RPC项目
-
给我简单介绍下你的项目?
本项目基于Netty、Spring、Zookeeper实现了一个简单的RPC框架,可以支持服务器与客户端之间的长连接,支持心跳检测,采用JSON实现编解码,基于Spring注解进行动态代理的实现调用,最后通过Zookeeper的Watcher机制实现了客户端连接的监控、管理和发现等功能,并实现了服务注册的功能。
-
你的项目的流程给我介绍一下
首先需要启动Zookeeper服务器,然后通过spring启动RPC的server,此时Rpc的server会把自己注册到Zookeeper中,在Rpc 的server启动过程中,会采用ApplicationListener的监听机制完成server的初始化,之后通过BeanPostProcessor将服务器被自定义注解标记的bean及其方法以类名加方法名的方式存进一个Map中,方便后续客户端启动后的调用
客户端的的启动类为TcpClient,通过该类的静态方法实现netty客户端的初始化,同时客户端会向zookeeper获取服务器列表与服务器相连,在启动过程中,会对指定的方法完成动态代理,因为rpc的本质就是向调用本地方法一样进行网络通信,所以动态代理的目的就是完成通信过程中的配置,比如将调用方法和要传递的参数封装成一个request发送给服务器,从而实现对调用者隐藏通信细节的目的。最后基于Zookeeper的watcher机制完成了客户端对服务器节点的监视功能
-
你的项目的架构是怎样的?
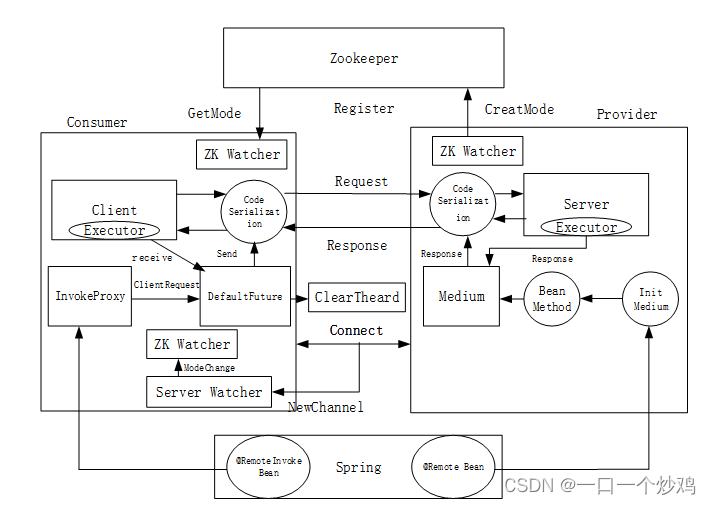 你的项目具有哪些特别的点?为什么要做这个项目?
你的项目具有哪些特别的点?为什么要做这个项目? 传统的curd项目技术含量比较低,对于技术的追求才想做一个rpc项目,可以把平时学到的技术运用到里面,于是基于netty和rpc框架的学习,做了一个简易的rpc项目
-
你知道dubbo么?那你的项目和dubbo有什么区别?x
Dubbo是阿里开发的一个rpc框架,这个项目算的上是dubbo的精简版,例如项目只支持JSON的序列化,dubbo支持的序列化形式更多更全面;项目只使用netty+spring做服务器,而dubbo的服务器支持tomcat、netty等容器,另外,该项目的动态代理使用的是spring的动态代理,dubbo则是使用的javassist。
- 短链接,长链接:
由于采用TCP作为传输协议,如果采用短链接的话,频繁的创建和断开连接会有很多网络消耗,这和预期的高性能RPC并不符合
长连接的实现主要通过zookeeper,服务器节点会被注册到zookeeper中,客户端每次获取服务器地址时,会把返回的ChannelFuture存在一个set里面,每次发送请求都从set中取出ChannelFuture发送消息,并且发送消息后不关闭连接,这就保证了客户端和服务器之间的长连接
- 基于TCP 还是http,为什么用TCP实现
基于TCP实现,因为http协议本身是无状态协议无法对客户端的请求和响应进行关联,并且http数据包较大,并不符合高性能RPC的预期,且TCP是可靠的网络传输协议,能保证数据正确性
-
同步阻塞调用性能瓶颈:有什么瓶颈? X 你怎么解决的,怎么实现异步调用的?
