备战双十一·尖货优品实时选技术
1. 双十一背后的技术
双十一是全国人民的购物狂欢节,但是对于阿里技术人而言,双十一则是一年一度的大考,技术人穷尽一切办法保障极致的用户体验和稳如泰山的可靠性,从底层网络、基础架构、容量规划、性能优化到个性化推荐,智能搜索,复杂营销玩法,整个技术支撑体系的每个层面都不断演进和诞生大量技术创新。 弱水三千只取一瓢,如果你关注双十一,你会发现有大量的类似下面第一张图的“运动尖货”会场页面,这类会场有两个特点:
-
特征相似。(例如图1的都是运动类商品)
-
千人千面。(每位用户看到的商品都是个性化的,进而最大化提升成交概率) 如何从数亿商品中精准的选出满足会场诉求的商品,并且以个性化的方式投放给消费者,最终实现成交概率最大化?背后的技术支撑系统我们称之为“选品投放系统”,本文主要介绍闲鱼选品投放系统的技术演进,希望能给你带来一些解决这类问题的思路。
-
2. 闲鱼选品系统演变
2.1 选品系统解决的业务问题
闲鱼商品跟大多数电商系统类似,都存在三个核心环节:
-
商品发布,卖家将需要售卖的商品发布到平台。
-
商品展示,平台通过各种途径将合适的商品展示给合适的买家,买家通过商品浏览形成购买意图。
-
商品交易,卖家确定购买意愿后,下单购买商品,商家发货,以及售后等完成钱物交换的所有环节。 选品系统解决的问题主要集中在商品展示环节,尤其在类似双十一这种大型的活动中,选品系统能够将运营同学对行业深入理解跟算法个性化进行有效的结合,构建大量的会场和频道,精选出优质的商品呈现给消费者。
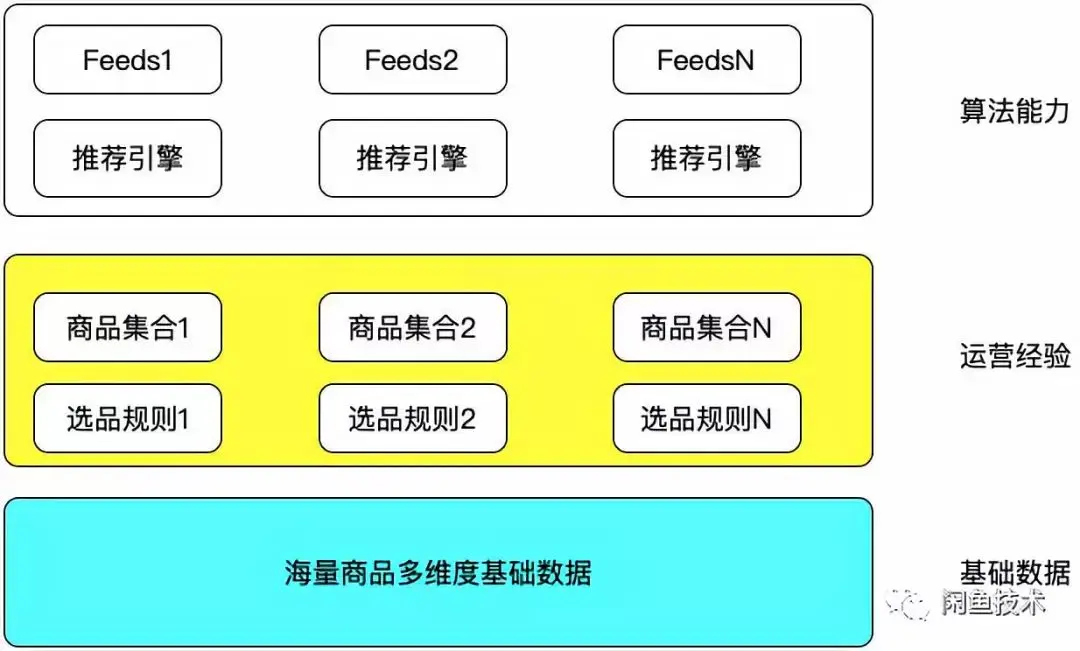
选品系统大体上分为上图所示的三层。
-
基础数据层。所有的商品相关的数据,其来源极为丰富,可能是卖家发布的商品基础信息,例如品牌,尺寸;也可能是算法对商品的理解和分析,例如图片质量,商品质量;也可以是统计维度的数据,例如商品浏览量统计,商品好评率统计等。通常,基础数据层的数据量级决定了后面技术架构的选型。
-
运营经验层。运营通过设定各种不同的选商品的规则(简称:选品规则),从海量商品中选出体现其意志的商品集合。例如运动尖货会场,运营可以按照运动品牌品牌,优质卖家等作为选品规则来圈选出运动尖货的基础商品集合。通常,这个集合的数据量级已经比基础数据减少了几个数量级。
-
算法能力层。在运营选出来的商品集合中,通过推荐引擎,结合用户个性化信息进行商品推荐产生用户看到的会场页面的Feeds流。算法能力层核心就是对运营圈选出商品集合中的商品通过不同的排序算法策略,将对用户而言最可能产生购买意图的商品排在前面。
针对闲鱼的业务场景有一个不同于其他电商的显著的特征:闲鱼商品都是孤品,一旦有人购买,商品就不能再继续售卖,需要从feeds流中排除;同时,新发商品或者商品本身特征的变更,一定要即时影响到下游选品结果集合。总结而言,闲鱼选投系统的核心差异化诉求就是:秒级实时性要求 。
2.2 基于搜索的选品实现
闲鱼早期,同很多初创公司一样,平台上的商品数量比较少,也没有专业的算法团队,但是选品诉求依然大量存在,例如,6月份大学生毕业的时候,组织“毕业季”活动,选品条件是:卖家身份是大学生,商品标题包含“毕业”,商品属于书籍,电器,服装等品类,价格在300元以下。买家浏览的feeds的排序条件是按照距离远近排序,优先看到距离自己最近的。 在当时的闲鱼技术架构下,搜索几乎是所有feeds类页面的数据源提供者,选品,自然而然的就是基于搜索来做。
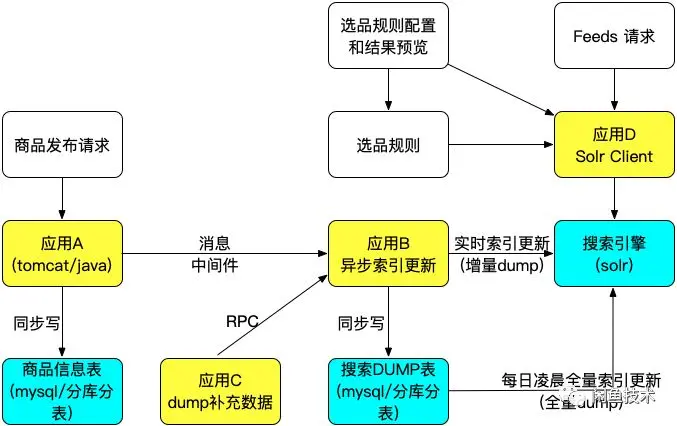
