及使其他文件系统得以挂载(mount)所必要的文件。例如:
- init进程的应用程序必须运行在根文件系统上;
- 根文件系统提供了根目录“/”;
- linux挂载分区时所依赖的信息存放于根文件系统/etc/fstab这个文件中;
- shell命令程序必须运行在根文件系统上,譬如ls、cd等命令;
总之:一套linux体系,只有内核本身是不能工作的,必须要rootfs(上的etc目录下的配置文件、/bin /sbin等目录下的shell命令,还有/lib目录下的库文件等···)相配合才能工作。
Linux启动时,第一个必须挂载的是根文件系统;若系统不能从指定设备上挂载根文件系统,则系统会出错而退出启动。成功之后可以自动或手动挂载其他的文件系统。
Linux内核是怎么挂载根文件系统的?
init/main.c->
start_kernel()->vfs_caches_init(totalram_pages)–>
mnt_init()–>
/* sysfs用来记录和展示linux驱动模型,sysfs先于rootfs挂载是为全面展示linux驱动模型做好准备 */
/* mnt_init()调用sysfs_init()注册并挂载sysfs文件系统,调用kobject_create_and_add()创建fs目录 */
sysfs_init();
/* init_rootfs()注册rootfs,然后调用init_mount_tree()挂载rootfs */
init_rootfs();
init_mount_tree();
1、sysfs文件系统目前还没有挂载到rootfs的某个挂载点上,后续init程序会把sysfs挂载到rootfs的sys挂载点上;
2、rootfs是基于内存的文件系统,所有操作都在内存中完成;也没有实际的存储设备,所以不需要设备驱动程序的参与。基于以上原因,linux在启动阶段使用rootfs文件系统,当磁盘驱动程序和磁盘文件系统成功加载后,linux系统会将系统根目录从rootfs切换到磁盘文件系统。
start_kernel
vfs_caches_init
mnt_init
init_rootfs注册rootfs文件系统
init_mount_tree 挂载rootfs文件系统
vfs_kern_mount
mount_fs
type->mount其实是rootfs_mount
mount_nodev
fill_super 其实是ramfs_fill_super
inode =ramfs_get_inode(sb, NULL, S_IFDIR | fsi->mount_opts.mode, 0);
sb->s_root = d_make_root(inode);
// 设置根目录的名字为“/”;
static const struct qstr name = QSTR_INIT(“/”, 1);[1*]
__d_alloc(root_inode->i_sb, &name);
…
mnt->mnt.mnt_root = root;[2*] // 设置vfsmount中的root目录
mnt->mnt.mnt_sb = root->d_sb;[3*] // 设置vfsmount中的超级块
mnt->mnt_mountpoint = mnt->mnt.mnt_root;[4*] // 设置vfsmount中文件挂载点指向了自己
mnt->mnt_parent = mnt;[5*] // 设置vfsmount中的父文件系统的vfsmount为自己;
root.mnt = mnt;
root.dentry = mnt->mnt_root;
mnt->mnt_flags |= MNT_LOCKED;
set_fs_pwd(current->fs, &root);
set_fs_root(current->fs, &root);
…
rest_init
kernel_thread(kernel_init, NULL, CLONE_FS);
在执行kernel_init之前,会建立roofs文件系统。
[1*]处设置了根目录的名字为“/”;
[2*]处设置了vfsmount中的root目录;
[3*]处设置了vfsmount中的超级块;
[4*]处设置了vfsmount中的文件挂载点,指向了自己;
[5*]处设置了vfsmount中的父文件系统的vfsmount为自己;
根文件系统各个常用目录简介
正常来说,根文件系统至少包括以下目录:
- /etc/:存储重要的配置文件。
- /bin/:存储常用且开机时必须用到的执行文件。
- /sbin/:存储着开机过程中所需的系统执行文件。
- /lib/:存储/bin/及/sbin/的执行文件所需的链接库,以及Linux的内核模块。
- /dev/:存储设备文件。
五大目录必须存储在根文件系统上,缺一不可。
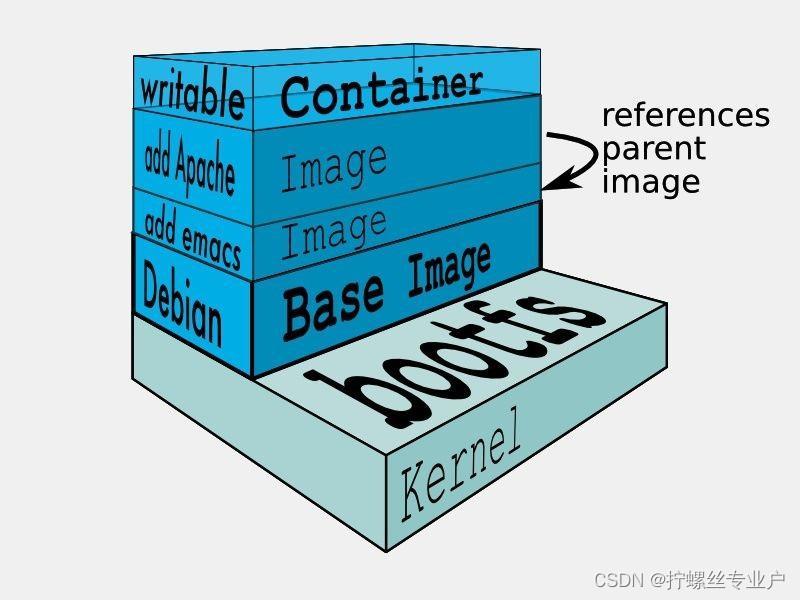
分层存储
因为镜像包含操作系统完整的 root 文件系统,其体积往往是庞大的,因此在 Docker 设计时,就充分利用 Union FS 的技术,将其设计为分层存储的架构。所以严格来说,镜像并非是像一个 ISO 那样的打包文件,镜像只是一个虚拟的概念,其实际体现并非由一个文件组成,而是由一组文件系统组成,或者说,由多层文件系统联合组成。
镜像构建时,会一层层构建,前一层是后一层的基础。每一层构建完就不会再发生改变,后一层上的任何改变只发生在自己这一层。比如,删除前一层文件的操作,实际不是真的删除前一层的文件,而是仅在当前层标记为该文件已删除。在最终容器运行的时候,虽然不会看到这个文件,但是实际上该文件会一直跟随镜像。因此,在构建镜像的时候,需要额外小心,每一层尽量只包含该层需要添加的东西,任何额外的东西应该在该层构建结束前清理掉。
分层存储的特征还使得镜像的复用、定制变的更为容易。甚至可以用之前构建好的镜像作为基础层,然后进一步添加新的层,以定制自己所需的内容,构建新的镜像。
下面使用redis镜像来实际查看一下镜像分层存储。执行下面的镜像分析命令:
$ docker image inspect redis
......
