缓存和数据库,1+1如何大于2?
一、缓存的本质
缓存,简单说就是为了节约对原始资源重复获取的开销,而将结果数据副本存放起来以供获取的方式。
首先,缓存往往针对的是“资源”。我们前面已经多次提到过,当某一个操作是"幂等"的和“安全"的,那么这样的操作就可以被抽象为对"资源"的获取操作,那么它才可以考虑被缓存。有些操作不幂等、不安全,比如银行转账,改变了目标对象的状态,自然就难以被缓存。
其次,缓存数据必须是“重复"获取的。缓存能生效的本质是空间换时间。也就是说,将曾经出现过的数据以占据缓存空间的方式存放下来,在下一次的访问时直接返回,从而节约了通过原始流程访问数据的时间。有时候,某些资源的获取行为本身是幂等的和安全的,但实际应用上却不会"重复"获取,那么这样的资源是无法被设计成真正的缓存的。我们把一批数据获取中,通过缓存获得数据的次数,除以总的次数,得到的结果,叫做缓存的命中率。
再次,缓存是为了解决“开销”的问题。这个开销,可不只有时间的开销。虽然我们在很多情况下讲的开销,确实都是在时间维度上的,但它还可以是CPU、网络、I/O等一切资源。例如我们有时在Web服务中增加一层缓存,是为了避免了对原始资源获取的时候,对数据库资源调用的开销。
二、缓存应用模式
2.1 旁路缓存模式
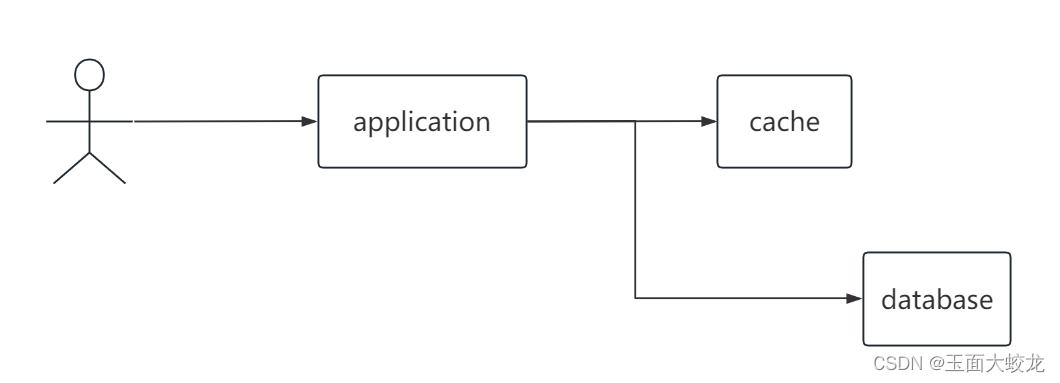
2.1.1 数据读写策略
读数据时:
- 先读缓存,若缓存有数据,直接返回
- 若缓存没有,读数据库。若数据库有,将结果写入缓存,并返回结果
- 若数据库没有,就返回没有
写数据时:
- 先写数据库
- 再令对应的缓存失效
2.1.2 操作关键
- 写数据时,必须先更新数据库,再令缓存失效
这个很容易理解,如果先令缓存失效了,而数据库还没来得及更新成功,那么假如这个时候有一个请求访问,他会直接击穿到数据库中,带着数据库的陈旧值去更新缓存,就会导致旧数据长期存在于缓存中,导致严重的数据不一致问题。
- 写数据时,更新完数据库之后,必须是让缓存失效,而不是更新缓存
为什么呢?如果此时更新的策略是更新缓存而不是令缓存失效,此时几乎同时发出的请求分别更新数据库中的值为A和B,结果是A的更新早于B,那么并不能保证这两个请求更新缓存时,顺序就是A早于B,就会导致缓存中的数据可能会长期是A值。
2.1.3 数据异常情形
读操作:
- 缓存读取异常,直接返回失败,没有数据不一致的情况
- 数据库读取异常,直接返回失败,没有数据不一致的情况
- 数据库读取成功,但是缓存写入失败,那么下一次读取同一数据的请求还会继续尝试写入,没有数据不一致的情况发生
写操作:
- 数据库写入失败,直接返回失败,没有数据不一致的情况
- 数据库写入成功,但是缓存失效的操作失败,这个问题发生了之后会非常麻烦,需要特殊处理来纠正(比如缓存数据和数据库不一致时配置告警、定期将数据库数据刷缓存)
2.2 缓存代理模式
将缓存系统作为数据库的代理,应用的请求访问只能到缓存,数据库系统对应用来说是透明的。
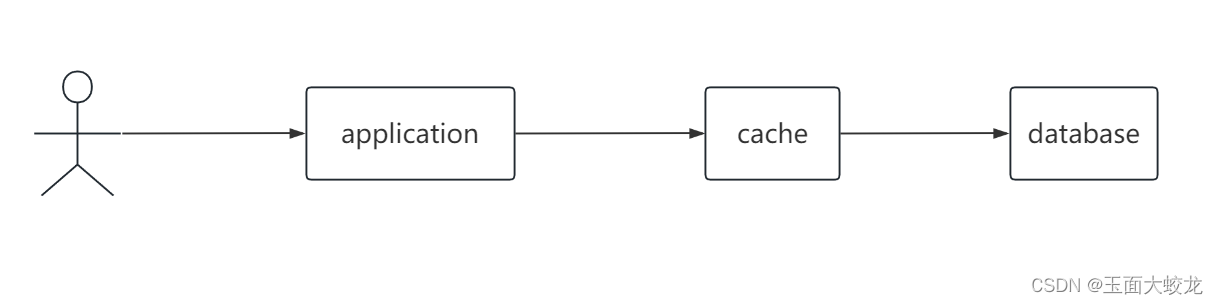
2.2.1 数据读写策略
读操作:
- 先读缓存,如果缓存中有数据,返回
- 如果缓存中没有数据,缓存查询数据库,并将结果写入自己,再返回给应用
写操作:
- 先写缓存
- 缓存再更新数据库
- 通知应用写入成功
- 这里更新数据库有两种策略
- 透写(write-through):同步更新数据库完成之后再返回成功
- 回写(write-back):更新缓存之后就直接返回成功,异步更新数据库(支持批量更新,更新效率高,速率稳定;但是存在数据丢失风险)
2.2.2 操作关键点
- 缓存系统需要自己内部保证并发场景下,缓存更新的顺序和数据库更新的顺序一致,这个可以用乐观锁来保证
2.2.3 数据异常情形
读操作:
- 同旁路缓存模式,没有数据不一致情况
写操作:
- 如果缓存更新失败,直接返回失败,没有数据不一致情况
- 如果缓存更新成功,数据库更新失败,需要回滚