-
用户发布商品后,完成商品库写入后,引用发送异步消息给消息中间件,消息中间件采用阿里现在已经开源的RocketMQ[1]。
-
应用B接收消息中间件的消息后,会从其他应用通过rpc调用获取dump表所需的商品基础信息外的补充信息,并且进行一些数据转换,合并等动作后组装成用于更新搜索引擎的数据结构,先写入mysql承载的搜索dump表中,然后通过http接口调用搜索引擎暴露的实时索引更新服务进行索引实时更新。
-
每晚,定时调度任务还会触发搜索的全量dump,就是把搜索dump表中的数据拉取到引擎侧,然后完成全量索引构建和线上版本替换的工作。
-
建设后台运营选品页面,将搜索可以支持的条件构造成一个表单,运营同学可以在表单上选择和组装条件,并且预览组装条件下的选品结果,调整满意以后,就可以保存搜索条件发布到生产系统。
-
前端页面的feeds请求,则是基于选品配置的id来获得选品规则,翻译为搜索查询串,发送请求给搜索系统获得feeds结果。
搜索引擎选择Solr,除了当时业务量小外(数据量,查询qps都不高),主要是由于当时公司内有个团队基于solr构建了一套针对中小数据量业务的搜索平台,直接接入节省了很多运维和可靠性保障的工作,搜索引擎可以选择ElasticSearch或者其他顺手的搜索引擎。
前面提到,闲鱼商品孤品特性要求我们选品平台一定要满足实时性,在这个阶段,我们保证实时性的最核心动作就是优化实时索引更新可见的时延,原生solr当时在实时索引更新上还存在诸多问题,搜索团队进行了很多优化工作,详细可以参考这篇文章的分享[2],最终我们做到实时索引更新到前台搜索可见时延在100毫秒。
虽然这个选品的架构略显简陋,但是在很长一段时间内支撑了我们的选品诉求,而且即使到现在,这种架构对于中小型的公司,依然具备参考价值。
在阿里内部,依然有很多基于搜索的选品平台存在,一般都会结合算法推荐层来构建,搜索引擎承载的核心作用是:
1. 基于条件的选品结果实时预览
2. 基于条件导出给算法用的商品集合
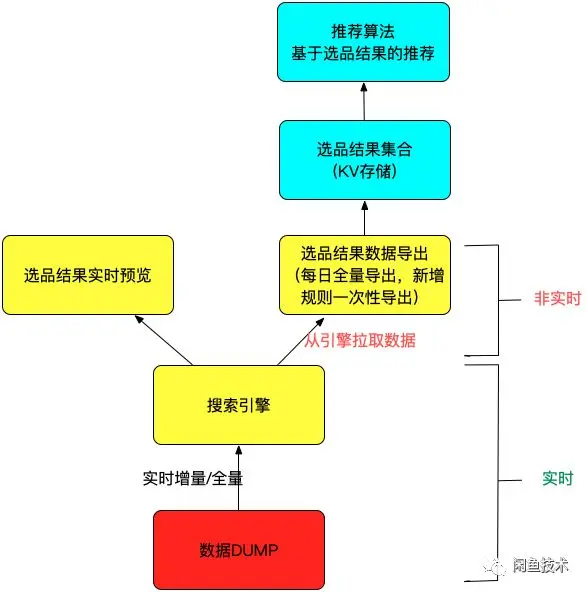
通过将选品结果集合从搜索引擎导出,写入到KV存储中,推荐算法在进行推荐的时候,从这个结果集合中做数据召回,然后再结合用户行为和其他算法数据进行排序。算法模块的详细工程支撑,将在下文介绍。 注意这个架构示意图中红色字体部分,选品结果数据导出是采用拉的模式,意味着选品结果集合的kv存储的更新只有两个途径:
-
当新建或者更新一个选品规则的时候,触发系统从引擎拉取规则命中的数据写入到KV存储中。
-
每天凌晨业务量低的时间段,定时调度任务将生产环境配置的所有选品规则执行一遍,并将结果写入到KV存储中。 这就意味着,商品上新的变更是无法实时更新到选品结果集合中的,几种可能解决思路:
-
定时的全量执行数据导出。不可行,因为全量导出数据量大,执行时间长,对系统压力大,而且无论如何都做不到秒级全量持续导出和重算。
-
增量数据导出。不可行,以为引擎本身是实时更新的,即便相同规则,基于索引时间戳的增量召回也可能导致数据重复,而且当规则多的时候,性能上也会快速出现瓶颈。 闲鱼对选品秒级实时性要求的特点,决定了这种模式的的选品方案对闲鱼是不可接受的。但是对于商品库存多,商品变化比较少,对实时性要求不高的电商系统,这种方案完全满足业务诉求,读者可以思考下即便多库存,依然可能存在商品售罄,被处罚导致的下架的情况,这些情况下如何保证最终投放给用户的feeds中有效剔除这些商品?