"RootFS": {
"Type": "layers",
"Layers": [
"sha256:2edcec3590a4ec7f40cf0743c15d78fb39d8326bc029073b41ef9727da6c851f",
"sha256:9b24afeb7c2f21e50a686ead025823cd2c6e9730c013ca77ad5f115c079b57cb",
"sha256:4b8e2801e0f956a4220c32e2c8b0a590e6f9bd2420ec65453685246b82766ea1",
"sha256:529cdb636f61e95ab91a62a51526a84fd7314d6aab0d414040796150b4522372",
"sha256:9975392591f2777d6bf4d9919ad1b2c9afa12f9a9b4d260f45025ec3cc9b18ed",
"sha256:8e5669d8329116b8444b9bbb1663dda568ede12d3dbcce950199b582f6e94952"
]
},
可以看到Layers里面的内容就是具体包含的层。这些层数据存储的位置和其他信息就在上面输出的"GraphDriver"项里面:
"GraphDriver": {
"Data": {
"LowerDir": "/var/lib/docker/overlay2/6d1f6b0b1bedea3ba9db/diff",
"MergedDir": "/var/lib/docker/overlay2/6d1f6b0b1bedea3ba9db/merged",
"UpperDir": "/var/lib/docker/overlay2/6d1f6b0b1bedea3ba9db/diff",
"WorkDir": "/var/lib/docker/overlay2/6d1f6b0b1bedea3ba9db/work"
},
"Name": "overlay2"
},
我们可以看到这里面存储的就是联合文件系统相关项的信息了。
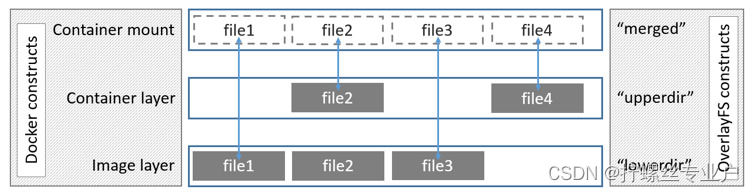
Union FS (联合文件系统)
联合文件系统(UnionFS)是一种分层、轻量级并且高性能的文件系统,它支持对文件系统的修改作为一次提交来一层层的叠加,同时可以将不同目录挂载到同一个虚拟文件系统下(unite several directories into a single virtual filesystem)。
UnionFS的联合挂载技术可以在一个挂载点同时挂载多个文件系统,将挂载点的原目录与被挂载内容进行整合,使得最终可见的文件系统将会包含整合之后的各层的文件和目录。
联合文件系统是 Docker 镜像的基础。镜像可以通过分层来进行继承,基于基础镜像(没有父镜像),可以制作各种具体的应用镜像。
另外,不同 Docker 容器就可以共享一些基础的文件系统层,同时再加上自己独有的改动层,大大提高了存储的效率。
Docker 中使用的 AUFS(Advanced Multi-Layered Unification Filesystem)就是一种联合文件系统。 AUFS 支持为每一个成员目录(类似 Git 的分支)设定只读(readonly)、读写(readwrite)和写出(whiteout-able)权限, 同时 AUFS 里有一个类似分层的概念, 对只读权限的分支可以逻辑上进行增量地修改(不影响只读部分的)。
Docker 目前支持的联合文件系统包括 OverlayFS, AUFS, Btrfs, VFS, ZFS 和 Device Mapper。
下面Centos发行版的overlayFS联合文件系统示意图:
Dockerfile
镜像的定制实际上就是定制每一层所添加的配置、文件。如果我们可以把每一层修改、安装、构建、操作的命令都写入一个脚本,用这个脚本来构建、定制镜像,那么无法重复的问题、镜像构建透明性的问题、体积的问题就都会解决。这个脚本就是 Dockerfile。
Dockerfile 是一个文本文件,其内包含了一条条的 指令(Instruction),每一条指令构建一层,因此每一条指令的内容,就是描述该层应当如何构建。
下面以定制nginx镜像为例,演示Dockerfile使用过程:
在一个空白目录中,建立一个文本文件,并命名为 Dockerfile:
$ mkdir mynginx
$ cd mynginx
$ touch Dockerfile
其内容为:
FROM nginx
RUN echo '<h1>Hello, Docker!</h1>' > /usr/share/nginx/html/index.html
这个 Dockerfile 很简单,一共就两行。涉及到了两条指令,FROM 和 RUN。
三、Docker 容器
镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的 类 和 实例 一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等。
