mysql between and 包含边界吗_MySQL | SQL语法(一)

本篇使用的数据库管理工具是Navicat for MySQL,以3个数据源表table1,table2,table3为例,简单举例陈述SQL中数据查询语言的使用。
一、DB、DBMS与SQL
DB(Database),即数据库,相当于一个仓库,用于有组织地存储数据。
DBMS(Database Management System),即数据库管理系统,用于操作和管理数据库。主要分为两大类:RDBMS、NoSQL。
- RDBMS:关系型数据库管理系统,主要实现对结构化数据的管理,为二元关系模型。如Oracle、MySQL、SQL Server、DB2等。
- NoSQL:非关系型数据库管理系统,弥补关系型数据库管理系统的不足。如Redis、MongoDB等。
SQL(Structured Query Language),即结构化查询语言,是关系型数据的一门通用语言,用于实现对数据库的查询、更新和管理。其语言主要分为四个部分:DDL、DML、DCL和DQL。
- DDL(Data Definition Language),数据定义语言,它用来定义我们的数据库对象,包括数据库、数据表和列。通过使用DDL,我们可以创建、删除和修改数据库及表结构。
- DML(Data Manipulation Language),数据操作语言,我们用它操作和数据库相关的记录,比如增加、删除、修改数据表中的数据。
- DCL(Data Control Language),数据控制语言,我们用它来定义访问权限和安全级别。
- DQL(Data Query Language),数据查询语言,我们绝大多数情况下都是在和查询打交道,因此学会编写正确且高效的查询语句非常重要。
三者的关系是:数据库管理系统(DBMS)使用SQL语句管理数据库(DB)。注:所有的DBMS使用的SQL语句基本相同,只存在个别不兼容。
二、DQL:数据查询语言
1.查询表中所有的数据
select * from table_name
select Navicat for MySQL运行结果如下:
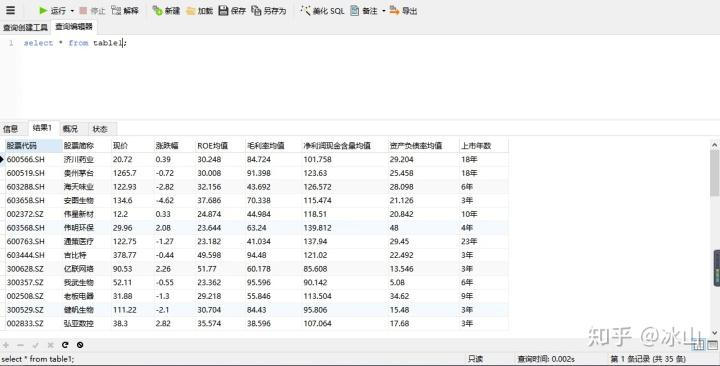
*代表所有列,table_name代表表的名称,结果显示table1中全部35条数据。
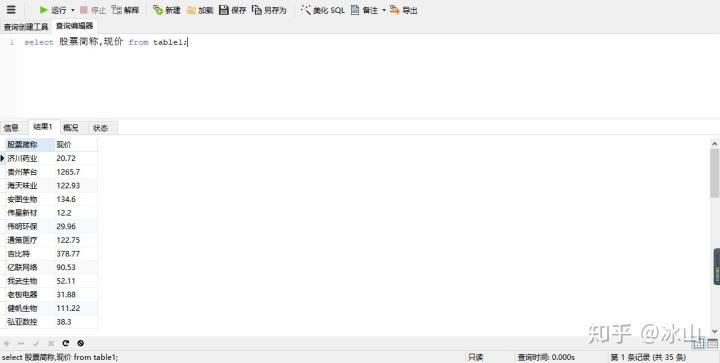
2.查询表中指定字段的数据