2.2 基于离线计算的选品实现
我们把类似搜索引擎提供的在线实时数据查询服务称为在线服务,那么离线计算是指基于大数据计算平台,通过提交计算任务,完成大规模海量数据的复杂计算和计算结果的产出。
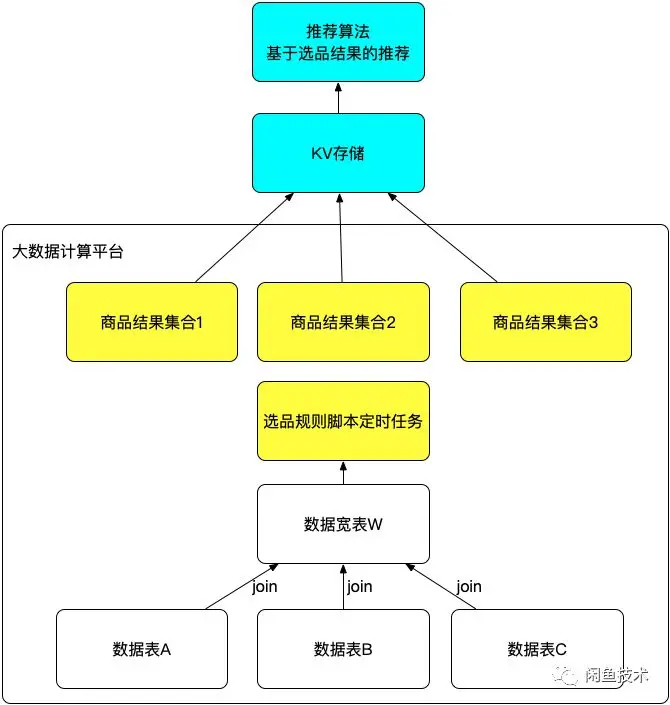
这种架构下,核心的计算逻辑全部在大数据平台上通过定时任务来执行所有的选品规则,可以充分发挥计算平台的能力,执行超大规模和复杂度的计算,不需要额外搭建搜索引擎等辅助系统。 大数据计算平台有很多种,阿里内部目前主要使用的MaxComputer平台[3],当然也可以自建Kafka(数据采集通道)+Hadoop集群+Hive(SQL查询)+spark(可编程访问及批处理)这样的大数据系统,用于支撑海量数据处理。 显而易见,这种模式下,依然很难满足闲鱼秒级实时性要求。
2.3 实时选品系统的核心链路及其技术挑战
总结前面两种不同选品方案,要实现满足闲鱼业务诉求的实时选品系统,可以归纳下面的核心链路。
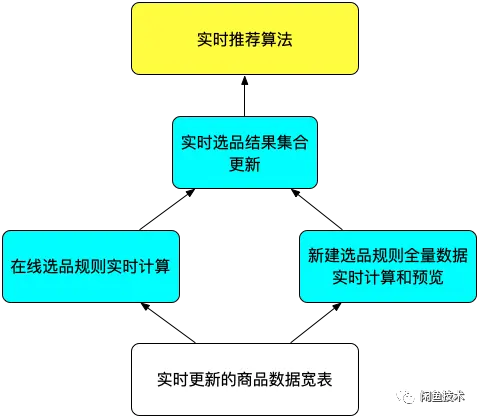
-
实时更新的商品数据宽表。 宽表的含义是列特别多的表,需要把各种数据源产生的可以用于选品规则计算的数据,以独立列的形式实时写入到这张宽表中。
挑战1,需要支持独立字段级别的增量和全量数据合并。 因为选品平台数据源来源多样,并且产出时间不一。
例如闲鱼商品发布过程中不强制要求用户选择类目信息,而是基于用户的输入的标题描述和图片,通过在线算法服务进行实时类目预测,但是在线类目预测算法是以牺牲精准度来保证实时性的,因此,算法通过离线大数据计算平台,每天还会进行全量商品的类目高精度重新预测,这是每天原始数据要进行全量和增量两种模式导入选品数据宽表的原因,是兼顾数据一致性和数据实时性的解法,大部分的实时搜索引擎都是采用类似的解法,全量和增量数据dump相结合的方式来完成索引数据和db数据的同步及实时更新。 只要存在增量和全量更新,就必然存在增量和全量数据合并的问题。
搜索引擎的常见解法是,两个在线服务引擎,引擎1采用实时增量模式运行,引擎2完成全量数据dump后,根据全量数据最晚时间戳,将时间戳之后收到的增量变更消息进行回放来更新增量索引,直到增量数据追平引擎1的增量消息时间戳,然后线上服务执行引擎切换,引擎2提供线上服务,引擎1执行引擎2完成的全量和追增量动作,这种模式能保障线上服务的基础上,完成全量增量的数据合并。但是根据前面的介绍,我们直接用搜索作为选品引擎是是无法满足实时选品诉求的,而其他的数据库不具备这种线上切换索引的能力。
