Deep Reinforcement Learning Based Resource Allocation andTrajectory Planning in Integrated Sensing
1、基本内容:
ISAC通过共享设备和频谱,可以大大降低硬件成本和训练开销,从而提高频谱效率和能量效率。由于UAV具有可控的移动性,部署的灵活性及其低廉的成本,利用UAV作为空中ISAC基站不仅可以通过移动建立直视路径,而且可以大大增加ISAC系统的灵活性。但是,由此带来的调度和轨迹规划问题是设计难点。
本文联合优化用户关联、无人机轨迹规划和功率分配,以最大化无人机的最小加权频谱效率。
(1)作者首先利用对称群对原问题进行了等效变换,然后利用SAC算法求解。为了提高样本效率,作者引入了两种数据增强方案:random和adaptive。
(2)利用多智能体SAC(MASAC)求解问题。
2、系统模型:
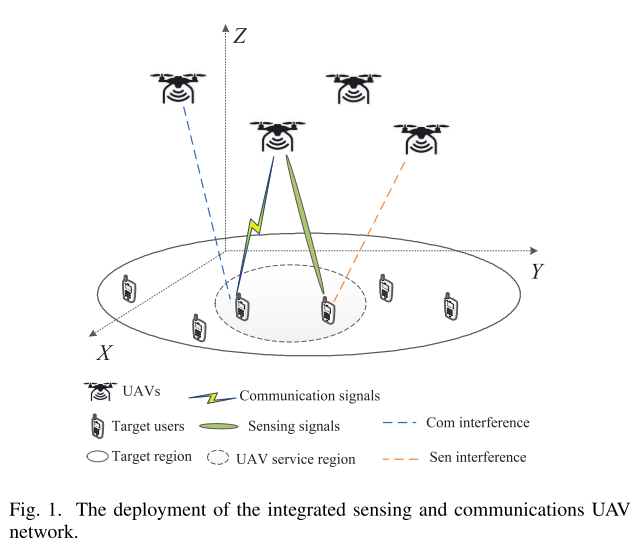
多无人机(2D)、多目标用户
无人机位置: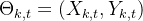
一个时隙飞行的最大距离: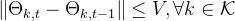
无人机间的最小避免碰撞距离: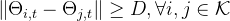
用户协同:每架无人机可服务多个目标用户,且每个目标用户仅由一架无人机服务。
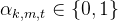
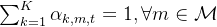
无人机最大能量约束:
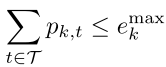
——————————————————————————————————————————
通信信道增益: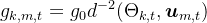
感知信道增益: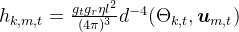
通信频谱效率:
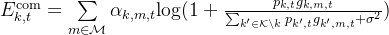
感知频谱效率:
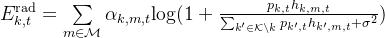
加权频谱效率:
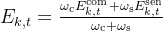
长期的加权频谱效率:
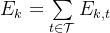
3、优化问题:
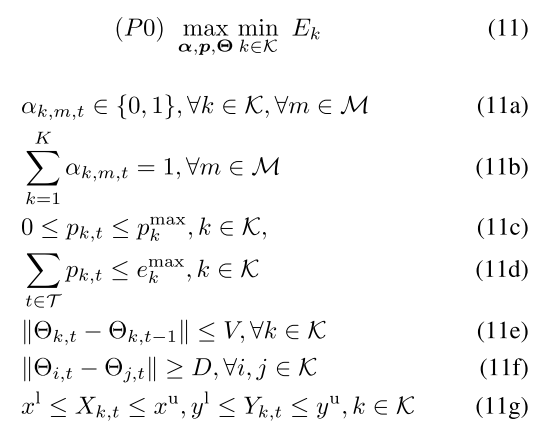
混合动作空间:
因为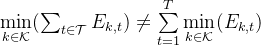 ,所以在设计奖励函数时,需要引入Jain 公平指数。
,所以在设计奖励函数时,需要引入Jain 公平指数。
Jain 公平指数:
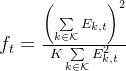
奖励函数:
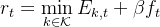
作者提出每个无人机的索引都是认为安排的,那么可以对其索引进行全排列,这样可以轻松得到其对称群,将对称群的数据也加入到经验池,相当于实现经验池数据的扩充。(没太看懂,感觉就是把一组数据复制了多次)
数据增强方案:
(1)random:每个episode从对称群中随机选一定数量的轨迹。
(2)adaptive:随着算法训练,从对称群中选取的轨迹适应性减少。
选取数量: