python爬虫简单爬取一个免费的小说网站
python爬虫爬取一个免费的小说网站
首先,我们导入需要的包
import requests
from bs4 import BeautifulSoup
import re
import json
创建header头
headers={
# 浏览器基本信息
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.69'
}
创建data参数,保证在点击下一面时得到要获取的数据
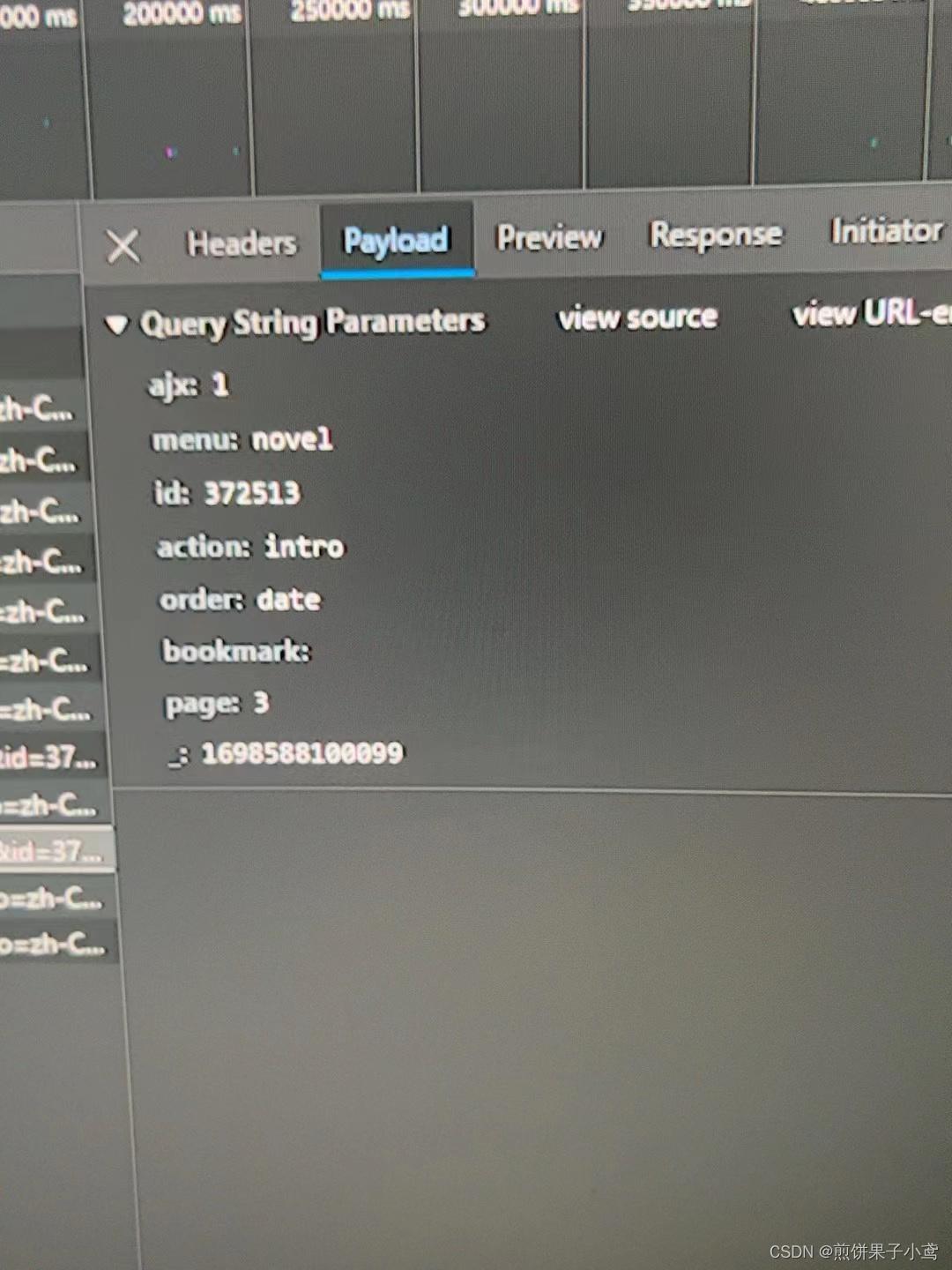
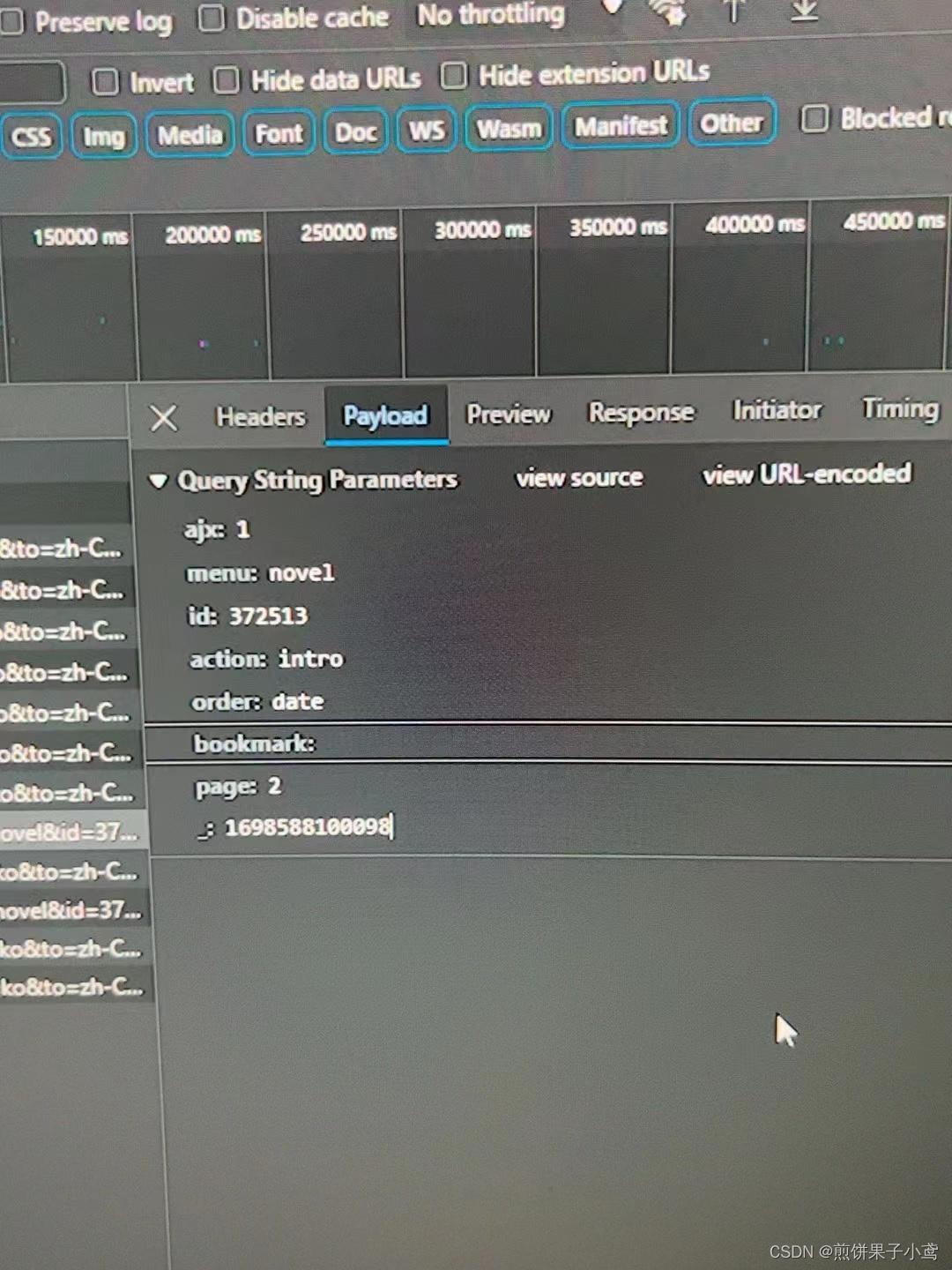
我们观察刷新后的两张图片,可以看出最后两项的数据不同,也就是data参数
data = {
'ajx': '1',
'menu': 'novel',
'id': '372513',
'action': 'intro',
'order': 'date',
'bookmark': '',
'page':f'{2+i}',
'_':f'{1698588100098+i}'
}
调用request函数并用json格式保存
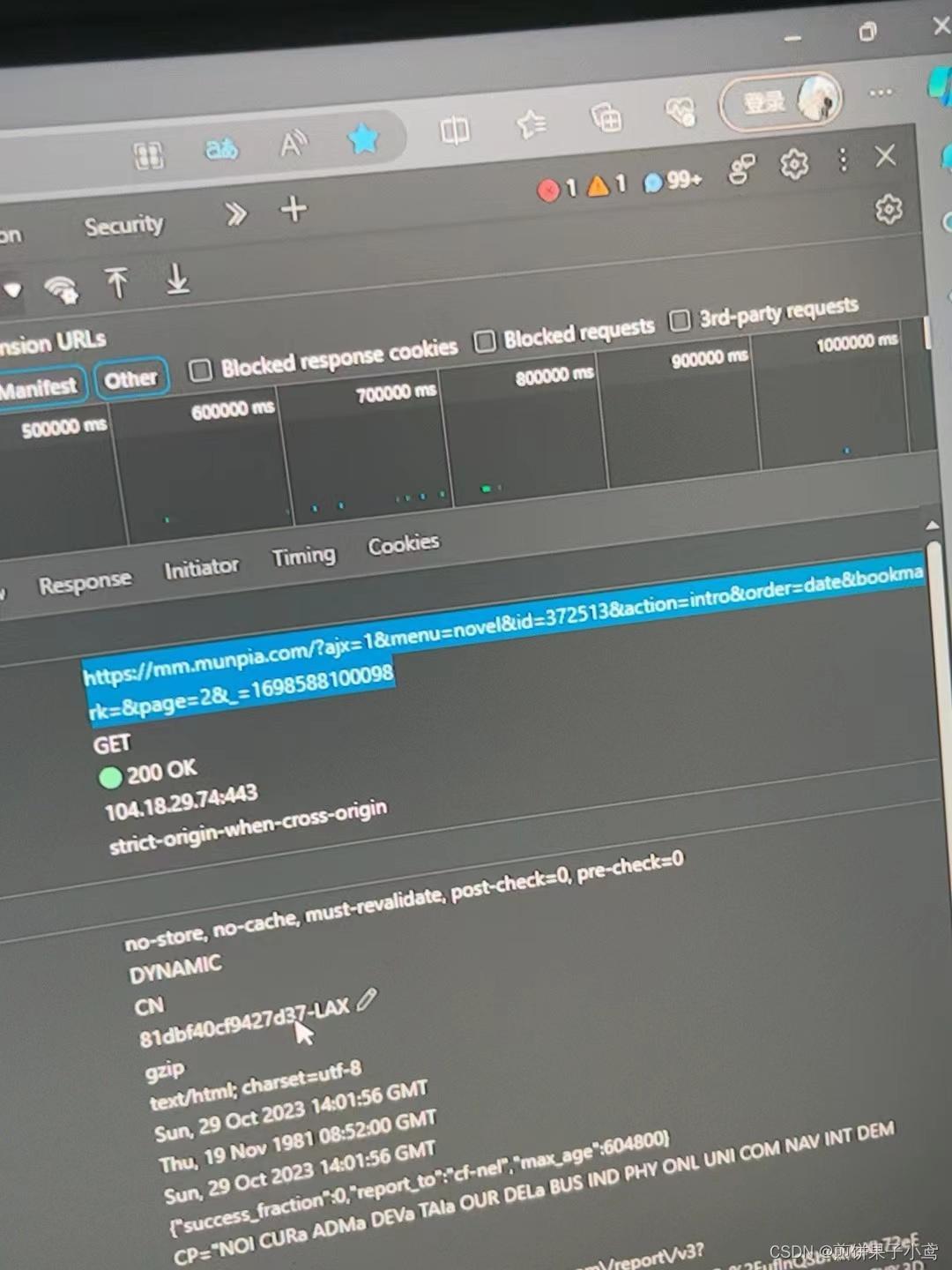
url在表头获取