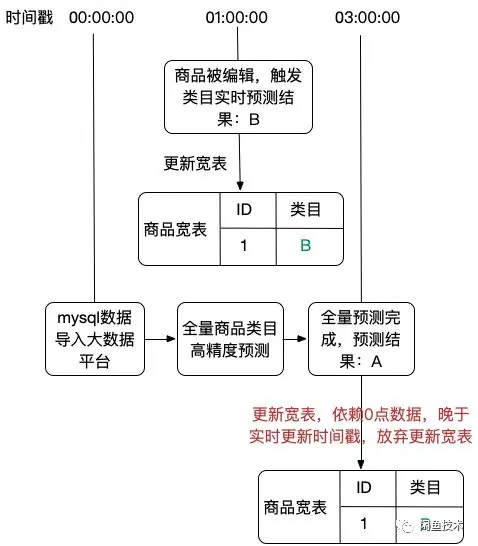
上图展示全量和增量数据在某个字段上叠加冲突的情况,当全量预测完成后执行宽表数据合并的时候,需要能够准确判断类目这个字段的增量和全量如何更新。 挑战2:亿级全量数据更新带来的对宽表的超高写入速度(20W+),读取速度(20W+)。计算公式:10亿数据1小时内完成更新,tps27W。
-
在线选品规则实时计算。 任何一个商品上的任何一个字段的变更,都需要参与选品规则的计算,来决定当前规则是否依然满足条件,进而决定下游选品结果集合是否需要更新。
挑战3:选品规则执行效率。
-
新建选品规则全量数据实时计算和预览。当新建或者修改选品规则的时候,需要能够对所有商品基于新的规则进行计算,获取满足规则的商品集合。这里的要点在于,全量商品的计算需要秒级完成计算,并且全量数据本身是实时数据。
挑战4:无法使用搜索引擎的情况下,大数据计算平台通常无法达到秒级多列复杂计算,应该选择什么解决方案?
-
实时选品结果集合更新。
挑战5:给算法使用的选品结果往往通过kv存储承载,规则计算完成后,如果需要读写kv存储,按照每秒20万TPS,1000条规则计算,则tps是20万*1000,目前没有能够承载这么高吞吐量的kv系统。
-
实时推荐算法。
挑战6:推荐算法基于选品池数据进行推荐,但是我们最常用的基于用户行为的i2i协同过滤前提是大量关联商品的推荐,一旦圈定到小的商品池,大概率出现召回阶段数据为空的问题,导致i2i失效。 挑战7:如何将离线的非实时更新的i2i,u2i等数据,实现在线化。 挑战8:如何实时采集线上数据,实现基于实时数据的模型在线训练和实时预测。
2.4 采用PostgreSQL的尝试
根据2.3的选品系统的核心诉求,能够同时支持OLTP和OLAP的PostgreSQL首先进入我们的视野。
-
高速的写入和查询速度,集群百万QPS。
-
天然支持JSON格式数据,可以采用KEY:JSONVALUE的的两列模式,保证基于key的快速查询,同时配合特殊设计的JSON格式和自定义数据合并UDF来支持字段级别的增量全量合并。
