通过nodeJS如何实现爬虫功能
对于新手小白刚入行爬虫行业来说,是选择java、C++、python还是nodeJS作为爬虫语言编程爬虫程序呢,每一种语言都有它独特的特点,那么今天本文将以nodeJS实现一个简单的网页爬虫功能说起。
网页源码
使用http.get()方法获取网页源码,以hao123网站的头条页面为例
http://tuijian.hao123.com/hotrank
var http = require('http');
http.get('http://tuijian.hao123.com/hotrank',function(res){
var data = '';
res.on('data',function(chunk){
data += chunk;
});
res.on('end',function(){
console.log(data);
})
});
筛选数据
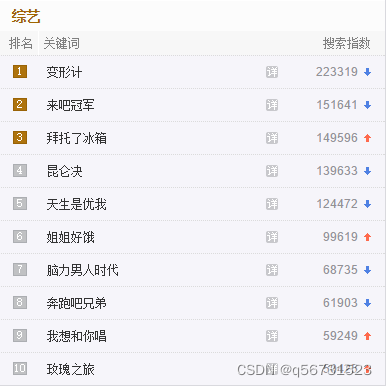
以网页中的综艺热点部分
相关源代码如下
通过分析可知,‘综艺’模块与其他模块都位于<div class="top-wrap">中,其中,综艺模块的内层div的monkey='zy',综艺模块的10条综艺节目的信息都位于<div class="poinr clearfix">中,综艺节目的名称位于中
cheerio
我们怎么从源代码中获取到有用的数据呢?首先,nodeJS不支持document对象。如果要使用笨办法,只能使用正则表达式来处理
cheerio 是nodejs特别为服务端定制的,能够快速灵活的对JQuery核心进行实现。它工作于DOM模型上,且解析、操作、呈送都很高效
【安装】
【使用】
它的使用方法和jQuery相当类似,上手非常容易。以获取综艺热度前10名的节目名称为例
var http = require('http');
var cheerio = require('cheerio');
http.get('http://tuijian.hao123.com/hotrank',function(res){
var data = '';
res.on('data',function(chunk){
data += chunk;
});
res.on('end',function(){
filter(data);
})
});
function filter(data){
//保存搜索量前10的综艺节目标题
var result = [];
//将页面源代码转换为$对象
var $ = cheerio.load(data);
//查找每个综艺节目标题的外层div
var temp_arr = $('[monkey = "zy"]').find('.point-bd').find('.point-title');
//将综艺节目标题依次保存到结果数组中
temp_arr.each(function(index,item){
result.push($(item).text());
})
//[ '变形计','来吧冠军','拜托了冰箱','昆仑决','天生是优我','姐姐好饿','脑力男人时代','奔跑吧兄弟','我想和你唱','玫瑰之旅' ]
console.log(result);
}
爬虫代码
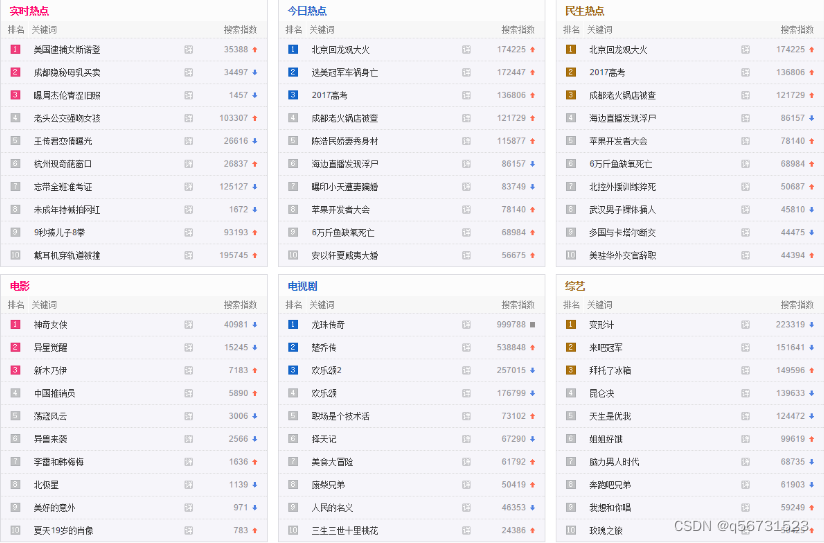
下面将hao123网页中的’实时热点’、‘今日热点’、‘民生热点’、‘电影’、‘电视剧’、‘综艺’这6部分的排名爬下来,分别到对象名为’result’中的数组中,分别命令为’ss’、‘jr’、‘ms’、‘dy’、‘dsj’、‘zy’
【代码如下】
var http = require('http');
var cheerio = require('cheerio');
http.get('http://tuijian.hao123.com/hotrank',function(res){
var data = '';
res.on('data',function(chunk){
data += chunk;
});
res.on('end',function(){
filter(data);
})
});
function filter(data){
//保存各部分搜索量前10的名称
//对象名为榜单名,如'实时热点'
//对象内容为10个标题名称组成的数组
var result = {};
//将页面源代码转换为$对象
var $ = cheerio.load(data);
//查找'实时热点'、'今日热点'、'民生热点'、'电影'、'电视剧'、'综艺'这6个榜单所在的div
var temp_div = $('.top-wrap');
//保存榜单名称
var temp_title = [];
temp_div.each(function(index,item){
//查找榜单名,并保存到temp_title文件夹中
temp_title.push($(item).find('h2').text());
//查找每类下每个标题的外层div
var temp_arr = $(item).find('.point-bd').find('.point-title');
//将result下的每个榜单初始化为一个数组
var innerResult = result[temp_title[index]] = [];
//将节目标题依次保存到相应榜单的数组中
temp_arr.each(function(_index,_item){
innerResult.push($(_item).text())
})
})
console.log(result);
}