正负样本不均衡
样本不均衡
类别不均衡是指在分类学习算法中,不同类别样本的比例相差悬殊,它会对算法的学习过程造成重大的干扰。比如在一个二分类的问题上,有1000个样本,其中5个正样本,995个负样本,在这种情况下,算法只需将所有的样本预测为负样本,那么它的精度也可以达到99.5%,虽然结果的精度很高,但它依然没有价值,因为这样的学习算法不能预测出正样本。这里我们可以知道不均衡问题会导致样本较少那一类的高错分率,即较少一类的样本会有较大的比例会被预测成样本数量较多的那一类。
随机森林更适用于样本不均衡问题

降采样( 优 先 选 择 \color{red}{优先选择} 优先选择)
原来990个正样本,10个负样本。抽取50个正样本,10个负样本使样本比例在一个数量级。
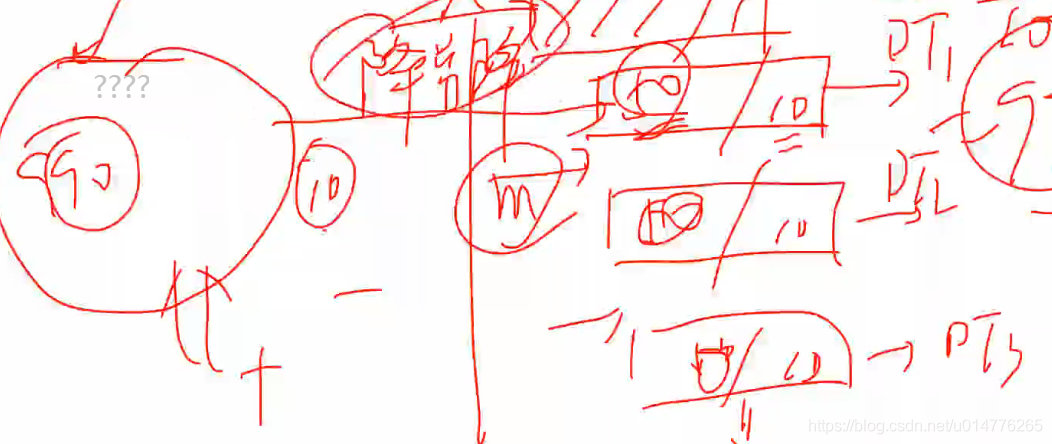
重采样
990个样本不变,10个样本 重复采样50次。获得990个正样本,500个负样本。
10
个
负
样
本
,
可
能
会
有
异
常
值
。
1
个
负
样
本
异
常
值
,
采
集
50
次
,
就
有
50
个
异
常
值
。
故
降
采
样
质
量
好
。
\color{red}{10个负样本,可能会有异常值。1个负样本异常值,采集50次,就有50个异常值。故降采样质量好。}
10个负样本,可能会有异常值。1个负样本异常值,采集50次,就有50个异常值。故降采样质量好。
降采样50个正样本,10个负样本,共60个样本。
重采样990个正样本,500个负样本。共1400多个样本
故降采样
效
率
高
\color{red}{效率高}
效率高。

基于聚类的A类分割
对于990个正样本做cluster聚类处理。之后对于每个类,抽取一定比例正样本。可提高训练程度。

B类数据合成
实现小类扩充。将两个点连线,随机设定一个比例,在线上生成一个新数据。从而扩大样本
代价敏感学习

提高小类权值,降低大类权值。
逻辑回归使用来实现
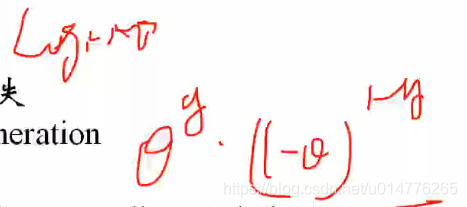
人工增加权值