-
基于PostgreSQL的触发器来实时触发规则计算,规则通过自定义函数实现,参考资料[4]。
-
规则计算结果通过postgresql的notify机制发送通知消息给下游推荐或者搜索系统。
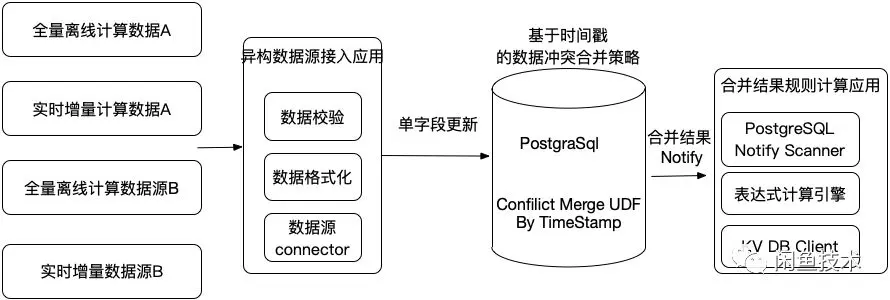
这个系统基本实现了设计目标,并且支撑一些业务场景,但是存在3个严重的问题:
1. 数据合并UDF执行完毕以后,需要定义触发器(trigger)来发送notify消息,当trigger数量增加的时候,系统性能急剧下降。以25万条数据写入,50个trigger执行耗时1052秒(17分钟),每日全量数亿数据写入的话,需要一百多个小时才能完成一次全量,已经采用了物理硬件顶配,目前没有找到可提升的空间。
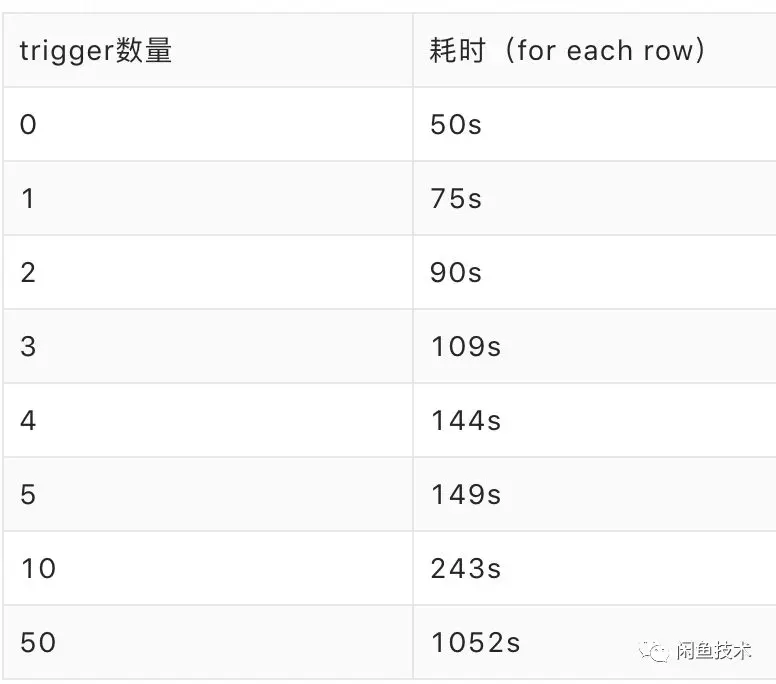
2. Notify通知机制是采取client拉的模式,而且client端无法做到微服务集群内的互斥,需要业务做大量的工作来保证消息不重复消费和集群内只消费一次。
3. 采用KV存储模式下,执行数据预览和检索性能也急剧下降,无法支撑实时预览和新增规则导出的能力。 基于这些问题的约束,PG的方案只是小规模用在少量场景上,没有作为闲鱼实时选品系统的最终方案。
2.5 采用实时计算平台的尝试
当商品数据字段发生变化的时候,触发规则实时计算,这本身就是个典型的事件驱动型实时处理流程,Blink是阿里实时计算团队在Flink的基础上打造的一套通用实时计算平台,并且做了很多能力增强。同样是实时计算框架,简单对比下storm和spark。
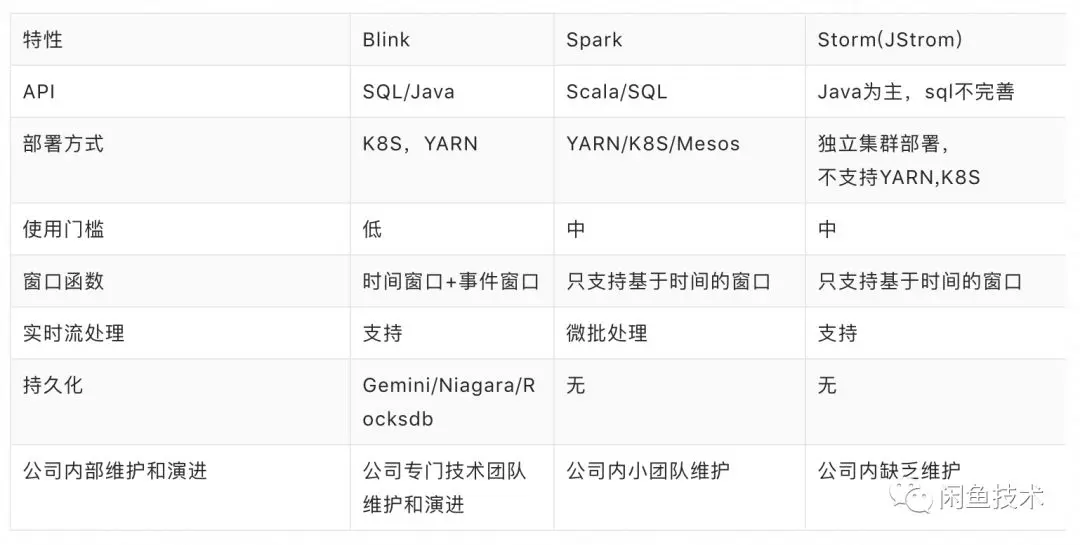
在选型的时候最关注三个点:
-
是否支持实时流处理,用来保证延时。
-
是否有本地存储,高性能宽表增量和全量merge,高性能实时写入选品集合的都依赖这个。
-
后续升级维护成本,有专门团队维护和演进对后续运维成本会产生巨大影响。
从上面三个维度看,Blink是最好的选择。
那么面对前面2.3节中提到的技术挑战,在Blink上是怎么解决的呢?答案是:依赖Blink statebackend机制。
首先先介绍下Blink的statebackend机制,那么到底什么是State?