res=requests.get(f'https://mm.munpia.com/?ajx=1&menu=novel&id=372513&action=intro&order=date&bookmark=&page={i+2}&_={1698588100098+i}',headers=headers,data=data)
# print(res.text)
json_data = json.loads(res.text)
使用for循环从数组中获取每个子网址的ID,拼接网址,利用select获取需要的小说内容,最后写入txt文件中。
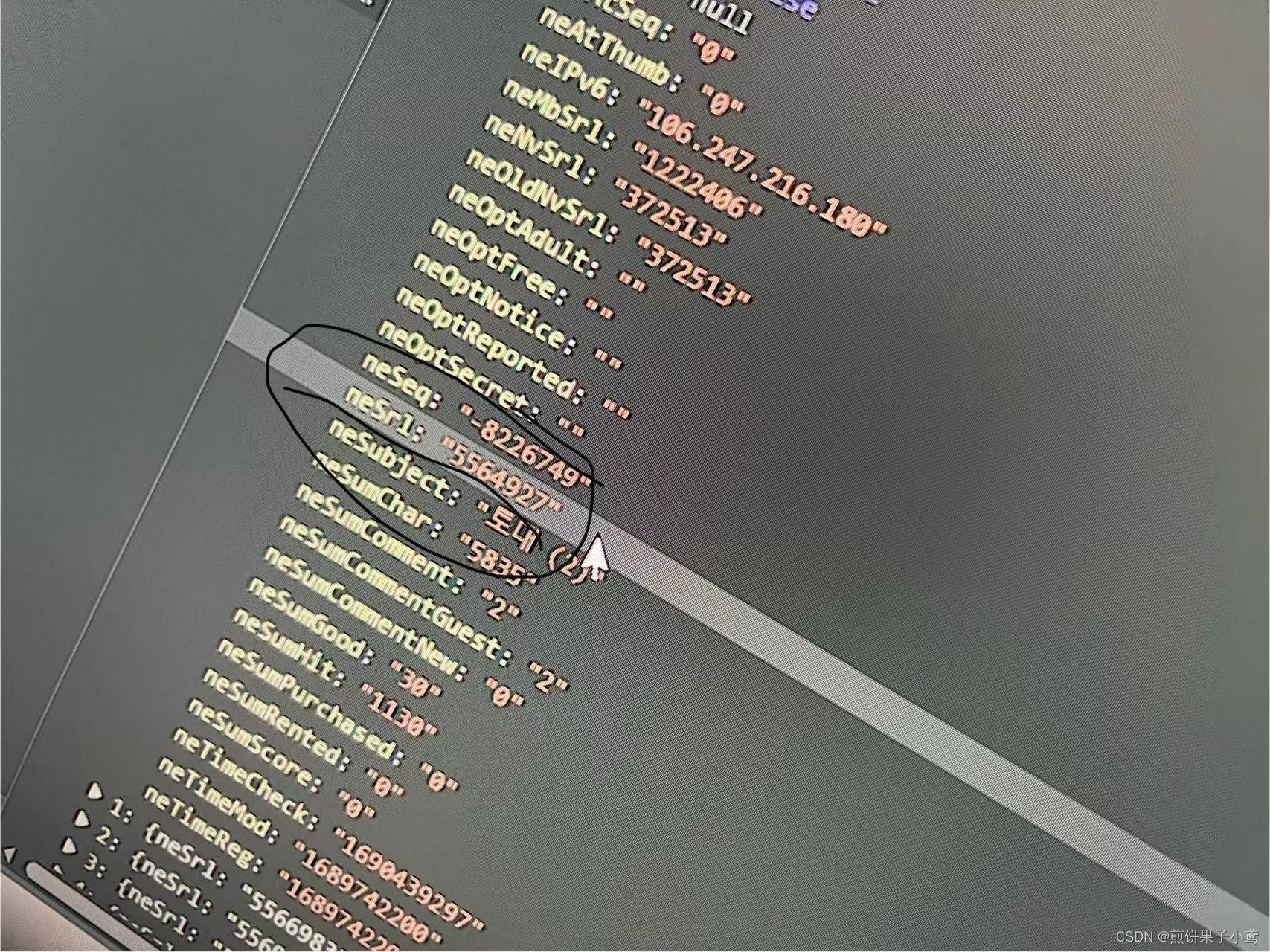
for item in json_data['list']:
url='https://mm.munpia.com/?menu=novel&action=view&id=372513&entry_id='+(item['neSrl'])
print(url)
res = requests.get(url)
bs = BeautifulSoup(res.content, 'html.parser')
title = bs.select('.heading_fiction h2')[0].text
title = title.strip()