容器的实质是进程,但与直接在宿主执行的进程不同,容器进程运行于属于自己的独立的 命名空间。因此容器可以拥有自己的 root 文件系统、自己的网络配置、自己的进程空间,甚至自己的用户 ID 空间。容器内的进程是运行在一个隔离的环境里,使用起来,就好像是在一个独立于宿主的系统下操作一样。这种特性使得容器封装的应用比直接在宿主运行更加安全。也因为这种隔离的特性,很多人初学 Docker 时常常会混淆容器和虚拟机。
前面讲过镜像使用的是分层存储,容器也是如此。每一个容器运行时,是以镜像为基础层,在其上创建一个当前容器的存储层,我们可以称这个为容器运行时读写而准备的存储层为 容器存储层。
容器存储层的生存周期和容器一样,容器消亡时,容器存储层也随之消亡。因此,任何保存于容器存储层的信息都会随容器删除而丢失。
按照 Docker 最佳实践的要求,容器不应该向其存储层内写入任何数据,容器存储层要保持无状态化。所有的文件写入操作,都应该使用 数据卷(Volume)、或者 绑定宿主目录,在这些位置的读写会跳过容器存储层,直接对宿主(或网络存储)发生读写,其性能和稳定性更高。
数据卷的生存周期独立于容器,容器消亡,数据卷不会消亡。因此,使用数据卷后,容器删除或者重新运行之后,数据却不会丢失。
命名空间
Namespace(命名空间)是Linux内核的一项功能,该功能对内核资源进行分区,使一组进程看到一组资源,而另一组进程看到另一组资源,就好像运行在单独的操作系统中一样。Namespace有很多种,包括下表中列出的7种。
| 名称 | 隔离的资源 |
|---|---|
| IPC | SystemV IPC(信号量, 消息队列和共享内存) 和 POSIX message queues |
| Network | 网络设备, 网络栈, 端口等 |
| Mount | 文件挂载点 |
| PID | 进程编号 |
| User | User & Group IDs |
| UTS | 主机名和NIS域名 |
| Cgroup | cgroup的根目录 |
比较重要的是network,mount和PID namespace。
每个容器都有自己单独的命名空间,运行在其中的应用都像是在独立的操作系统中运行一样。命名空间保证了容器之间彼此互不影响。
控制组
Cgroups 是 control groups 的缩写,是Linux内核提供的一种可以限制,记录,隔离进程组(process groups)所使用物理资源的机制。主要功能有:资源限制(Resource limiting),优先级分配(Prioritization),资源统计(Accounting),进程控制(Control)等。只有能控制分配到容器的资源,才能避免当多个容器同时运行时的对系统资源的竞争。
- 资源限制(Resource limiting): Cgroups可以对进程组使用的资源总额进行限制。如对特定的进程进行内存使用上限限制,当超出上限时,会触发OOM。
- 优先级分配(Prioritization): 通过分配的CPU时间片数量及硬盘IO带宽大小,实际上就相当于控制了进程运行的优先级。
- 资源统计(Accounting): Cgroups可以统计系统的资源使用量,如CPU使用时长、内存用量等等,这个功能非常适用于计费。
- 进程控制(Control):Cgroups可以对进程组执行挂起、恢复等操作。
容器的存储组织方式
综合考虑镜像的层级结构,以及 volume、init-layer、可读写层这些概念,一个完整的、在运行的容器的所有文件系统结构可如下图所示:
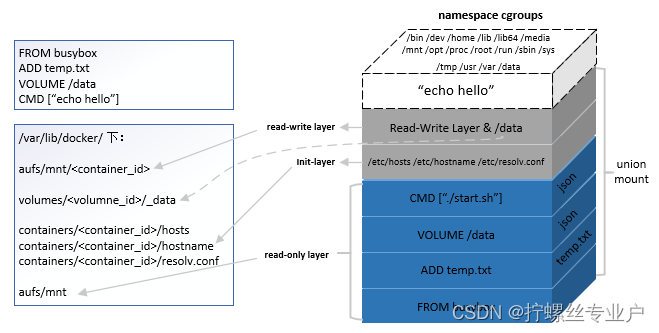
从图中我们不难看到,除了 echo hello 进程所在的 cgroups 和 namespace 环境之外,容器文件系统其实是一个相对独立的组织。可读写部分(read-write layer 以及 volumes)、init-layer、只读层(read-only layer) 这 3 部分结构共同组成了一个容器所需的下层文件系统,它们通过联合挂载的方式巧妙地表现为一层,使得容器进程对这些层的存在一无所知。
rootfs 是 docker 容器在启动时内部进程可见的文件系统,即 docker 容器的根目录。当我们运行docker exec命令进入container的时候看到的文件系统就是rootfs。rootfs 通常包含一个操作系统运行所需的文件系统,例如可能包含典型的类 Unix 操作系统中的目录系统,如 /dev、/proc、/bin、/etc、/lib、/usr、/tmp 及运行 docker 容器所需的配置文件、工具等。
就像Linux启动会先用只读模式挂载rootfs,运行完完整性检查之后,再切换成读写模式一样。Docker deamon为container挂载rootfs时,也会先挂载为只读模式,但是与Linux做法不同的是,在挂载完只读的rootfs之后,docker deamon会利用联合挂载技术(Union Mount)在已有的rootfs上再挂一个读写层。container在运行过程中文件系统发生的变化只会写到读写层,并通过whiteout技术隐藏只读层中的旧版本文件。
容器的rootfs分为三个部分: 读写层(rw)、init层(ro+wh)、只读层(ro+wh)
只读层对于的docker的镜像层, 这部分不可被修改.
init层它是一个以“-init”结尾的层,夹在只读层和读写层之间。Init 层是 Docker 项目单独生成的一个内部层,专门用来存放 /etc/hosts、/etc/resolv.conf 等信息.
