IP/TCP/UDP报文解析(2)TCP报文
前言
本文中涉及很多的位运算,如果对位运算不太了解的请看这篇博文《Java中的位运算》。
正文
TCP报文格式

- 源端口: 占16位 在第1、2字节(下标0、1)中,标识信源机1发送该信息时所分配的端口2。
- 目的端口:占16位 在第3、4字节(下标2、3)中,标识最终收信端主机用来处理该信息时分配的端口。
- 序列码:占32位 在第5、6、7、8字节(下标4、5、6、7)中,标识数据报序列。
- 确认码:占32位 在第9、10、11、12字节(下标8、9、10、11)中,标识确认数据序列。
- 首部长:占4位 在第13字节前4位(下标12)中。标识TCP数据报的首部长度,单位是4字节,所以最大取值为15*4=60字节。第13字节后4位与第14字节的前2位组成6位全为0的预留位,暂无定义
- 标志位:占6位 在第14字节后6位(下标13)中。标识该数据报的行为。其值依次为:
- URG(urgent) :紧急标志 当URG =1时,表明紧急字段有效,告诉系统此报文中有紧急数据,应尽快传送。于是发送方TCP就把紧急数据插入到本报文段数据的最前面,而在紧急数据后面的数据仍是普通数据。这时要与首部中紧急指针字段配合使用。
- ACK(acknowledge):授权标志 可以理解为对端对上一次请求验证通过,可以继续后续行为。所以仅当ACK = 1时确认号字段才有效,TCP规定,连接建立后所有传送的报文段都必须把ACK置1。
- PSH(push):推标志 当两端进行交互式的通信时,有时某一端进程希望在键入一个命令后立即就能收到对端的响应。在这种情况下,TCP就可以将PSH位置为1使用推送操作,对端收到数据报后直接进行处理,不会被加入等待队列。
- RST(reset):复位标志 当复位标志生效时,表明连接中出现严重错误,必须释放连接,然后再重新建立运输连接。
- SYN(synchronous):同步标志 该标志位只在建立连接前两次握手请求中生效。当该值为1时表示该报文是一个请求连接的报文或授权连接的报文。
- FIN(fin):结束标志 该标志只在断开TCP连接时生效。该值为1时标识某一端发出了断开连接的请求。
- 窗口大小:占16位 在第15、16字节(下标14、15)中。窗口大小的作用是数据接收方通告数据发送方自己单次能处理的数据大小,数据发送方根据这个值来确定自己单次发送数据的量,避免发送方因发送数据过快,接收方由于某些原因数据处理较慢,从而造成的丢包重发性能消耗。因其是16位,所以最大取值为65535字节。具体解释请参见《TCP报头里的那个窗口大小到底是指什么》,在此对该博主表以诚挚感谢!
- 校验和:占16位 在第17、18字节(下标16、17)中。用于校验整个报文的准确性,包括首部和数据部分。
- 紧急指针:占16位 在第19、20字节(下标18、19)中。紧急指针仅在紧急标志生效时才有意义,它指出本报文段中的紧急数据结束序号。该报文段的起始序号到这个序号就是该报文段中需要紧急处理的数据。该序号+1就是普通数据序号。即使窗口为0时也可发送紧急数据。
- 选项和填充:可变长度。作用是在报头中添加特殊选项。当没有选项和填充时报头长度是20字节。一般这里会填入一个最大报文段长度MSS,MSS指每一个TCP报文段中的数据字段的最大长度。
- 数据:可变长度。上层协议(一般指HTTP/HTTPs)封装后的报文数据。
TCP建立连接过程
TCP建立连接时会经历3次授权确认的过程,具体如下:
- 客户端随机生成一个数据初始序列号(seq)填入序列码字节中,作为数据存储的起始序号和该次数据段的存储起始位置。将SYN标志位置为1,发送连接申请给服务器端。