select column1,column2,... from table_name
select Navicat for MySQL运行结果如下:
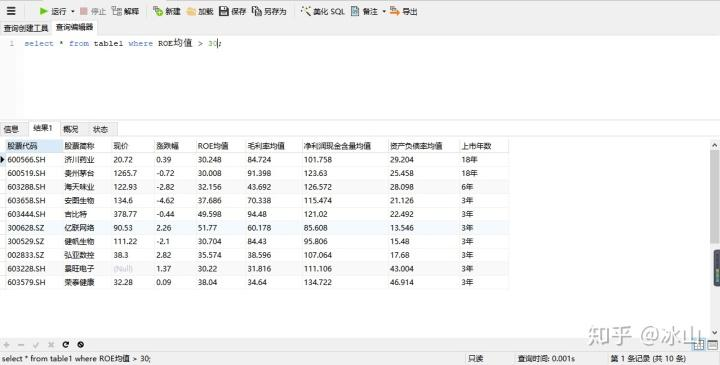
3.按条件查询表中的数据(单一条件)
select * from table_name where column 运算符 value
select Navicat for MySQL运行结果如下:
4.按条件查询表中的数据(组合and)
select * from table_name where column1 运算符 value1 and column2 运算符 value2
select Navicat for MySQL运行结果如下:
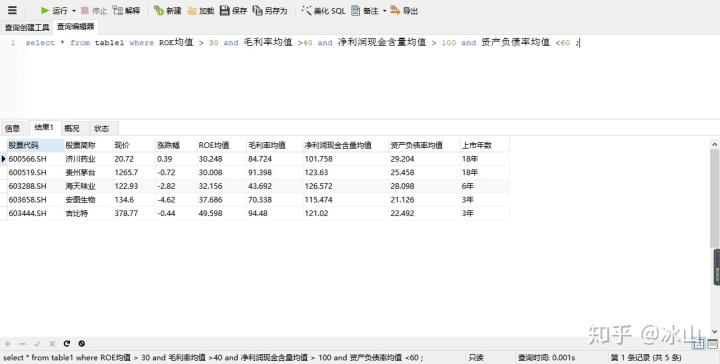
要全部符合and连接的条件才会被筛选出来,结果显示只有5条数据符合条件。
5.按条件查询表中的数据(组合or)
select * from table_name where column1 运算符 value1 or column2 运算符 value2
select Navicat for MySQL运行结果如下:
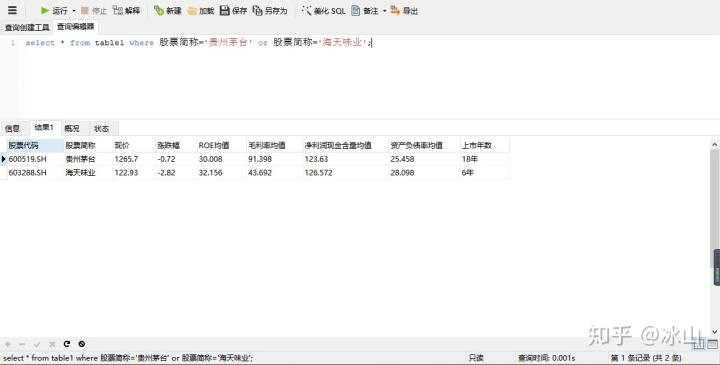
符合or连接中的任意一个条件即可以被筛选出来,结果显示了指定的两条数据。
6.按条件查询表中的数据(范围between)
select * from table_name where column between value1 and value2
select Navicat for MySQL运行结果如下:
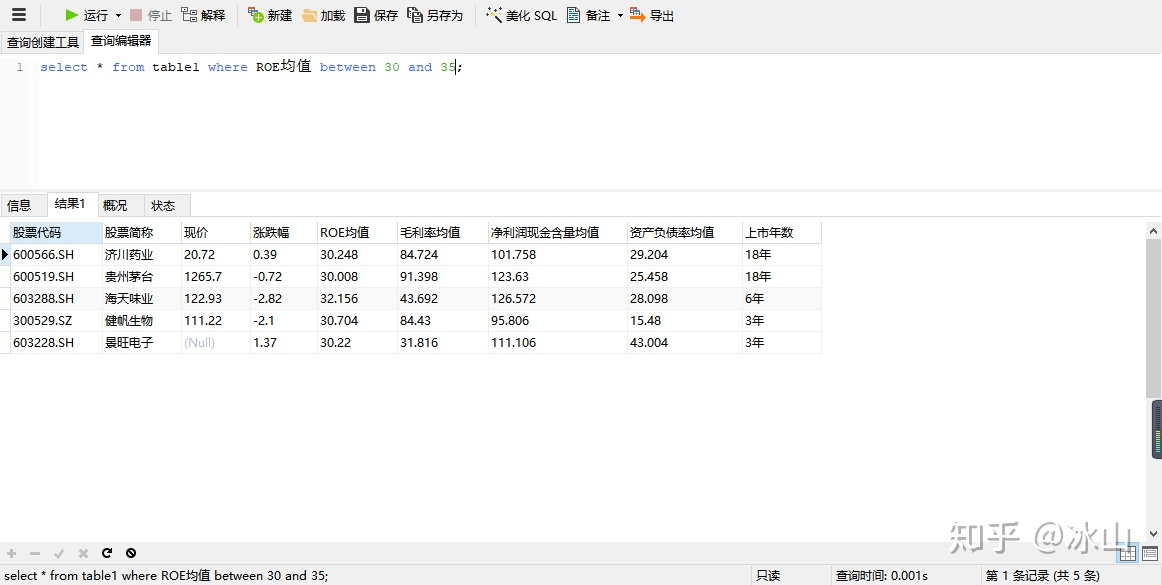
在MySQL中,between包含value1和value2边界值,结果显示了有5条数据在指定的范围内。
7.按条件查询表中的数据(集合查询in)
select * from table_name where column in (value1,value2,...)
select * from table1
where
上市年数 in ('3年','4年','5年');Navicat for MySQL运行结果如下:
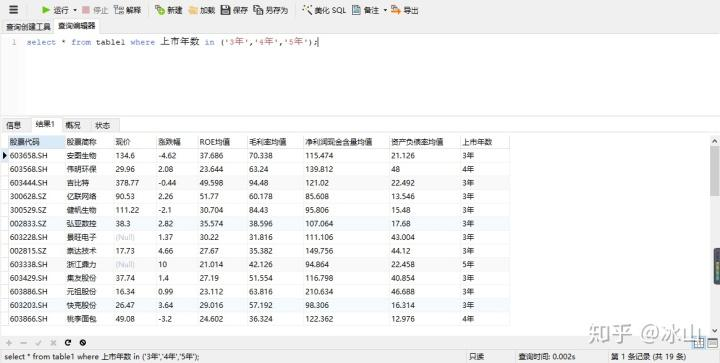
只要符合in后面中的任意条件就会被筛选出来,结果显示有19条数据符合括号内的条件。