读写层是 rootfs 最上面的一层,它的挂载方式为:rw,即 read write。在没有写入文件之前,这个目录是空的。而一旦在容器里做了写操作,你修改产生的内容就会以增量的方式出现在这个层中。 删除文件的话 ,AuFS 会在可读写层创建一个 whiteout 文件,把只读层里的文件“遮挡”起来。比如,你要删除只读层里一个名叫 foo 的文件,那么这个删除操作实际上是在可读写层创建了一个名叫.wh.foo 的文件。这样,当这两个层被联合挂载之后,foo 文件就会被.wh.foo 文件“遮挡”起来,“消失”了。这个功能,就是“ro+wh”的挂载方式,即只读 +whiteout 的含义
容器存储层
容器存储层会存储容器运行过程中产生的所有改变,对应到上边讲的rootfs的读写层。因为这一层是运行中容器与源Docker镜像唯一的不同,因此由同一个镜像创建的任意数量容器都可以共享相同的底层镜像,并且同时可以维持他们自己的独立状态。
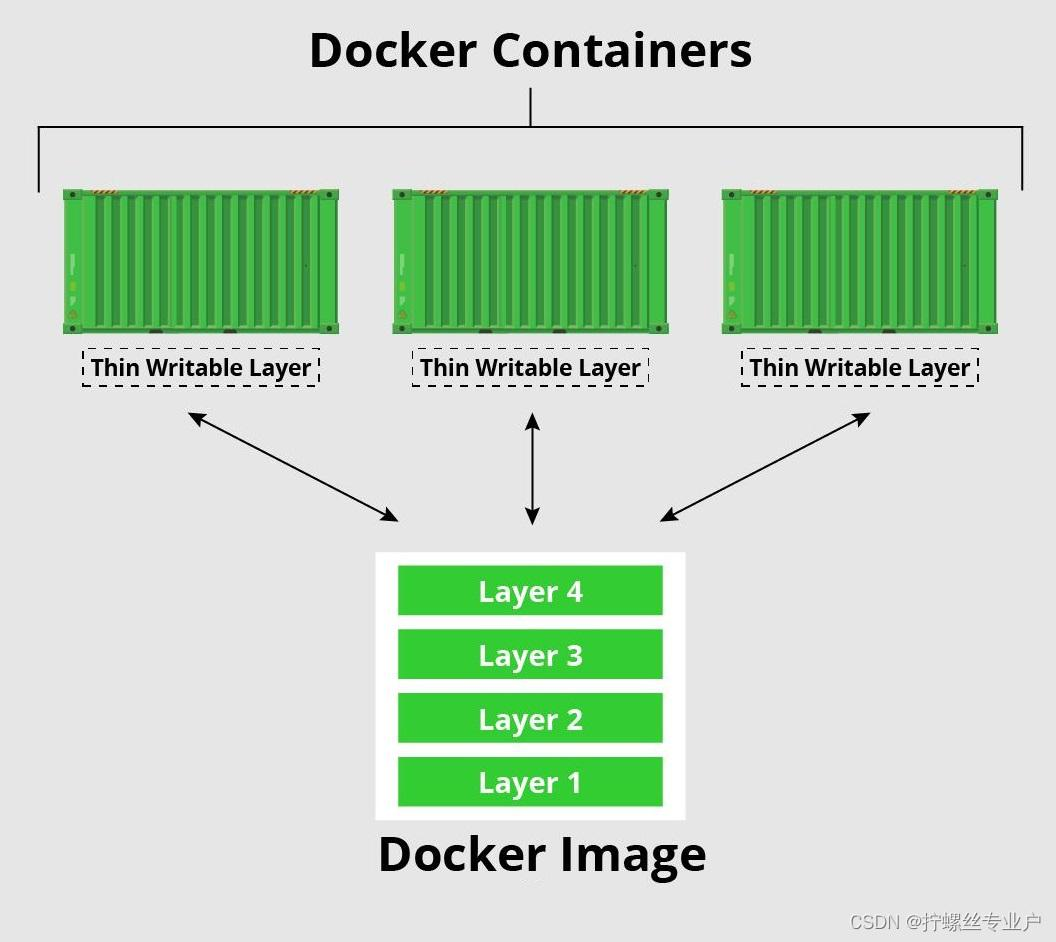
数据卷的实现原理
Volume 挂载
容器技术使用了 rootfs 机制和 Mount Namespace,构建出了一个同宿主机完全隔离开的文件系统环境。这时候,我们就需要考虑这样两个问题:
- 容器里进程新建的文件,怎么才能让宿主机获取到?
- 宿主机上的文件和目录,怎么才能让容器里的进程访问到?
这正是 Docker Volume 要解决的问题:Volume 机制,允许你将宿主机上指定的目录或者文件,挂载到容器里面进行读取和修改操作。
在 Docker 项目里,它支持两种 Volume 声明方式,可以把宿主机目录挂载进容器的 /test 目录当中:
$ docker run -v /test ...
$ docker run -v /home:/test ...
而这两种声明方式的本质,实际上是相同的:都是把一个宿主机的目录挂载进了容器的 /test 目录。
只不过,在第一种情况下,由于你并没有显示声明宿主机目录,那么 Docker 就会默认在宿主机上创建一个临时目录 /var/lib/docker/volumes/[VOLUME_ID]/_data,然后把它挂载到容器的 /test 目录上。而在第二种情况下,Docker 就直接把宿主机的 /home 目录挂载到容器的 /test 目录上.
绑定挂载
那么,Docker 又是如何做到把一个宿主机上的目录或者文件,挂载到容器里面去呢?
