dpdk 对 numa 的使用与多 numa 架构下性能调优的基础
numa 是什么?
在 SMP 架构中,内存统一寻址(Uniform Memory Architecture),处理器和内存之间通过一条总线连接起来。由于所有处理器都是通过一条总线连接起来的,随着处理器的增加,系统总线成为了系统瓶颈,另外,处理器和内存之间的通信延迟也较大。为了克服以上缺点,NUMA 架构应运而生。
numa 架构全称为非一致性内存架构 (Non Uniform Memory Architecture),与 SMP 中的 UMA 统一寻址内存架构相对。在 numa 系统中有本地内存与远端内存的区别。访问本地内存有更小的延迟和更大的带宽,跨处理器内存访问速度会相对较慢一点,但是整个内存对于所有的处理器都是可见的。
numa 系统的一个示意图如下:
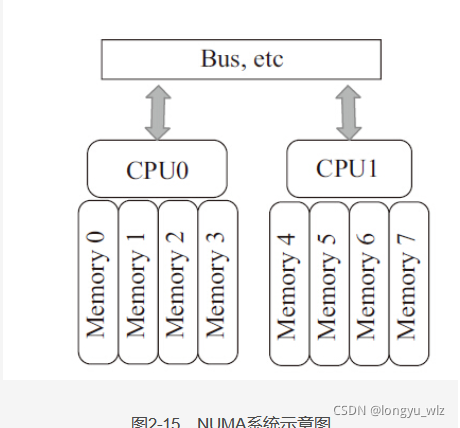
上图中有两个 cpu,CPU0 与 CPU1 都有自己的本地内存,访问这些内存的性能最优,这两个 cpu 也可以通过总线等架构跨处理器访问远端的内存,只不过性能相对会差一些。
如上信息与图片摘自《深入浅出 DPDK》。
dpdk-16.04 中对 numa 的使用
1. 如何获取 pci 网卡所在的 numa 节点?
linux 系统中 pci 设备会在 /sys/bus/pci/devices/ 中创建独立的子目录,目录名称就是 pci 设备的 pci 号。dpdk eal 初始化时,会扫描此目录来获取当前设备上所有可用的 pci 设备。每个 pci 设备所在的 numa 节点在 /sys/bus/pci/devices/xxx/numa_node 文件中保存,dpdk 通过访问这些文件获取到每个 pci 网卡的 numa_node 信息。
一个示例:
[root] # cat /sys/bus/pci/devices/0000\:80\:00.0/numa_node
1
dpdk 会为每个扫描到的 pci 设备创建一个 rte_pci_device 结构,并将解析 sys 目录得到的字段写入到此结构中,解析完成后将每个 rte_pci_device 链入到 pci_device_list 链表中。
dpdk 内部会为每个网卡接口分配一个 rte_eth_dev 结构,在网卡 probe 流程中,pci 网卡接口的 rte_eth_dev 结构中的 pci_dev 结构被设置为扫描 pci 时创建的 rte_pci_device 结构地址。
同时每个 pci 接口的 rte_eth_dev 的 data 结构中的 numa_node 字段也用于存储接口所在的 numa_node,这个字段能够在多进程间共享且能够通过每个接口的 rte_eth_dev 直接访问到。其拷贝过程是在驱动初始化函数中调用 rte_eth_copy_pci_info 完成的。
一个示例如下:
static int
eth_i40e_dev_init(struct rte_eth_dev *dev)
{
struct rte_pci_device *pci_dev;
struct i40e_pf *pf = I40E_DEV_PRIVATE_TO_PF(dev->data->dev_private);
struct i40e_hw *hw = I40E_DEV_PRIVATE_TO_HW(dev->data->dev_private);
struct i40e_vsi *vsi;
int ret;
uint32_t len;
uint8_t aq_fail = 0;
PMD_INIT_FUNC_TRACE();
dev->dev_ops = &i40e_eth_dev_ops;
dev->rx_pkt_burst = i40e_recv_pkts;
dev->tx_pkt_burst = i40e_xmit_pkts;
.........
pci_dev = dev->pci_dev;
rte_eth_copy_pci_info(dev, pci_dev);
dpdk 内部提供的获取接口所在 numa 节点的函数代码:
int
rte_eth_dev_socket_id(uint8_t port_id)
{
if (!rte_eth_dev_is_valid_port(port_id))
return -1;
return rte_eth_devices[port_id].data->numa_node;
}
可以看到此函数将返回每个接口 rte_eth_dev 的 data 结构中的 numa_node 的值,这个值在每个接口初始化时调用驱动初始化函数从 rte_pci_device 中拷贝,缺少了这次拷贝就不能正确获取到网卡所在的 numa_node 的真实值。
2. 如何处理不同 numa 节点的大页内存?
dpdk 程序运行依赖大页内存,在多 numa 结构的设备上,大页内存存在位于不同 numa 节点的情况。尽管分配大页所在的 numa 有几种规则,dpdk 内部并没有使用到这些规则来处理大页内存归属的 numa。
dpdk 仅仅映射所有的大页,在映射的过程中通过访问 /proc/self/numa_maps 文件来确定每个映射的大页所在的 numa 节点,这意味着在 dpdk 【分配前】大页内存归属的 numa 节点就已经确定下来了,这部分工作是内核在分配大页时控制的,默认所有的大页内存在每个 numa 上均分,也可以通过写入 sys 下的相关文件来手动控制。
如果你需要控制映射的大页所在的 numa 节点,在 Local allocation 内存分配策略下,修改线程绑核就可以完成这个工作。更多的信息可以阅读内核源码树根目录下的 Documentation/vm/numa_memory_policy.txt 文件。
3. 如何获取线程所在 numa 节点?
dpdk 初始化时会扫描设备 cpu 信息,为每个核分配一个 lcore_config 结构,这个结构代表 dpdk 对一个逻辑核的抽象,同时也用于实现逻辑线程任务 pipeline 分发。
dpdk 提供 rte_socket_id 接口获取当前逻辑核所在的 numa 节点,此接口代码如下:
unsigned rte_socket_id(void)
{
return RTE_PER_LCORE(_socket_id);
}
dpdk 基于性能的考量,使用了【每线程数据】保存每个逻辑核所处的 numa 节点,dpdk 创建的 lcore 线程执行函数通过调用 eal_thread_set_affinity 来初始化 _socket_id 每线程数据。
dpdk 在初始化时通过扫描 /sys 下的文件确定当前逻辑核所在的 numa 节点,相关函数为 eal_cpu_socket_id,源码如下:
unsigned
eal_cpu_socket_id(unsigned lcore_id)
{
unsigned socket;
for (socket = 0; socket < RTE_MAX_NUMA_NODES; socket++) {
char path[PATH_MAX];
snprintf(path, sizeof(path), "%s/node%u/cpu%u", NUMA_NODE_PATH,
socket, lcore_id);
if (access(path, F_OK) == 0)
return socket;
}
return 0;
}
/sys 目录中一个示例信息如下:
[root] # ls /sys/devices/system/node/node0/cpu
cpu0/ cpu3/ cpu6/ cpu66/ cpu69/ cpu71/
cpu1/ cpu4/ cpu64/ cpu67/ cpu7/ cpulist
cpu2/ cpu5/ cpu65/ cpu68/ cpu70/ cpumap
dpdk 遍历 /sys/devices/system/node 下每个 node 的目录,cpuX 存在时表明与之对应的 lcore_id 位于当前 node。在示例信息中,0-7 与 64-71 核都位于 numa 0 上。
4. dpdk 接口相关重要数据结构分配中对 numa 的使用
4.1 rte_eth_dev_data 结构所在 numa
位于 master_lcore 所在的 numa 节点
4.2 rte_eth_dev_data 结构中的 dev_private 结构(用于驱动内部数据结构)所在 numa
优先在 master_lcore 所在 numa 节点的大页内存上分配,分配失败后从小到大遍历每个 numa 上的大页内存(跳过 master_lcore 所在 numa)上分配。
4.3 mempool 所在的 numa
由调用 rte_pktmbuf_pool_create 时传递的 socket_id 参数值决定。
4.4. rte_eth_dev_data 中的 rx queues、tx queues 指针数组所在的 numa
优先在调用 rte_eth_dev_configure 函数配置队列的线程绑定的核所在的 numa 节点上分配,分配失败则继续从小到大遍历每个 numa(跳过已经分配失败的 numa)节点来分配。
4.5 网卡 rx_queues、rx_queues 上绑定的收包描述符所在的 numa 节点
使用 rte_eth_rx_queue_setup 函数 socket_id 参数传入的 numa 节点。
4.6 网卡 tx_queues、tx_queues 上绑定的发包描述符所在的 numa 节点
使用 rte_eth_tx_queue_setup 函数 socket_id 参数传入的 numa 节点。
5. mempool 创建时对 numa 节点的使用
关键代码:
mz = rte_memzone_reserve(mz_name, mempool_size, socket_id, mz_flags);
socket_id 代表设定的 numa node,此值通过 rte_pktmbuf_pool_create 接口传入。
6. dpdk 程序队列相关的数据结构创建对 numa 的使用
下面以 ice 驱动为例,列举网卡收发包队列重要结构创建时对 numa 节点的使用。
tx_queue 与 tx desc 创建时在指定的 socket_id(表示 numa 号)上分配相关结构:
.........
