一文读懂clickhouse 的normal join和global join区别
文章目录
背景
同事问了我一个这样的问题,语义如下
表定义
定义两个分布式表
tablea 2 shard 1 replica user_id不是分区键
tableb 2 shard 1 replica user_id是分区键

SQL-1
select count(1) from tablea_all as ta join tableb_all as tb on ta.user_id=tb.user_id
where ta.user_id=1
结果1
result is 1
SQL-2
select count(1) from tablea_all as ta global join tableb_all as tb on ta.user_id=tb.user_id
where ta.user_id=1
两个SQL只是join 方式不一样而已
结果2
result is 2
结果竟然不一样???
思考
在我之前的知识体系里,clickhouse 的join分成三种
Shuffle Join
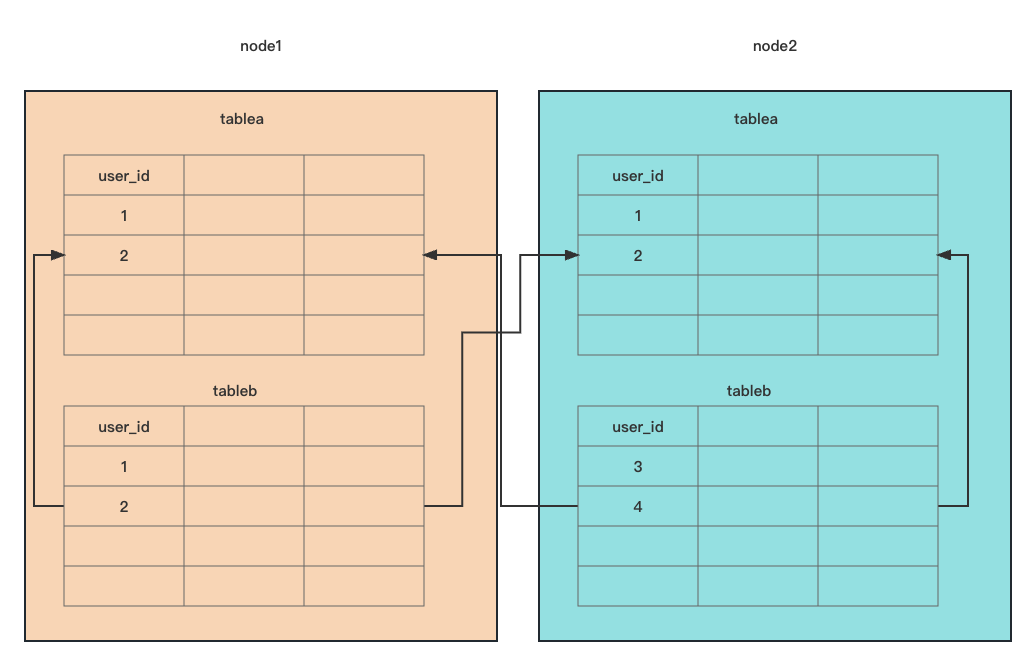
每条实线箭头线相当于一次join=4次
单独看表tableb 数据读了4次
Broadcast Join

每条实线箭头线相当于一次join=2次
单独看表tableb 数据读了2次
Colocate Join

每条实线箭头线相当于一次join=2次
单独看表tableb 数据读了2次
重看问题
因为之前一直认为的是join 指的就是Shuffle Join,但是这种会放大读,所以一直都是用的global join,但是join 和global join 语义上是一致的,都能够在分布表下表达出相同的语义,为啥这里的结果表现不一样了,这个问题一下把我把懵了,然后在google和baidu都看了相关的资料,基本上所有的资料都告诉我,事实就是这样了的,这里尤其以 火山引擎在行为分析场景下的ClickHouse JOIN优化. 这一篇文章的内容传播最广,很多其它人写的也就是在这上面加工的,可是这个事实和文章里的写的不一样呀,之前刚好字节数据team有一个活动,拉了一个群,于是在群里问了一下这个问题,可是没人搭理,哎本着实事求是的态度,然后去分析ck节点的日志信息,发现sql1 实现的Colocate Join 语义,只是在每个节点实现了tablea_local和tableb_local的语义,这样结果就是1,这一刻我有点怀疑是不是搜索引擎都是错的,join 根本都没有实现Shuffle Join,这个语义在分布式表的情况就是错的,我只相信我看到的,最后还有一招,在github上,找到clickhouse 提了一个issue,看看有没有大佬能解答我的疑惑,幸运的是中午提了issue,链接,晚上查看邮箱发现这个issue已经有回复了,回复中提到了distributed_product_mode 配置
distributed_product_mode
范围
仅适用于IN和JOIN子查询。
仅当FROM部分使用包含多个分片的分布式表时。
如果子查询涉及一个包含多个分片的分布式表。
可能值
deny—默认值。禁止使用这些类型的子查询(返回“Double distributed in/JOIN subquery is denied”异常)。
local-将子查询中的数据库和表替换为目标服务器(shard)的本地数据库和表,留下正常的in/JOIN。
global-将IN/JOIN查询替换为global IN/global JOIN。
allow-允许使用这些类型的子查询。
测试
测试使用 distributed_product_mode=allow/global sql1都能实现正确的语义,结果是2,于是我看了这个参数的默认值,结果是local,也就证实现了为啥结果是1,日志里显示的只有两个节点上执行的都是tablea_local join tableb_local
为啥为allow结果也是对的,all 实现的的Shuffle Join,从node 节点里的日志也能看出来有4次join
为啥为global结果也是对的,gobal会把sql重写也就是sql2的语义,所以也是对的
总结
这个问题历时周四,周五二天,几乎看了所有相关的资料,中间不断的怀疑自己的结论又推翻,最后找到了正确的答案,这个问题中,看节点里的查询sql日志能够增加我们对join在这种分布式表的环境下实现原理的理解。遇到问题时还是要实事求是,既要参考网上的资料,也要相信自己所看到的,实际上网上的资料也没有说错,只是没有说清楚这个配置distributed_product_mode的默认值,这个默认值是local也是能理解的,毕竟这样的join数据量是最少的。