当容器进程被创建之后,尽管开启了 Mount Namespace,但是在它执行 chroot(或者 pivot_root)之前,容器进程一直可以看到宿主机上的整个文件系统。
而宿主机上的文件系统,也自然包括了我们要使用的容器镜像。这个镜像的各个层,保存在 /var/lib/docker/aufs/diff 目录下,在容器进程启动后,它们会被联合挂载在 /var/lib/docker/aufs/mnt/ 目录中,这样容器所需的 rootfs 就准备好了。
所以,我们只需要在 rootfs 准备好之后,在执行 chroot 之前,把 Volume 指定的宿主机目录(比如 /home 目录),挂载到指定的容器目录(比如 /test 目录)在宿主机上对应的目录(即 /var/lib/docker/aufs/mnt/[可读写层 ID]/test)上,这个 Volume 的挂载工作就完成了。
更重要的是,由于执行这个挂载操作时,“容器进程”已经创建了,也就意味着此时 Mount Namespace 已经开启了。所以,这个挂载事件只在这个容器里可见。你在宿主机上,是看不见容器内部的这个挂载点的。这就保证了容器的隔离性不会被 Volume 打破。
注意:这里提到的 " 容器进程 ",是 Docker 创建的一个容器初始化进程 (dockerinit),而不是应用进程 (ENTRYPOINT + CMD)。dockerinit 会负责完成根目录的准备、挂载设备和目录、配置 hostname 等一系列需要在容器内进行的初始化操作。最后,它通过 execv() 系统调用,让应用进程取代自己,成为容器里的 PID=1 的进程。
而这里要使用到的挂载技术,就是 Linux 的绑定挂载(bind mount)机制,对应的Linux命令为mount --bind olddir newdir。它的主要作用就是,允许你将一个目录或者文件,而不是整个设备,挂载到一个指定的目录上。并且,这时你在该挂载点上进行的任何操作,只是发生在被挂载的目录或者文件上,而原挂载点的内容则会被隐藏起来且不受影响。
其实,如果你了解 Linux 内核的话,就会明白,绑定挂载实际上是一个 inode 替换的过程。在 Linux 操作系统中,inode 可以理解为存放文件内容的“对象”,而 dentry,也叫目录项,就是访问这个 inode 所使用的“指针”。

正如上图所示,mount --bind /home /test,会将 /home 挂载到 /test 上。其实相当于将 /test 的 dentry,重定向到了 /home 的 inode。这样当我们修改 /test 目录时,实际修改的是 /home 目录的 inode。这也就是为何,一旦执行 umount 命令,/test 目录原先的内容就会恢复:因为修改真正发生在的,是 /home 目录里。
所以,在一个正确的时机,进行一次绑定挂载,Docker 就可以成功地将一个宿主机上的目录或文件,不动声色地挂载到容器中。
这样,进程在容器里对这个 /test 目录进行的所有操作,都实际发生在宿主机的对应目录(比如,/home,或者 /var/lib/docker/volumes/[VOLUME_ID]/_data)里,而不会影响容器镜像的内容。
那么,这个 /test 目录里的内容,既然挂载在容器 rootfs 的可读写层,它会不会被 docker commit 提交掉呢?
也不会。因为容器的镜像操作,比如 docker commit,都是发生在宿主机空间的,而由于 Mount Namespace 的隔离作用,宿主机并不知道这个绑定挂载的存在。所以,在宿主机看来,容器中可读写层的 /test 目录(/var/lib/docker/aufs/mnt/[可读写层 ID]/test),始终是空的。
不过,由于 Docker 一开始还是要创建 /test 这个目录作为挂载点,所以执行了 docker commit 之后,你会发现新产生的镜像里,会多出来一个空的 /test 目录。毕竟,新建目录操作,又不是挂载操作,Mount Namespace 对它可起不到“障眼法”的作用。
容器网络
Docker在安装后自动提供4种网络,可以使用Docker network ls命令查看:
[root@localhost ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
0cfebacda74b bridge bridge local
322c4224124b host host local
c69dc8eed0ec none null local
Docker使用Linux桥接,在宿主机虚拟一个Docker容器网桥(docker0),Docker启动一个容器时会根据Docker网桥的网段分配给容器一个IP地址,称为Container-IP,同时Docker网桥是每个容器的默认网关。因为在同一宿主机内的容器都接入同一个网桥,这样容器之间就能够通过容器的Container-IP直接通信。
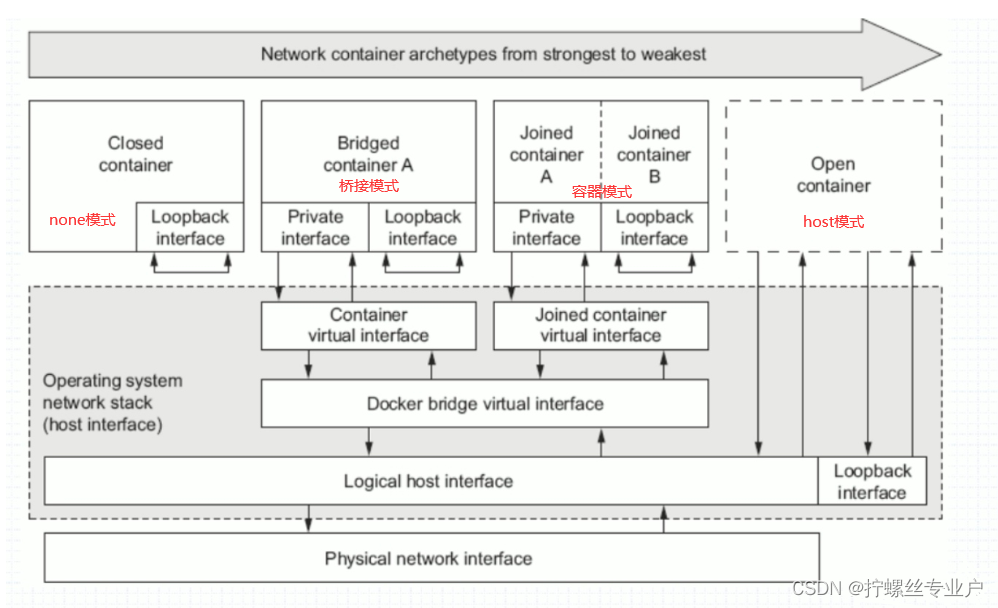
docker的4种网络模式
| 网络模式 | 配置 | 说明 |
|---|---|---|
| host | –network host | 容器和宿主机共享Network namespace |
| container | –network container:NAME_OR_ID | 容器和另外一个容器共享Network namespace |
| none | –network none | 容器有独立的Network namespace, namespace, 但并没有对其进行任何网络设置, 如分配veth pair 和网桥连接, |
| bridge | –network bridge | 默认模式 |
下面是4种网络模式的示意图:
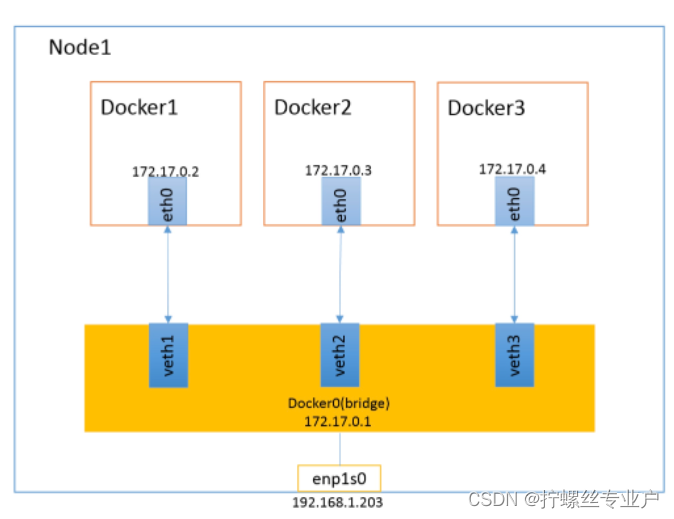
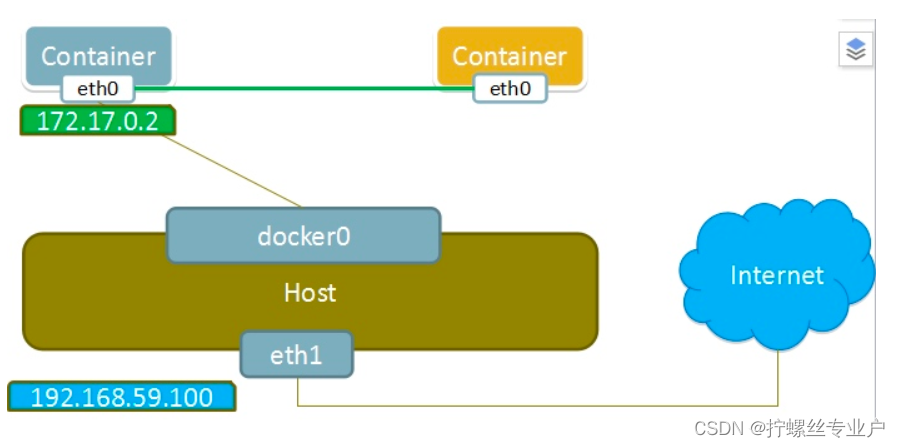
bridge模式
当Docker进程启动时,会在主机上创建一个名为docker0的虚拟网桥,此主机上启动的Docker容器会连接到这个虚拟网桥上。虚拟网桥的工作方式和物理交换机类似,这样主机上的所有容器就通过交换机连在了一个二层网络中。
从docker0子网中分配一个IP给容器使用,并设置docker0的IP地址为容器的默认网关。在主机上创建一对虚拟网卡veth pair设备,Docker将veth pair设备的一端放在新创建的容器中,并命名为eth0(容器的网卡),另一端放在主机中,以vethxxx这样类似的名字命名,并将这个网络设备加入到docker0网桥中。可以通过brctl show命令查看。
bridge模式是docker的默认网络模式,不写–network参数,就是bridge模式。使用docker run -p时,docker实际是在iptables做了DNAT规则,实现端口转发功能。可以使用iptables -t nat -vnL查看。
bridge模式如下图所示:
假设上图的docker2中运行了一个nginx,大家来想几个问题:
- 同主机间两个容器间是否可以直接通信?比如在docker1上能不能直接访问到docker2的nginx站点?答:可以。
- 在宿主机上能否直接访问到docker2的nginx站点?答:不能直接访问,需要端口映射或者配置iptables转发规则。
- 在另一台主机上如何访问node1上的这个nginx站点呢?DNAT发布?答:为node1上的nginx容器配置端口映射。
Docker网桥是宿主机虚拟出来的,并不是真实存在的网络设备,外部网络是无法寻址到的,这也意味着外部网络无法通过直接Container-IP访问到容器。如果容器希望外部访问能够访问到,可以通过映射容器端口到宿主主机(端口映射),即docker run创建容器时候通过 -p 或 -P 参数来启用,访问容器的时候就通过[宿主机IP]:[容器端口]访问容器。
端口映射
在上文中提到了,在Docker网桥模式下,虚拟网桥Docker0不是一个实际的物理网卡,所以外部网络是访问不到容器IP地址的,外部网络要想访问到容器里面就得做端口映射。端口映射实际是在iptables做了DNAT规则,实现端口转发功能。下面我们就详细看下端口映射的细节。
端口映射结构示意图:
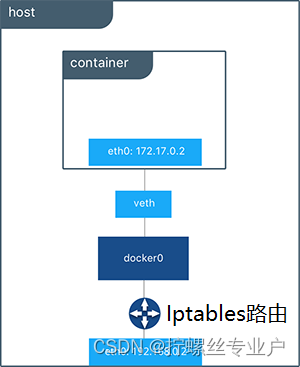
Iptables是一个复杂的存在,它里面有表(tables)、链(chains)和规则(rules)构成,我们就简单把它理解成网络数据包路由。在端口映射的时候,它负责把容器网络数据包的源地址转换为宿主机地址。
iptables简述
iptables是Linux内核自带的包过滤防火墙,支持NAT等诸多功能。iptables由表和规则chain概念组成,Docker中所 用的表包括filter表和nat表(参见上述命令输出结果),这也是iptables中最常用的两个表。iptables是一个复杂的存在,曾 有一本书《linux firewalls》 专门讲解iptables,这里先借用本书 中的一幅图来描述一下ip packets在各个表和chain之间的流转过程:
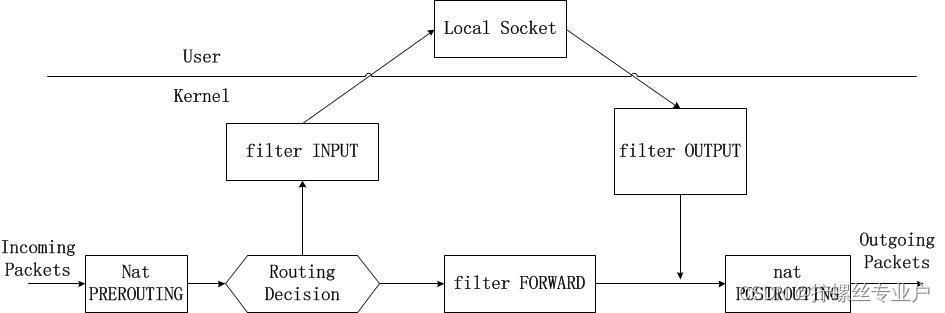
网卡收到的数据包进入到iptables后,做路由选择,本地的包通过INPUT链送往user层应用;转发到其他网口的包通过FORWARD chain;本地产生的数据包在路由选择后,通过OUTPUT chain;最后POSTROUTING chain多用于source nat转换。
iptables在容器网络中最重要的两个功能:
1、限制container间的通信
2、将container到外部网络包的源地址换成宿主主机地址(MASQUERADE)
Docker0的“双重身份”
如何理解Docker0?下图中给出了Docker0的双重身份,并对比物理交换机,来理解一下Docker0这个软网桥。
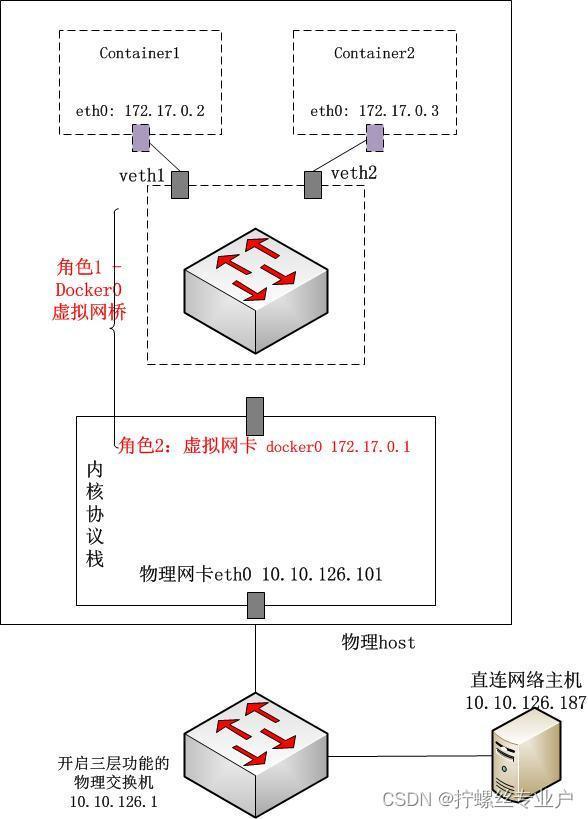
1、从容器视角,网桥(交换机)身份
docker0对于通过veth pair“插在”网桥上的container1和container2来说,首先就是一个二层的交换机的角色:泛洪、维护cam表,在二层转发数据包;同 时由于docker0自身也具有mac地址(这个与纯二层交换机不同),并且绑定了ip(这里是172.17.0.1),因此在 container中还作为container default路由的默认Gateway而存在。
2、从宿主机视角,网卡身份
物理交换机提供了由硬件实现的高效的背板通道,供连接在交换机上的主机高效实现二层通信;对于开启了三层协议的物理交换机而言,其ip路由的处理 也是由物理交换机管理程序提供的。对于docker0而言,其负责处理二层交换机逻辑以及三层的处理程序其实就是宿主机上的Linux内核 tcp/ip协议栈程序。而从宿主机来看,所有docker0从veth(只是个二层的存在,没有绑定ipv4地址)接收到的数据包都会被宿主机 看成从docker0这块网卡(第二个身份,绑定172.17.0.1)接收进来的数据包,尤其是在进入三层时,宿主机上的iptables就会对docker0进来的数据包按照rules进行相应处理(通过一些内核网络设置也可以忽略docker0 brigde数据的处理)。
container模式
这个模式指定新创建的容器和已经存在的一个容器共享一个 Network Namespace,而不是和宿主机共享。新创建的容器不会创建自己的网卡,配置自己的 IP,而是和一个指定的容器共享 IP、端口范围等。同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的。两个容器的进程可以通过 lo 网卡设备通信。
container模式如下图所示:
host模式

none模式
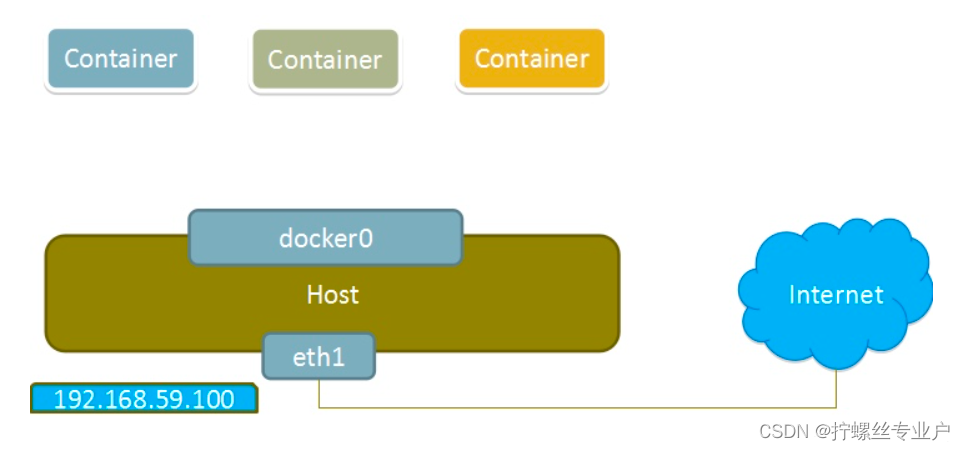
使用none模式,Docker容器拥有自己的Network Namespace,但是,并不为Docker容器进行任何网络配置。也就是说,这个Docker容器没有网卡、IP、路由等信息。需要我们自己为Docker容器添加网卡、配置IP等。
这种网络模式下容器只有lo回环网络,没有其他网卡。none模式可以在容器创建时通过–network none来指定。这种类型的网络没有办法联网,封闭的网络能很好的保证容器的安全性。
应用场景:
-
启动一个容器处理数据,比如转换数据格式
-
一些后台的计算和处理任务
none模式如下图所示:
四、Docker 仓库
镜像构建完成后,可以很容易的在当前宿主机上运行,但是,如果需要在其它服务器上使用这个镜像,我们就需要一个集中的存储、分发镜像的服务,Docker Registry 就是这样的服务。
一个 Docker Registry 中可以包含多个 仓库(Repository);每个仓库可以包含多个 标签(Tag);每个标签对应一个镜像。
通常,一个仓库会包含同一个软件不同版本的镜像,而标签就常用于对应该软件的各个版本。我们可以通过 <仓库名>:<标签> 的格式来指定具体是这个软件哪个版本的镜像。如果不给出标签,将以 latest 作为默认标签。
以 Ubuntu 镜像 为例,ubuntu 是仓库的名字,其内包含有不同的版本标签,如,16.04, 18.04。我们可以通过 ubuntu:16.04,或者 ubuntu:18.04 来具体指定所需哪个版本的镜像。如果忽略了标签,比如 ubuntu,那将视为 ubuntu:latest。
仓库名经常以 两段式路径 形式出现,比如 jwilder/nginx-proxy,前者往往意味着 Docker Registry 多用户环境下的用户名,后者则往往是对应的软件名。但这并非绝对,取决于所使用的具体 Docker Registry 的软件或服务。