/* Allocate the TX queue data structure. */
txq = rte_zmalloc_socket(NULL,
sizeof(struct ice_tx_queue),
RTE_CACHE_LINE_SIZE,
socket_id);
.........
tz = rte_eth_dma_zone_reserve(dev, "tx_ring", queue_idx,
ring_size, ICE_RING_BASE_ALIGN,
socket_id);
.........
/* Allocate software ring */
txq->sw_ring =
rte_zmalloc_socket(NULL,
sizeof(struct ice_tx_entry) * nb_desc,
RTE_CACHE_LINE_SIZE,
socket_id);
rx_queue 与 rx desc 创建时在指定的 socket_id(表示 numa 号)上分配相关结构:
/* Allocate the rx queue data structure */
rxq = rte_zmalloc_socket(NULL,
sizeof(struct ice_rx_queue),
RTE_CACHE_LINE_SIZE,
socket_id);
.........
rz = rte_eth_dma_zone_reserve(dev, "rx_ring", queue_idx,
ring_size, ICE_RING_BASE_ALIGN,
socket_id);
.........
/* Allocate the software ring. */
rxq->sw_ring = rte_zmalloc_socket(NULL,
sizeof(struct ice_rx_entry) * len,
RTE_CACHE_LINE_SIZE,
socket_id);
dpdk-19.11 中网卡重要数据结构分配所在的 numa
4.1 rte_eth_dev_data 结构所在 numa
位于 master_lcore 所在的 numa 节点。
4.2 rte_eth_dev_data 结构中的 dev_private 结构(用于驱动内部数据结构)所在 numa
使用网卡所在的 numa 节点。
4.3 mempool 所在的 numa
由调用 rte_pktmbuf_pool_create 时传递的 socket_id 参数值决定。
4.4. rte_eth_dev_data 中的 rx queues、tx queues 指针数组所在的 numa
优先在调用 rte_eth_dev_configure 函数配置队列的线程绑定的核所在的 numa 节点上分配,分配失败则继续从小到大遍历每个 numa(跳过已经分配失败的 numa)节点来分配。。
4.5 网卡 rx_queues、rx_queues 上绑定的收包描述符所在的 numa 节点
使用 rte_eth_rx_queue_setup 函数 socket_id 参数传入的 numa 节点。
4.6 网卡 tx_queues、tx_queues 上绑定的发包描述符所在的 numa 节点
使用 rte_eth_tx_queue_setup 函数 socket_id 参数传入的 numa 节点。
对收发包性能影响显著的数据结构与多 numa 架构性能调优的一条规
dpdk 收发包进程核心逻辑是调用底层驱动实现的收发包函数,访问频繁的数据结构列举如下:
- 从 mempool 中分配的 mbuf
- tx_queue、rx_queue 及网卡 rx_desc、tx_desc 结构
在多 numa 环境下,访问本地 numa 会有最高的性能,远程 numa 访问会造成性能的下降。收发包性能优化要以如下规则为基准:
网卡所在的 numa 节点、mempool 分配自的 numa 节点、网卡队列与描述符分配自的 numa 节点、收发包线程绑定的核所在的 numa 节点完全一致。