State是指流计算过程中计算节点的中间计算结果或元数据属性,比如在aggregation过程中要在state中记录中间聚合结果,比如Apache Kafka作为数据源时候,我们也要记录已经读取记录的offset,这些State数据在计算过程中会进行持久化(插入或更新)。总结而言Blink中的State就是与时间相关的,Blink任务的内部数据(计算数据和元数据属性)的快照。
目前Blink支持的state持久化引擎包括
1. Gemini,高性能内存statebackend,相对于niagara/rocksdb减少了序列化以及JNI的开销,state读写速度更快,CPU消耗更低,但是因为在内存中,对数据大小有限制,峰值checkpoint size不超过(并发数 * 200)MB。
2. 基于RocksDB的RocksDBStateBackend,本地文件+异步HDFS持久化,flink原生,相对较慢。
3. 还有一个是基于阿里自研的Niagra,StateBackend,分布式持久化,阿里自研,比RocksDB快很多。 那么具体怎么使用statebackend机制解决前面的性能挑战呢? 根据前面的介绍,在执行aggregation的过程中,会启动State存储,我们通过自定义UDAF(用户自定义聚合函数)来触发state存储。UDAF写法:
复制代码
/* * @param <T> UDAF的输出结果的类型 * @param <ACC> UDAF的accumulator的类型。accumulator是UDAF计算中用来存放计算中间结果的数 * 据类型, 用户需要根据需要,自己设计每个UDAF的accumulator。例如,最简单的count UDAF, * accumulator就可以是一个只包含一个 */public abstract class AggregateFunction<T, ACC> extends UserDefinedFunction { /* * 初始化AggregateFunction的accumulator, * 系统在第一个做aggregate计算之前调用一次这个方法 */ public ACC createAccumulator(); /* * 系统在每次aggregate计算完成后调用这个方法 */ public T getValue(ACC accumulator); /* * 用户需要实现一个accumulate方法,来描述如何将用户的输入的数据计算,并更新到accumulator中。 * accumulate方法的第一个参数必须是使用AggregateFunction的ACC类型的accumulator。在系统运行 * 过程中,底层runtime代码会把历史状态accumulator,和用户指定的上游数据(支持任意数量,任意 * 类型的数据)做为参数一起发送给accumulate计算。 */ public void accumulate(ACC accumulator, ...[用户指定的输入参数]...);}
这三个函数就可以完成一个最基础的UDAF方法,createAccumulator方法在每个task启动的时候创建一个聚合器对象,然后当有新的事件产生以后,accumulate的第一个参数accumulator就会取到上一次计算的结果,在accumulate函数中完成新数据和上次聚合数据的计算。这个聚合器对象采用如下设计。