8.查询并定义别名(as)
as可省略
- select column1 as name1,column2 as name2,... from table_name;
- select column1,column2 from table_name as name
select 股票代码 as 代码,股票简称 as 股票 from table1;Navicat for MySQL运行结果如下:
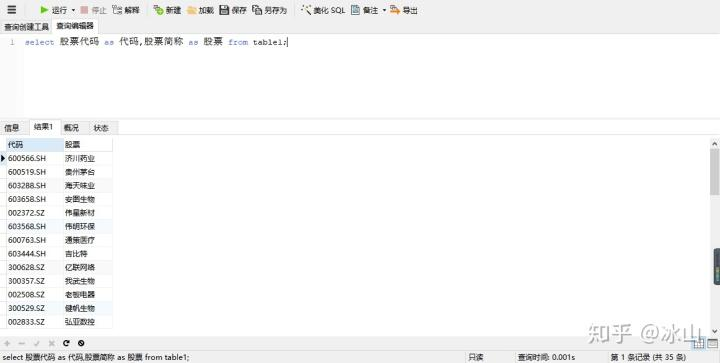
展示表中,列名由“股票代码”变为“代码”,“股票简称”变为“股票”,有时候可以利用这种方法对列名进行重命名,以让数据更加清晰可观。
9.查询并去除重复值(distinct)
select distinct column from table_name
select distinct 上市年数 from table1;Navicat for MySQL运行结果如下:
在table1表中有很多“上市年数”相同的数据,distinct可以去除列中重复的数值并将其展示出来。
10.查询并进行空值筛选(null)
- select * from table_name where column is null
- select * from table_name where column is not null
select Navicat for MySQL运行界面如图所示:
null即是空值,如果想筛选非空值使用not null即可。
11.模糊查询(like)
1)查询以s开头的字段
select * from table_name where column like 's%'
2)查询以s结尾的字段
select * from table_name where column like '%s'
3)查询包含s的字段
select * from table_name where column like '%s%'
4)查询第二个字是s的字段
select * from table_name where column like '_s%'
select Navicat for MySQL运行结果如下:
%指代任意字符,_代表单个字符。
12.排序查询(order by)
select * from table_name order by column1 asc|desc,column2 asc|desc,...
select Navicat for MySQL运行结果如下:
asc代表升序排列,desc代表降序排列,默认为升序排列。
13.限制查询(limit)
select * from table_name limit index,lines
select * from table1 limit 5;Navicat for MySQL运行结果如下:
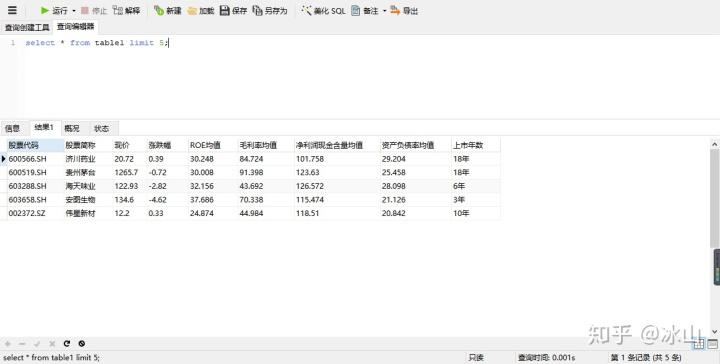
限制查询可以按自定义查询要展示的行数据,lines代表要展示的行数,index代表要展示的行数从第几行开始算起,默认从0开始,即从首行数据开始展示。
14.分组查询(group by)
select avg(column1) from table_name group by column2
select 上市年数,avg(ROE均值) from table1
group by
上市年数;Navicat for MySQL运行结果如下:
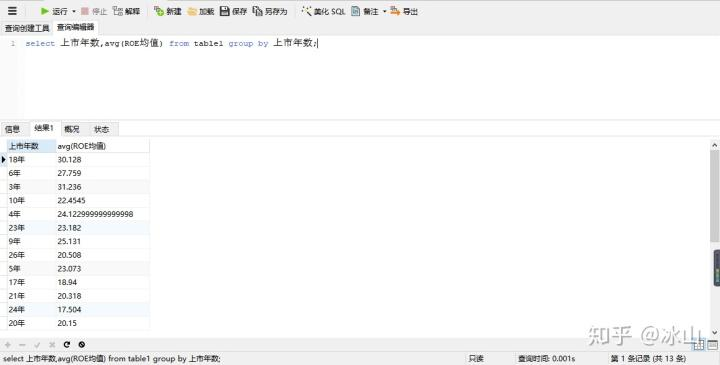
group by按照列中相同的数据分为一组,接着对分组后的数值进行计算并展示。
15.分组过滤查询(having)
select avg(column1) from table_name group by column2 having avg(column1) 运算符 value
select 上市年数,avg(ROE均值) from table1
group by
上市年数
having
avg(ROE均值)>30;Navicat for MySQL运行结果如下:
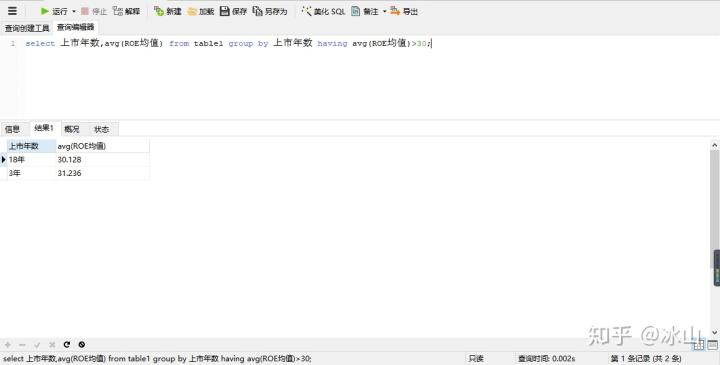
having的意思相当于where,在这里使用having是因为where无法对分组后的数据进行筛选(where的顺序在group by前面)。
16.关联查询(join)
1)内连接:通过同一个列中相同的值将表匹配起来,进行关联并展示。
①使用条件where:该方法与inner join ... on ...结果相同
select * from table_name1,table_name2
where
table_name1.column =table_name2 .column
②inner join ... on ...