- 服务器端收到连接申请后,随机生成一个验证码填入序列码字节中,作为客户端收到授权信息时的确认码。将客户端发来的数据序列码+1后填入确认序列码字节中,作为对客户端的连接申请的确认和该次数据段的存储起始位置,将ACK和SYN位都置为1,发送连接确认给客户端。
- 客户端收到连接确认后,将服务器返回的确认序列码+1填入序列码字节中,作为该段的数据起始位置。将服务器返回的序列码+1后填入确认序列码字节中,作为客户端对服务器授权的确认,将ACK位置为1,发送成功连接的信息给服务器。到此两端就可以有序的收发数据了。
| 发送 | 接收 | 标志位 | 序列码 | 确认码 |
|---|---|---|---|---|
| client | service | SYN = 1 | x | – |
| service | client | SYN = 1 ACK = 1 | y | x +1 = x1 |
| client | service | ACK = 1 | – | y + 1 = y1 |
其中x为客户端报文段的起始序号 随机生成,y为服务端报文段的起始序号 随机生成。序号取值范围0-65535。为什么需要随机生成起始序号呢?是因为如果不是随机产生初始序列号,黑客将会以很容易的方式获取到你与其他主机之间通信的初始化序列号,并且伪造序列号进行攻击,这已经成为一种很常见的网络攻击手段。
TCP数据传输过程
TCP建立连接后传输数据过程如下
- 成功连接后的第1个报文段,客户端将数据初始序号+3填入序列码字节,作为该段报文的存储位置。将初始序号+2填入确认码字节,作为对之前数据段中数据的确认,将PSH和ACK标志位置为1,发送一个推消息告诉服务器自己已经准备就绪,可以开始发送数据了。
- 服务端收到客户端准备就绪的报文后,将收到报文中的序列码+1填入数据序列号中,作为该段报文的起始序号。将这个起始序号+发送数据的长度填入序列码字节中,作为该段报文的结束序号。将ACK标志位置为1,发送数据给客户端。
- 客户端收到数据后,将数据报文中的确认序号+1填入序列码字节,作为客户端报文段的存储位置和数据起始位置。将数据报文中的序列码填入确认序列字节,作为对所有该次数据报文的确认,将ACK标志位置为1,发送给服务器。
重复以上步骤直到数据传递结束,某一段发起断开连接的请求。
| 发送 | 接收 | 标志位 | 序列码 | 确认码 |
|---|---|---|---|---|
| client | service | PSH = 1 ACK = 1 | x+3 = x3 | x+3 = x3 |
| service | client | ACK = 1 | x3 + 1 = x4 | x4 + data length = x5 |
| client | service | ACK = 1 | x5+1 = x6 | x5 |
| service | client | ACK = 1 | x6+1 = x7 | x7+ data length = x8 |
| – | – | – | – | – |
| – | – | – | – | – |
| client | service | ACK = 1 | xn+1 | xn |
| service | service | ACK = 1 | xn+2 | xn+1 |
其中x为客户端随机的数据初始序号(x+3是因为前面3个序号依次进行了 SYN-SENT(同步已发送)状态、服务器ESTABLISHED(已建立连接)状态,客户端ESTABLISHED(已建立连接)状态。为什么+3后没有+1是因为该报文段只是起到一个通知作用,没有进入到数据序列中).
TCP断开连接时的挥手过程
TCP断开连接时会经历4次申请确认过程,具体如下:
- 当某一端(暂且认为是客户端)需要关闭当前TCP连接时,首先将当前收到的数据段中的确认号+1
后填入数据序列字节,将当前收到的序列号+1后填入确认号字节,将ACK、FIN标志位置为1,发送断连请求。 - 当对端(暂且认为是服务端)收到断连请求后,将但当前收到序列号+1填入确认号字节,将确认号+1填入数据序列字节,将ACK位置为1,发送确认回信。表示服务器端收到了客户端的断连请求,此时服务器可能任有数据需要发送,不会立即发送自己断连的请求,所以当客户端收到回信时进入等待服务器断连信息的状态。
- 当服务器将数据全部发送完成后,将当前确认号+1填入序列字节,将当前序列号+1填入确认序列字节,将ACK、FIN标志置为1,发送服务器断连请求。
- 当客户端收到服务器的断连请求后,将当前序列号+1填入确认序列字节,将确认序列+1填入序列字节,将ACK置为1,发送断连确认回信。为了避免网络数据延时返回造成后续使用该端口的连接数据混乱,所以客户端发送回信后不会立即关闭,会进入两个网络延时的等待时间,确保该次连接在网络中不会有延时数据。服务器端收到确认回信后立即关闭连接。
TCP/UDP校验和的计算与数据校验
伪首部格式
TCP与UDP计算校验和时都需要添加一个12字节的伪首部,其格式为:
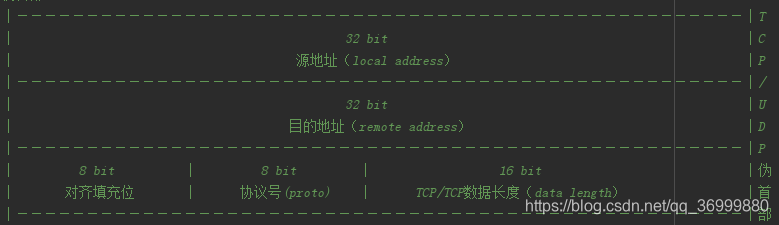
- 源地址:占32位 在伪首部第1、2、3、4字节(下标0、1、2、3)中,标示数据始发地IP地址
- 目的地址:占32位 在伪首部第5、6、7、8字节(下标4、5、6、7)中,标识数据目的地IP地址
- 填充对齐位:占8位 在伪首部第9字节(下标8)中,用于伪首部的数据对齐填充,默认全以0填充。
- 协议号:占8位 在伪首部第10字节(下标9)中,用于标识该数据采用哪种协议解析
- TCP/UDP数据长度:占16位 在位首部第11、12字节(下标10、11)中,用于标识该报文段中TCP/UDP除报头以外的数据长度。注意是该报文段,不是整个协议报文数据长度。
计算校验和
TCP/UDP校验和计算的步骤如下:
- 将报文段中的校验和位置为0
- 将包括伪首部、TCP/DUP报头长度、数据长度中的所有数据字节看成16位一组的数。如果三者字节总长度为奇数字节,还需要在末尾填补一个字节的0.
- 将分组后的所有数进行相加求和。
- 最后的和肯定会大于16位,所以还需要将这个和的进位反复折叠求和,知道其16位之上没有进位。
- 将得到的结果取反得到最终的校验和。
具体实现代请看文末的完整代码。
验证校验和
TCP/UDP的数据校验与校验和计算大体一样,只是在数据校验时无需将校验和位置为0,最终得到的结果取反后取16位的值(~sum) & 16), 如果该值为零 则校验通过 如果不为零 则校验失败 (( ~sum ) & 16 == 0 ? true : false)
TCP为了实现可靠传输,校验和是不可缺少的,校验不通过会要求服务端数据重传。UDP校验和则可以省略。
完整代码
public class TCPPacket extends Packet{
private static final String TAG = TCPPacket.class.getSimpleName();
static final int LOCAL_PORT_BIT = 0;
static final int REMOTE_PORT_BIT = 2;
static final int SEQUENCE_BIT = 4;
static final int ACKNOWLEDGEMENT_SEQUENCE_BIT = 8;
static final int HEADER_LENGTH_BIT = 12;
static final int TAG_BIT = 13;
static final int WINDOWS_SIZE_BIT = 14;
static final int CHECK_SUM_BIT = 16;
static final int URG_BIT = 18;
private byte[] pseudoHeader;
public TCPPacket(byte[] bytes , int... parameters){
super(bytes,parameters);
}
/**
* 获取源端口
* 源端口
* 在TCP数据报中第0、1字节 占2字节 共16位
* @return
*/
public int getLocalPort(){
return byteToInt(bytes[LOCAL_PORT_BIT + offset],bytes[LOCAL_PORT_BIT + offset + 1]);
}
/**
* 获取目的端口
* 目的端口
* 在TCP数据报中第2、3字节 占2字节 共16位
* @return
*/
public int getRemotePort(){