复制代码
{ "_mergeRes": { "original_price": [ 1541433610000, "84.37" ], "title": [ 1541433610000, "[转卖]卷发棒大卷神器电卷棒不伤发短发空气刘海内扣男士儿…" ], "category": [ 1541433610000, "50025437" ], "status": [ 1541433610000, "0" ] }, "_ruleRes": "4963_5:0;", "_changeFlag": "1", "_ruleDiff": "4963_5:0"}
-
_mergeRes字段,表示经过合并后的业务信息,当前在闲鱼使用场景代表的是商品信息。blink任务会将来源的商品信息与内存中保存的合并结果进行合并,_mergeRes就是合并之后的结果。 _mergeRes是key-value结构,value是数组,数组第0位表示当前属性变更的时间戳,第1位表示当前属性值。 _mergeRes数据最终写入petadata。 通过在每个字段携带自己的时间戳,把全量和增量消息都作为增量消息消费,只要每个字段包含了产生这个数据 的时间戳,那么就可以在这里完成准确的数据合并。这就解决了2.3中的挑战1。
-
_ruleRes 表示当前商品信息对规则的命中情况,0表示未命中,1表示命中。
-
_changeFlag 表示经过合并后商品信息是否发生变更的标记位,1-有变更;0-无变更。
-
_ruleDiff 将上次规则计算结果存储到State中,每次增量消息直接对规则匹配结果做diff,只有发生变化的规则结果才会以metaq消息的形式投递到下游,节省了大量的对结果池的KV调用判断,从而解决了2.3中挑战4.
-
Blink内置的高性能存储Niagara,解决了2.3中的挑战2。Niagara借鉴了Seastar[5]的架构,采用 thread per core的shared-nothing设计,线程锁竞争和切换的开销几乎为0,代码也不用考虑多线程竞争,是 逻辑大大减化;此外Niagara是一个全异步执行引擎,采用了基于future,promise和continuation的方式来表达异步执行逻辑。存储内核方面,采用LSM结构,从而能更方便的进行读、写和空间放大的调节。相比同是LSM架构的RocksDB,还做了多方面的优化来提升性能,包括:基于masstree[6]的memtable;Snow-shovelling的flush策略;自适应的扩层策略;实时in-memory compaction。
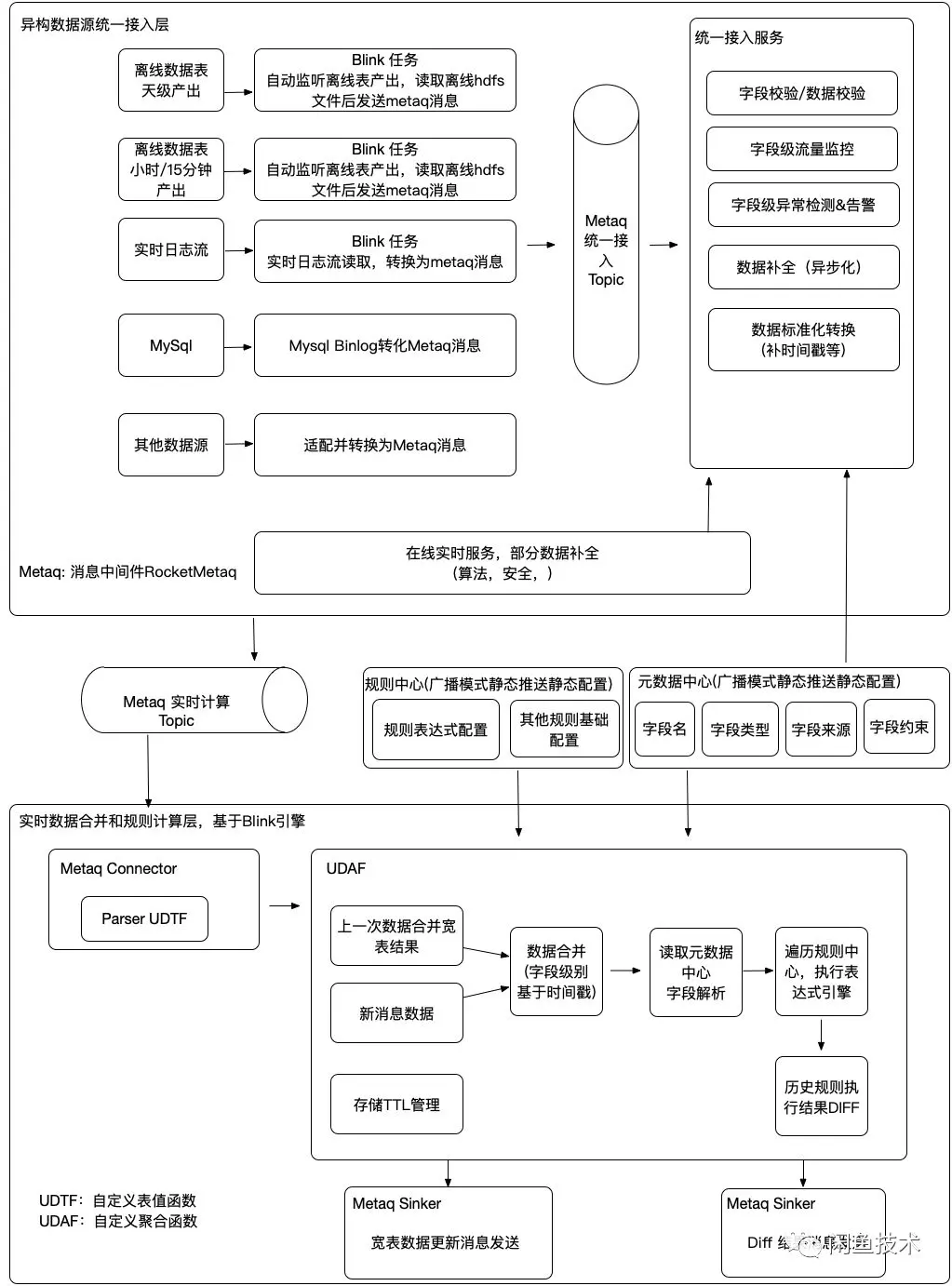
如上图所示,在进入Blink计算流程前,架设了一个异构数据统一接入层,主要负责各种不同来源的数据源标准化接入,例如有来自离线计算平台的全量数据,有来自日志系统的实时数据,有来自数据库监听的实时数据库变更数据,也有来自在线服务的调用,通过适配器将将各种来源消息归一化为Metaq消息,消息对象中抹平数据类型,通过元数据中心完成数据类型和校验规则的统一注册和管理,元数据中心同时服务于Blink实时计算任务,用于数据的解析,从而保证数据shchema的全局统一。