同步阻塞的缺点是调用线程会阻塞在请求中,cpu并不会切换到其他线程,如果服务器一直不返回消息,客户端就会一直被阻塞,并且同步阻塞会使线程数和客户连接数是一一对应的关系,需要频繁的创建新的线程,而线程又是java中比较珍贵的资源
Netty本身就是基于Nio开发的非阻塞的IO,本项目也是采用netty作为通信框架
-
为什么需要心跳检测,客户端发送请求服务端没回应会造成什么(X)?心跳检测机制你是怎么实现的?(X)
心跳检测主要是为了增加该rpc项目的可靠性设计的,因为一般晚上不会有太多的业务请求,如果此时客户端出现了故障,等到第二天大量的请求就可能呢会冲垮客户端的连接,导致大量的请求出现无法响应的情况。
心跳机制的实现通过netty自带的idleStateHandler以及重写userEveentTriggered方法实现的,在读写空闲时设定向已连接的客户端发送ping消息,如果客户端能及时返回ping消息,说明客户端连接正常,如果读写空闲甚至到了读空闲仍没有接收到客户端发送的ping,说明该客户端的连接出现了问题,服务器就会关闭和该客户端的连接,客户端需要在断线后进行重新连接。
-
什么叫做序列化?Java原生序列化问题(-)?为什么用JSON,怎么实现的JSON序列化,和JAVA序列化速度的差异?(x)
网络只能传递二进制数据,并不能以对象的方式传输数据,序列化就是一种把对象转成二进制数据的算法,并且这种转换是可逆的。
Java原生的序列化最主要的问题就是不能够跨语言,并且序列化的性能低,序列化后的文件大小比较大
JSON是一种Key-value类型的,典型的文本型序列化框架。
JSON序列化是通过FastJson框架实现的,把对象转换成json格式的数据
使用FastJson框架实现Json的编解码速度会比java原生序列化方式要快,且序列化后的码流也比较小
-
为什么用JSON,应该还有其他更快的吧?(-)
比较常见的还有protobuf、protoStuff、Hession,序列化性能更好并且数据报更小,protobuf有自己的数据类型和格式,使用时需要自己写IDL文件,并通过相对应的程序转换成Java对象的格式,比较麻烦,但可以跨语言并且性能很好。
Hession并没有那么麻烦,并且序列化性能比Json和java原生的序列化性能更好,比较适合rpc框架,但是并不支持java全部的数据类型,例如LinkedHashMap等
-
你还知道哪些序列化的方式?
还有facebook的thrift,JBoss Marshelling
-
你是怎么基于动态代理进行的请求处理?用的哪一种?为什么使用这种?(X)
使用Spring 的CGLIB进行动态代理,在interruput方法中对方法进行横切扩展,主要是将请求参数封装成一个ClientRequest类,并使用Netty将请求发送出去。
Spring Cglib的好处是可以对类进行动态代理,而jdk的动态代理只能针对接口
-
解决进程通信问题这个我不太懂,你的项目哪里遇到进程通信问题了? (X)
客户端发送大量请求的时候,服务器的响应可能会产生并发问题,导致出现进程通信问题。
-
你是怎么解决进程通信问题的?(X)
通过引入wait和notify机制,使用可重入锁ReentrantLock和Condition进行控制
-
首先创建锁
-
在主线程获取结果前,先等待结果
-
在获取结果前,先加锁,防止多线程同时获取结果
-
如果没有获得结果,则进入Condition等待,并在finally中释放锁
-
当客户端接收到服务器的响应时,唤醒锁
-
-
你还知道哪些解决进程通信问题的方式?