return byteToInt(bytes[REMOTE_PORT_BIT + offset],bytes[REMOTE_PORT_BIT + offset + 1]);
}
/**
* 获取序列码
*
* 序列码
* 在TCP数据报中第4、5、6、7字节 占4字节 共32位
* 由初始请求方随机生成,用来标识数据起始位置的编码。
* TCP将应用层发来的数据对每一字节顺序编号
* TCP首部中的序列号是指在本段报文段所携带数据的第一个字节编号
* 应答方收到请求后值+1后 作为确认序列码返回给请求方标识该请求被成功送达
* 序列码和标志位配合使用,以实现不同的状态逻辑
*/
public int getSequence(){
return byteToInt(bytes[SEQUENCE_BIT + offset],bytes[SEQUENCE_BIT + offset + 1],bytes[SEQUENCE_BIT + offset + 2],bytes[SEQUENCE_BIT + offset + 3]);
}
public void setSequence(int seq){
for(int i = 0;i < 4;i ++){
bytes[SEQUENCE_BIT + offset + i] = (byte) (seq >> ((3 - i) * 8));
}
}
/**
* 获取确认码
*
* 确认序列码
* 在TCP数据报中第8、9、10、11字节 占4字节 共32位
* 如果是请求方 则确认码就是序列码
* 如果是应答方 则确认码是收到的确认码+1
* @return
*/
public int getAcknowledgementSequence(){
return byteToInt(bytes[ACKNOWLEDGEMENT_SEQUENCE_BIT + offset],bytes[ACKNOWLEDGEMENT_SEQUENCE_BIT + offset + 1]
,bytes[ACKNOWLEDGEMENT_SEQUENCE_BIT + offset + 2],bytes[ACKNOWLEDGEMENT_SEQUENCE_BIT + offset + 3]);
}
public void setAcknowledgementSequence(int ack){
for(int i = 0;i < 4;i ++){
bytes[ACKNOWLEDGEMENT_SEQUENCE_BIT + offset + i] = (byte) (ack >> ((3 - i) * 8));
}
}
/**
* 获取首部长
* 头部长
* 在TCP数据报中第12字节前4位 占1/2字节 共4位 单位 4 byte
* TCP默认报头长20字节
* @return
*/
public int getHeaderLength(){
return ((bytes[HEADER_LENGTH_BIT + offset] & 0xFF) >> 4 ) * 4;
}
/**
* 获取标志位
*
* 标志位
* 在TCP数据报中第13字节后6位 占2/3字节 共6位
* 从第13字节第3位起 左至右依次表示为 URG(urgent) ACK(acknowledge) PSH(push) RST(reset) SYN(synchronous) FIN(fin)
* URG 紧急标志 说明这个报文中包含需紧急处理的数据 该位值为 1 时紧急指针生效 指向需紧急处理的数据
* ACK 确认标志 说明发送的请求被送达并返回响应
* PSH 推标志 该标志置位时,接收端不将该数据进行队列处理,而是尽可能快地将数据转由应用处理。在处理Telnet或r login等交互模式的连接时,该标志总是置位的。
* RST 复位标志 要求复位相应的TCP连接
* SYN 同步标志 该标志位只在3次握手建立TCP连接时有效 提示TCP连接的服务端检查序列编号
* FIN 结束标志 该标志位只在4次挥手断开连接时有效
*/
public int getTag(){
return bytes[TAG_BIT + offset] & 0x2F;
}
public boolean isURG(){
return (getTag() >> 5) == 1;
}
public boolean isACK(){
return ((getTag() >> 4) & 1) == 1;
}
public boolean isPSH(){
return ((getTag() >> 3) & 1) == 1;
}
public boolean isRST(){
return ((getTag() >> 2) & 1) == 1;
}
public boolean isSYN(){
return ((getTag() >> 1) & 1) == 1;
}
public boolean isFIN(){
return (getTag() & 1) == 1;
}
/**
* 获取窗口大小
* 窗口大小
* 在TCP数据报中第14、15字节 占2字节 共16位
* 用来表示想收到的每个TCP数据段的大小。TCP的流量控制由连接的每一端通过声明的窗口大小来提供
* 窗口大小最大为65535字节
* @return
*/
public int getWindowsSize(){
return byteToInt(bytes[WINDOWS_SIZE_BIT + offset],bytes[WINDOWS_SIZE_BIT + offset + 1]);
}
/**
* 获取紧急指针
* 紧急指针
* 在TCP数据报中第18、19字节 占2字节 共16位
* 用于标识数据报中需紧急处理的数据位置
* @return
*/
public int getUrg(){
return byteToInt(bytes[URG_BIT + offset],bytes[URG_BIT + offset + 1]);
}
/**
* 获取校验和
* 校验和
* 在TCP数据报中第16、17字节 占2字节 共16位
* 用于对TCP数据的校验 由发送端对数据报中所有数据计算得出
* @return
*/
public int getCheckSum(){
return byteToInt(bytes[CHECK_SUM_BIT + offset],bytes[CHECK_SUM_BIT + offset + 1]);
}
/**
* 检查校验和
* @return
*/
public boolean checkSum(){
return (~getSum() & 0xFFFF) == 0;
}
// 获取和
private int getSum(){
int sum = 0;
if(pseudoHeader != null){
for(int i = 0;i < pseudoHeader.length; i += 2){
sum += byteToInt(pseudoHeader[i],pseudoHeader[i + 1]);
}
}
for(int i = offset;i < validLength;i += 2){
sum += byteToInt(bytes[i],bytes[i + 1]);
}
if((validLength - offset) % 2 > 0){
sum += (bytes[validLength - 1] & 0xFF) << 8;
}
while ((sum >> 16) > 0){
sum = (sum >> 16) + (sum & 0xFFFF);
}
return sum;
}
// 初始化伪首部 在数据校验 与 计算校验和之前必须进行初始化
public void initPseudoHeader(int localIP,int remoteIP,int length){
pseudoHeader = new byte[12];
for(int i = 0;i < 4;i ++){
pseudoHeader[i] = (byte) (localIP >> ((3 - i) * 8));
pseudoHeader[i + 4] = (byte) (remoteIP >> ((3 - i) * 8));
}
pseudoHeader[8] = 0 ;
pseudoHeader[9] = 6 ;
pseudoHeader[10] = (byte) (length >> 8);
pseudoHeader[11] = (byte) length;
}
public void refreshCheckSum(){
bytes[CHECK_SUM_BIT + offset] = 0;
bytes[CHECK_SUM_BIT + offset + 1] = 0;
int m = ~getSum();
bytes[CHECK_SUM_BIT + offset] = (byte) (m >> 8);
bytes[CHECK_SUM_BIT + offset + 1] = (byte)m;
}
/**
* 设置本地锻端口
* @return
*/
public void setLocalPort(int port){
bytes[LOCAL_PORT_BIT + offset] = (byte) (port >> 8);
bytes[LOCAL_PORT_BIT + offset + 1] = (byte) port;
}
/**
* 设置远程端口
* @param port
*/
public void setRemotePort(int port){
bytes[REMOTE_PORT_BIT + offset] = (byte) (port >> 8);
bytes[REMOTE_PORT_BIT + offset + 1] = (byte) port;
}
}
注释很简洁,不过配合上面几部分的内容,应该能看懂是什么意思。关于代码中Packet类的代码在《IP/TCP/UDP报文解析(1)IP报文》中有完整代码。
总结
到此TCP的报文格式、连接过程、数据传递过程、断开连接过程、报文的校验、校验和的计算我知道的知识点都在这里了,希望你能有所收获。