由于blink架构设计上,如果blink任务升级被停止,就会将所有的State存储数据失效,元数据中心的引入还可以保证宽表增加字段的时候不需要修改UDAF代码,只需要推送配置即可。 将全量数据和增量数据全部都以Metaq消息的方式进行接入,从而保证在blink的数据合并计算中,完全不需要考虑当前是什么类型的数据,只需要按照字段时间戳进行合并即可。新的宽表业务字段的接入,也不需要在离线计算层通过join表的方式,而是完全可以独立以消息的方式接入,规避了离线计算太多join依赖导致全量数据产出慢的问题。 采用消息中间件还有个重要作用是用于容灾,在极端情况下blink系统故障的时候,基于metaq消息位点的回放,就可以完整的将当天全量消息和增量消息全部重新灌入引擎,从而在小时级完成系统的恢复。 另外,提一下踩到的一个小坑,之所以把diff数据放到同一个聚合器对象中,可能存在数据过大的问题,曾经考虑采用两级Aggration的方案,但是因为实时流计算的retract机制,当State计数器减为0的时候,会导致State数据被清空。 对于表达式计算引擎,公司内部有些部门基于rete算法自主实现一些高性能表达式引擎,但是我们的表达式计算方式比较宽泛,使用自研的表达式引擎可能存在一些算子支持的问题。对比了目前几个主流的表达式引擎特点:
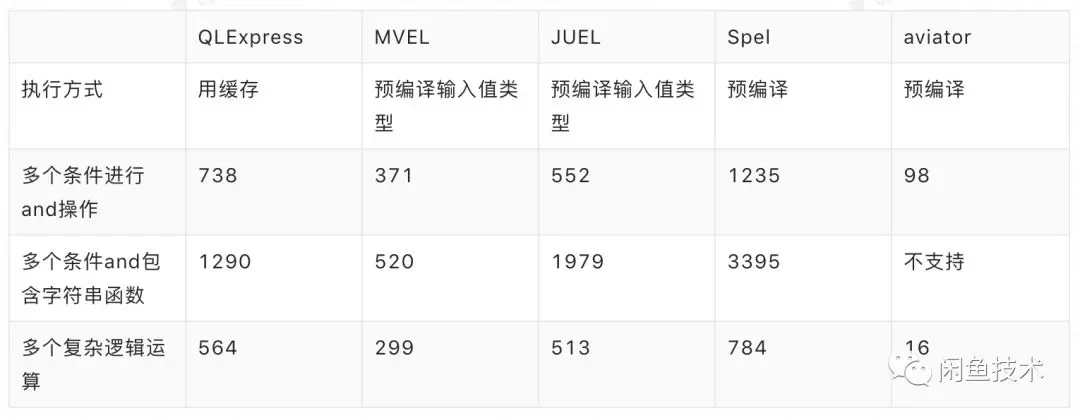
综合来看,我们们采用了MVEL引擎作为我们的表达式引擎。
2.6 实时全量选品和预览
实时全量商品实时预览我们选择阿里云自研的高性能OLAP数据库:HybridDB for MySQL[7],主要考虑其对万亿级数据毫秒级实时多维分析能力,另外就是它跟大数据平台MaxComputer以及Blink良好的兼容性。下图是描述了在新建或者变更选品规则时,通过数据增量数据双写,线上KV存储版本切换来实现线上业务无损切换流程。
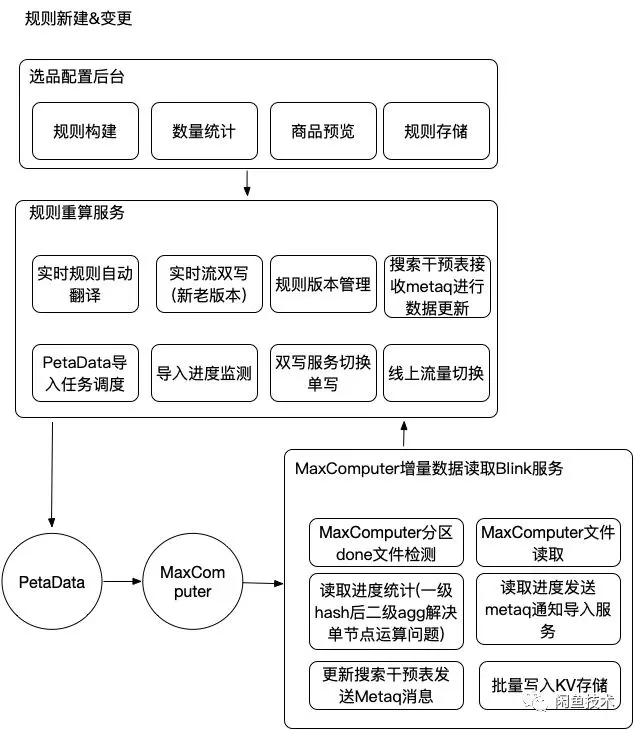
2.7 实时推荐层
实时推荐层实在太多东西,限于篇幅,本文暂时不再详细介绍,敬请期待下一篇文章详细介绍。
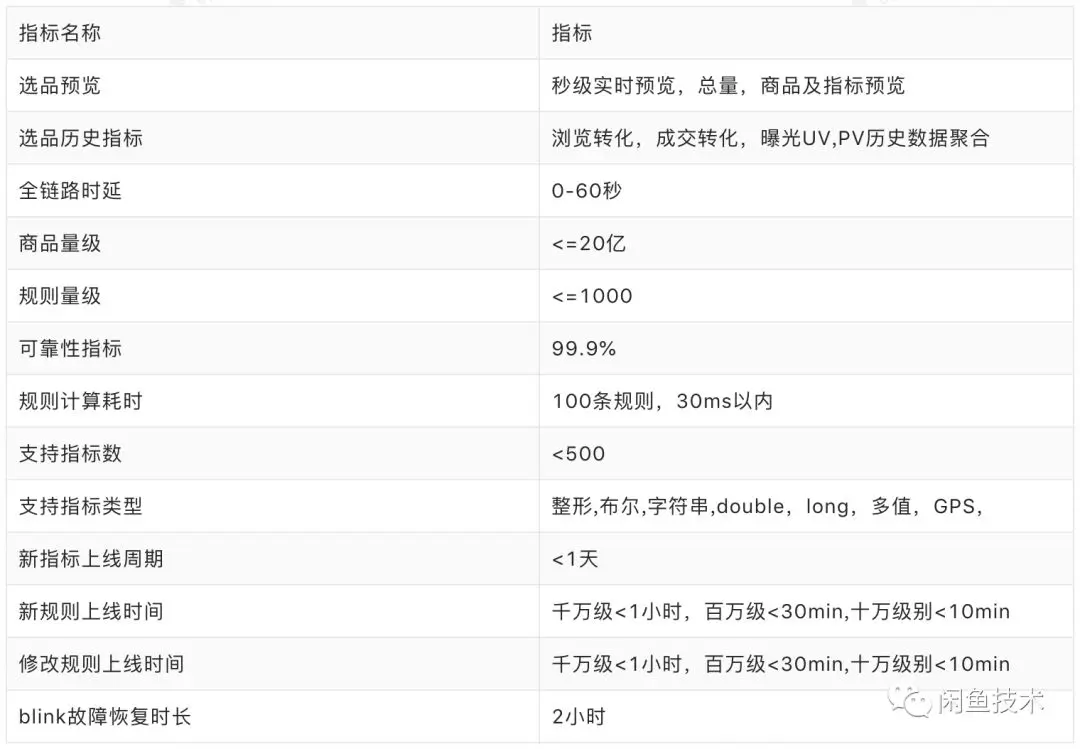
2.8 性能指标
我们将闲鱼的实时选品系统命名为,马赫(mach),对,就是音速单位马赫。
马赫已经承载了闲鱼线上几乎所有的在线Feeds类业务,包括外部投放的feeds类业务,已经成为闲鱼的基础设施。未来还会继续在系统极致性能,在线算法优化,系统稳定性,上游招商平台,下游投放平台等深度合作。
引用:
[1]RocketMQ: https://rocketmq.apache.org/
[2]一种基于Lucene的实时搜索方案:http://news.laiwang.com/message/news_view.htm?msg_id=82836187
[3]MaxComputer:https://www.aliyun.com/product/odps
[4]PostgreSQL Notify: https://www.postgresql.org/docs/current/static/sql-notify.html
[5]Seastar: http://www.seastar-project.org
[6]Masstree: https://pdos.csail.mit.edu/papers/masstree:eurosys12.pdf
[7]Hybrid for Mysql:https://www.aliyun.com/product/petadata