可以使用锁粒度比较大且并发效果不太好的synchronize锁,volatile、乐观锁CAS机制
-
TCP/IP 拆包粘包能简单介绍下么?你怎么解决的呢?有没有更好的解决方式?(X Header Body)
TCP协议是基于流的协议,没有消息边界,客户端发送数据时,为了减小通信消耗,可能会将多次发送的数据组合在一起发送,这就是粘包,当要发送的数据太大导致数据包分片时,服务器一次只能获取部分数据,这就是拆包
有几种解决办法
-
可以使用消息包定长的方法解决,长度不足的使用空格补上
-
使用特殊分隔符结尾的方式,分隔符标识消息包的结尾,区分整个数据报
-
在消息头标识数据包的长度,可以通过获取指定字节数的方式获取完整的消息包
-
-
你是怎么基于BeanPostProcessor 机制和 ApplicationListener 机制实现客户端的自启 动与基于注解的服务调用
BeanPostProcessor的使用,首先在要调用的属性上加上一个自定义注解RemoteInvoke,通过BeanPostProcessor的postProcessBeforeIntialization方法首先扫描到整个带有RemoteInvoke注解的属性,之后在调用该属性的具体的方法时,使用request封装该属性也就是对象的限定名和方法名以及方法参数发给服务器,指定需要调用的方法,之后服务器接收到这个request对象,并且服务器在启动时也会通过自己的自定义注解把所有属性以及对应的方法封装到一个hashMap里面来,在收到客户端request时在hashMap中查找对应方法并执行该方法,之后返回给客户端执行后的响应结果
ApplicationListenser会监听服务器初始化完毕,并监听所有的ContextRefreshedEvent事件,ApplicationListenser通过onApplicationEvent方法处理事件。
首先客户端类TcpClient的静态代码块会初始化一个netty客户端,因此在BeanPostProcesser中完成请求的包装后,调用TcpClient的send方法完成客户端的初始化
而服务端则将初始化代码放在一个start方法中,同时服务端实现了ApplicationListener<ContextRefreshedEvent>接口,并在onApplicationEvent方法里调用服务端的start方法,这样在Spring启动完成后,监听器监听到ContextRefreshedEvent事件后会触发server的初始化
基于注解的调用方面,我在service的实现类上标注了一个自定义注解@Remote,同时在Spring启动过程中服务器端会有一个BeanPostProcessor,对被@Remote注解标注的类进行处理,主要是将service接口的各种方法与接口进行映射;而客户端则对service的接口标注了同样是自定义注解的@RemoteInvoke,同样BeanPostProccessor的实现类会对被@RemoteInvoke标注的接口完成方法和接口的映射,这样服务器的map和客户端的map里关于方法和类名都是一致的,因此服务端知道该怎样调用方法
-
注册中心你是怎么实现的?用的什么?
注册中心使用的是zookeeper,对每个服务器以ip加端口的形式设置一个序列号,每次启动服务器都会注册到同一个路径下,保存该服务器的ip和端口号
-
为什么用Zk?(X)
Zookeeper的特性就是强一致性,可以在服务器下线时立即检测出来,并且zookeeper的curator的watcher机制可以实现客户端连接的动态管理、监听和发现功能
-
你的服务结点结构是怎样的?
路径+Ip地址+端口号
-
那么当有新的服务上线或者旧服务下线的时候,你怎么保证得到最新结果?(X)
我在客户端添加一个curatorWatcher对象,重写它的process方法,当zookeeper管理的服务器上线和下线时,zookeeper会立即感知到这种变化,并执行curatorWatcher的process方法进行处理。
-
客户端怎么发现服务?
通过获取zookeeper的client对象,查看注册到zookeeper的服务器,采用轮询的方式向服务器发送请求
-
怎么动态监听链接?(X)
使用ChannelManager管理所有连接,当zookeeper注册的服务器下线后,触发watcher的process方法,在这个方法中,我们清理ChannelManager中所有的连接,并获取zookeeper现有的所有连接,重新按着现有的服务器,进行业务请求
-
给我讲一讲Watcher机制 ( X )
Watcher是在服务器初始化时添加的会监听zookeeper中服务器状态的变化,当有服务器下线或者上线时就会调用watcher的process方法,我们可以重写这个方法,实现业务需求
构建一个CuratorWatcher的实现类ServerWatcher。当客户端启动时,将watcher注册到自身的Curator上,并让其监视的zookeeper的/netty目录节点,当该节点有变动时就会触发ServerWatcher重写的process方法,这个方法里清除之前保存的服务器的信息,获取新的服务器列表
由于一个watcher注册一次只会监听一次,所以在process方法里需要再次注册watcher到Curator上
(1) 给我讲一讲你项目中你认为最难的点以及你的解决方式?
项目的难点就是怎么通过一个接口实现远程调用,动态代理类怎么写。我选择在接口上添加一个自定义注解,并在BeanPostProcessor类中的postProcessAfterInitialization方法中是扫描这个注解,之后通过代理类BeanPostProcessor发送request的方式实现远程调用
(2) 你的项目有哪些改进地方?你想改进哪里?
需要改进的地方在于序列化方式单一,我想以后根据不同的请求参数,选择不同的序列化方式
(3) 你这个项目的创新点有哪些?
并没有单纯基于netty做rpc框架,而是引入了spring、zookeeper等开源框架完善项目的功能
(4) 做这个项目的意义是什么?
做项目的整个过程,使我对Spring、netty和RPC框架有了一个整体的了解,巩固了java基础知识,增强了自己实战经验,提高了发现问题、解决问题的能力,对以后从事java相关工作有很大的帮助。
(5) 项目的性能如何?哪些地方可以继续优化从而提高性能?
经过测试,5秒可以完成一万次请求,十万次请求需要25秒,100万次请求需要160秒使用的是12核32G台式机