select * from table_name1
inner join
table_name2
on
table_name1.column = table_name2.column
select * from table1,table2
where
table1.股票代码=table2.股票代码;或
select * from table1
inner join
table2
on
table1.股票代码=table2.股票代码;Navicat for MySQL运行结果如下:

table1有35条数据,table2有31条数据,两表中“股票代码”列相同的值只有31条,所以最后展示出来的只有31条数据。使用条件where和inner join ... on ... 结果相同,只不过最终会显示两个相同的列,若是想要合并该列,可使用以下第3种方法。
③合并列:inner join ... using ...
select * from table_name1
inner join
table_name2
using(column)
select * from table1
inner join
table2
using(股票代码);Navicat for MySQL运行结果如下:
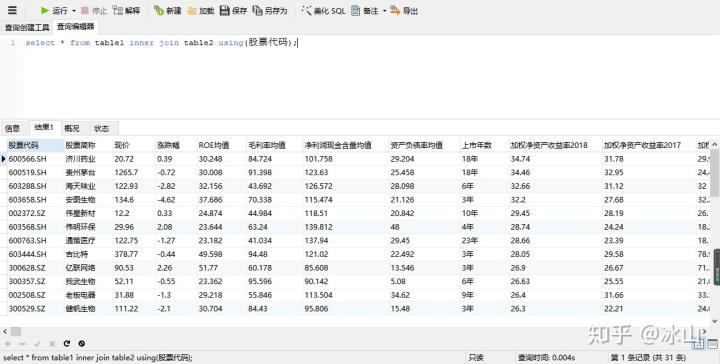
内连接的方法只能将列中相同的值的行数据合并在一起,如果想要合并更多的行数据,可以使用外连接。
2)外连接:以其中一张表为驱动表,与另外一张表的每条记录进行匹配,如果能够匹配则进行关联并展示,如果不能匹配则以null填充。
①左外连接:left join ... on
select * from table_name1
left join
table_name2
on
table_name1.column = table_name2.column
select * from table1
left join
table2
on
table1.股票代码=table2.股票代码;Navicat for MySQL运行结果如下:
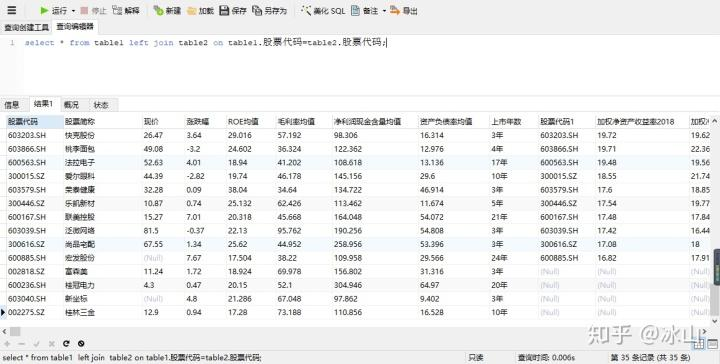
以table1为驱动表,table1有35条数据,table2有31条数据,table1最后几条比table2多的数据的剩余值将以null进行填充。