print(title)
f = open(f'{title}.txt', mode="w", encoding="UTF-8")
f.write(title)
bodys = bs.select('#view_section p')
for body in bodys:
body = body.get_text()
f.write(body)
以下是完整的代码
import requests
from bs4 import BeautifulSoup
import re
import json
headers={
# 浏览器基本信息
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.69'
}
for i in range(0,5):
data = {
'ajx': '1',
'menu': 'novel',
'id': '372513',
'action': 'intro',
'order': 'date',
'bookmark': '',
'page':f'{2+i}',
'_':f'{1698588100098+i}'
}
res=requests.get(f'https://mm.munpia.com/?ajx=1&menu=novel&id=372513&action=intro&order=date&bookmark=&page={i+2}&_={1698588100098+i}',headers=headers,data=data)
# print(res.text)
json_data = json.loads(res.text)
for item in json_data['list']:
url='https://mm.munpia.com/?menu=novel&action=view&id=372513&entry_id='+(item['neSrl'])
print(url)
res = requests.get(url)
bs = BeautifulSoup(res.content, 'html.parser')
title = bs.select('.heading_fiction h2')[0].text
title = title.strip()
print(title)
f = open(f'{title}.txt', mode="w", encoding="UTF-8")
f.write(title)
bodys = bs.select('#view_section p')
for body in bodys:
body = body.get_text()
f.write(body)