Docker Registry 公开服务
Docker Registry 公开服务是开放给用户使用、允许用户管理镜像的 Registry 服务。一般这类公开服务允许用户免费上传、下载公开的镜像,并可能提供收费服务供用户管理私有镜像。
私有 Docker Registry
除了使用公开服务外,用户还可以在本地搭建私有 Docker Registry。Docker 官方提供了 Docker Registry 镜像,可以直接使用做为私有 Registry 服务。
五、总结
上文中我们已经对Docker镜像、容器、仓库有了大致的了解,下面就让我们回顾一下Docker创建容器的完整过程,方便把所有的知识串起来。
docker创建容器过程如下图所示:
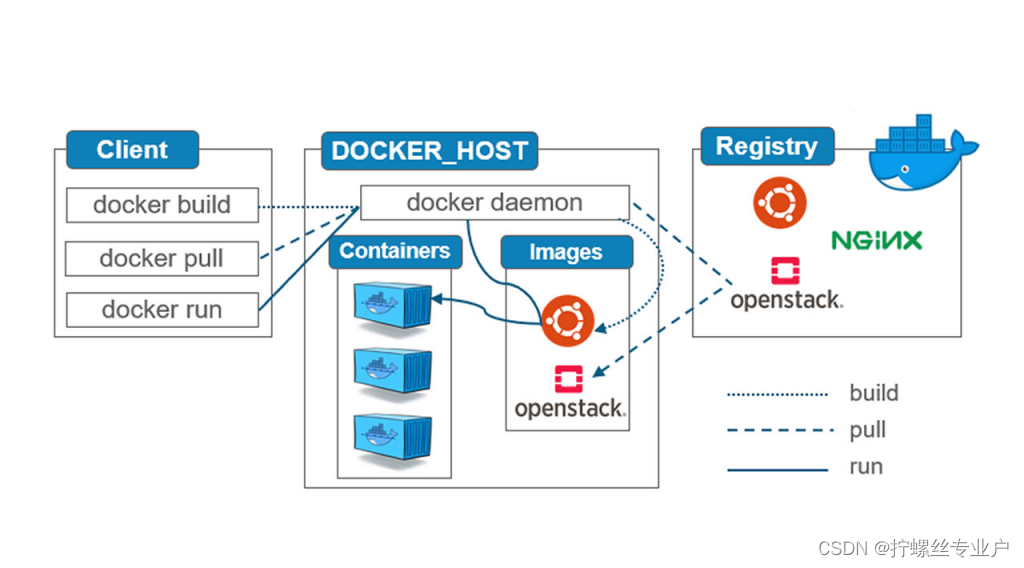
要创建Docker容器,首先得通过Docker客户端命令(一般情况)向Docker守护进程下发请求,然后守护进程会在本地检索镜像,如果没有检索到就会去远端镜像仓库拉取镜像,获得镜像后就会启动初始进程准备容器运行的文件系统、网络、可读写层等,最后启动容器应用进程替代初始化进程自身。
参考资料与资源汇总
参考资料
菜鸟教程
- Docker教程: https://www.runoob.com/docker/docker-tutorial.html
书籍
《Docker源码分析》
Docker资源
- Docker 官方主页: https://www.docker.com
- Docker 中文官网: https://www.docker.org.cn/index.html
- Docker 官方博客: https://blog.docker.com/
- Docker 官方文档: https://docs.docker.com/
- Docker Store: https://store.docker.com
- Docker Cloud: https://cloud.docker.com
- Docker Hub: https://hub.docker.com
- Docker 的源代码仓库: https://github.com/moby/moby
- Docker 发布版本历史: https://docs.docker.com/release-notes/
- Docker 常见问题: https://docs.docker.com/engine/faq/
- Docker 远端应用 API: https://docs.docker.com/develop/sdk/
Docker国内镜像
- 阿里云的加速器:https://help.aliyun.com/document_detail/60750.html
- 网易加速器:http://hub-mirror.c.163.com
- 官方中国加速器:https://registry.docker-cn.com
- ustc 的镜像:https://docker.mirrors.ustc.edu.cn
- daocloud:https://www.daocloud.io/mirror#accelerator-doc(注册后使用)
ud.docker.com](https://cloud.docker.com/)
- Docker Hub: https://hub.docker.com
- Docker 的源代码仓库: https://github.com/moby/moby
- Docker 发布版本历史: https://docs.docker.com/release-notes/
- Docker 常见问题: https://docs.docker.com/engine/faq/
- Docker 远端应用 API: https://docs.docker.com/develop/sdk/
Docker国内镜像
- 阿里云的加速器:https://help.aliyun.com/document_detail/60750.html
- 网易加速器:http://hub-mirror.c.163.com
- 官方中国加速器:https://registry.docker-cn.com
- ustc 的镜像:https://docker.mirrors.ustc.edu.cn
- daocloud:https://www.daocloud.io/mirror#accelerator-doc(注册后使用)