②右外连接:right join ... on
select * from table_name1
right join
table_name2
on
table_name1.column = table_name2.column
select * from table1
right join
table2
on
table1.股票代码=table2.股票代码;Navicat for MySQL运行结果如下:
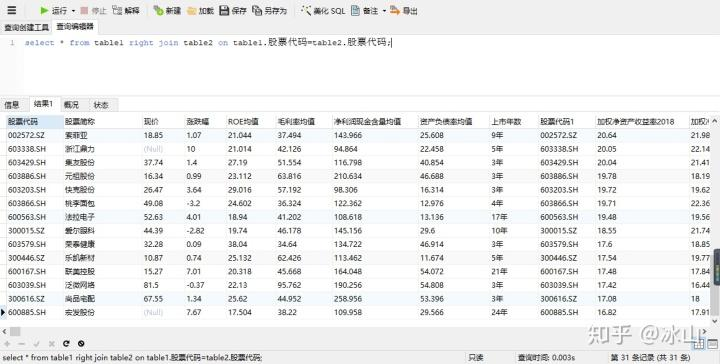
以table2为驱动表,table1有35条数据,table2有31条数据,结果以table2为准只查询出31条数据。
3)自连接
select * from table_name1 name1
left join
table_name1 name2
on
name1.column1 = name2.column2
与外连接同理,在同一张表中进行匹配,如果能够匹配的则进行关联并展示,不能匹配的则以null填充。
17.组合查询(union)
1)去除重复值
select * from table_name1
union
select * from table_name2
select * from table1
union
select * from table3;Navicat for MySQL运行结果如下:
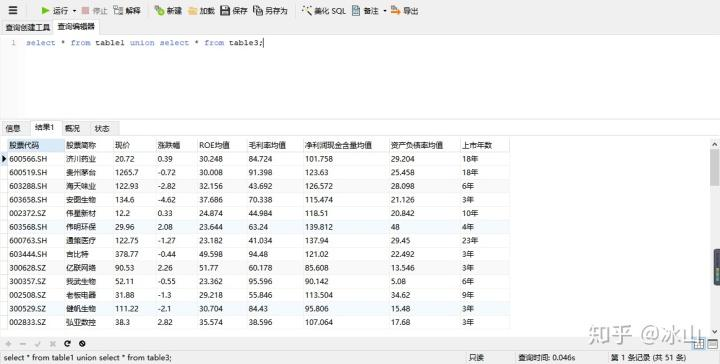
table1有35条数据,table2在table1的基础上增加了16条共51条数据,使用union将两张表进行组合会去除其重复值,最后只显示51条数据。
2)保留重复值:
select * from table_name1
union all
select * from table_name2
select * from table1
union all
select * from table3;Navicat for MySQL运行结果如下:
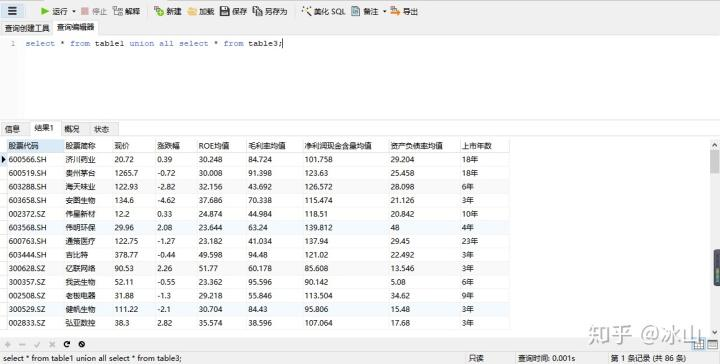
union all保留了两张表中共有的数据,所以最后显示有86条数据。
公众号:「Python编程小记」,持续推送学习分享,欢迎关注!