# Scrapy settings for example project## For simplicity, this file contains only the most important settings by# default. All the other settings are documented here:## http://doc.scrapy.org/topics/settings.html#
SPIDER_MODULES =['example.spiders']
NEWSPIDER_MODULE ='example.spiders'# 需要改
USER_AGENT ='scrapy-redis (+https://github.com/rolando/scrapy-redis)'# 指定去重方式 给请求对象去重
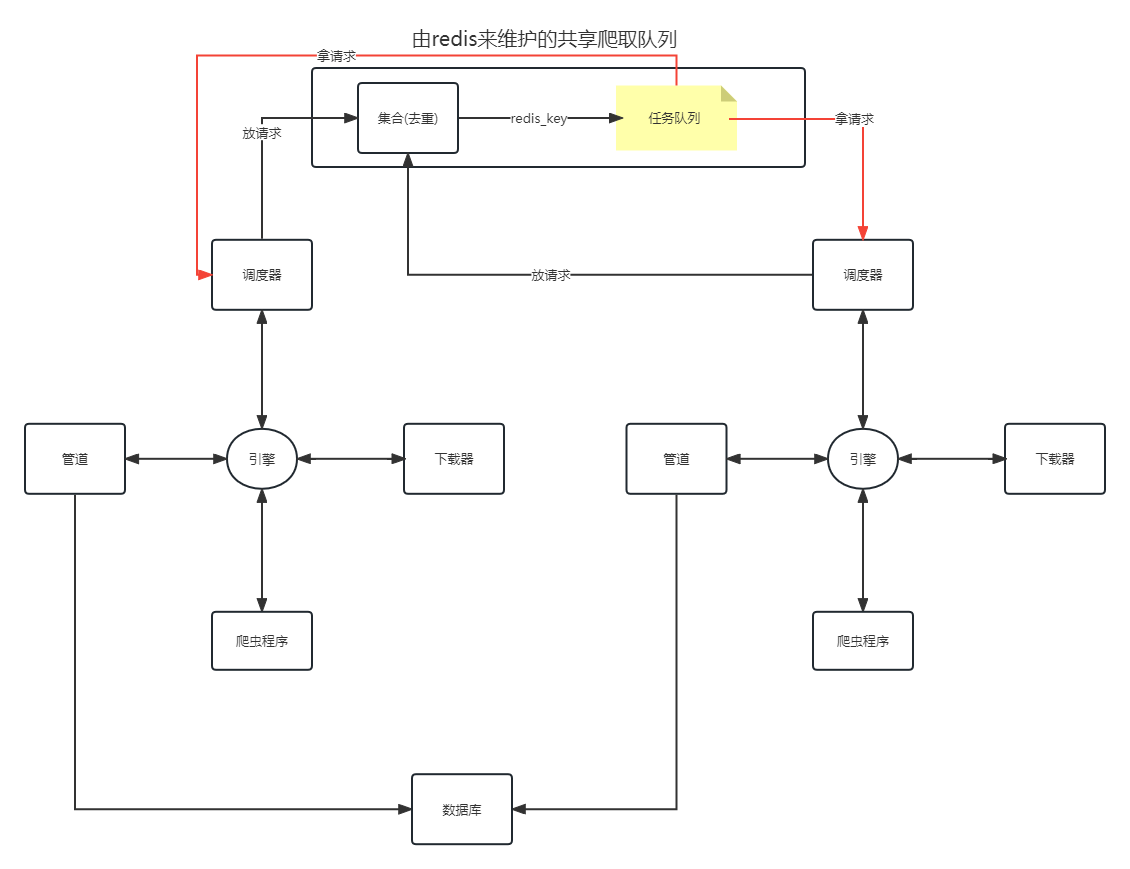
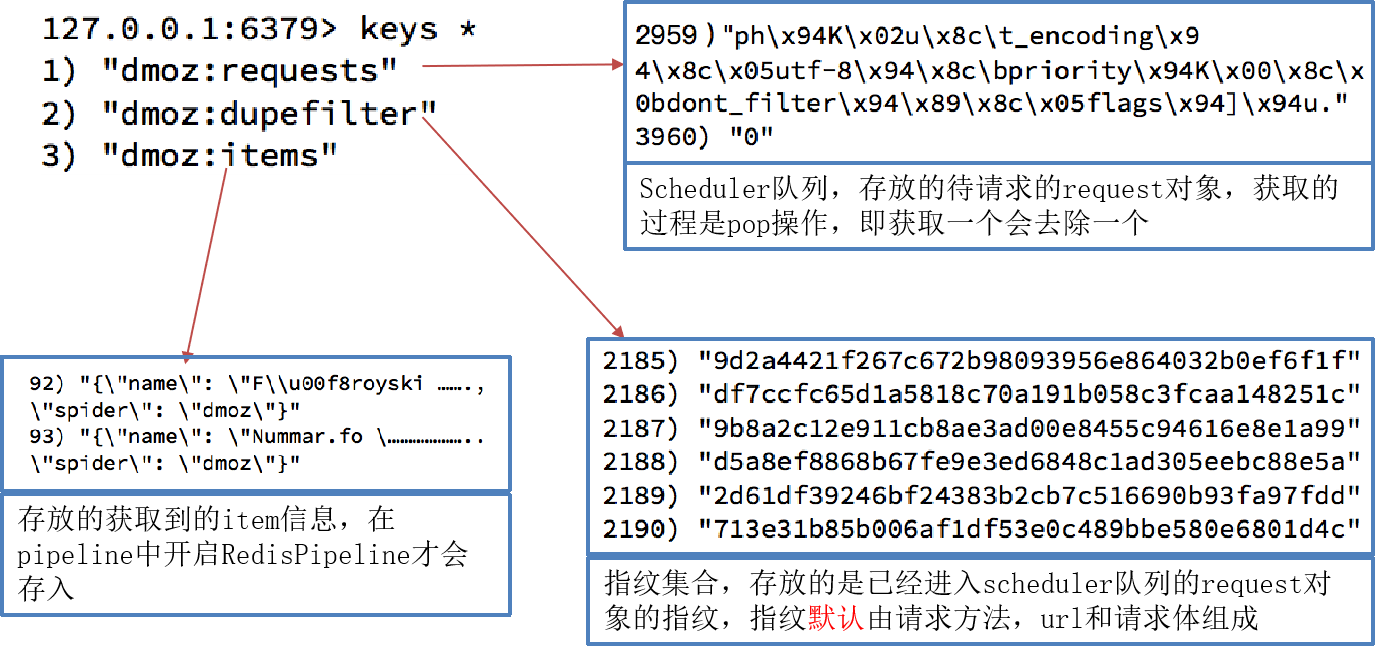
DUPEFILTER_CLASS ="scrapy_redis.dupefilter.RFPDupeFilter"# 指定那个去重方法给request对象去重# 设置调度器
SCHEDULER ="scrapy_redis.scheduler.Scheduler"# 指定Scheduler队列# 队列中的内容是否进行持久保留 True redis关闭的时候数据会保留# False 不会保留
SCHEDULER_PERSIST =True# 队列中的内容是否持久保存,为false的时候在关闭Redis的时候,清空Redis#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue"#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue"#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack"
ITEM_PIPELINES ={'example.pipelines.ExamplePipeline':300,'scrapy_redis.pipelines.RedisPipeline':400,# scrapy_redis实现的items保存到redis的pipline}
LOG_LEVEL ='DEBUG'# Introduce an artifical delay to make use of parallelism. to speed up the# crawl.
DOWNLOAD_DELAY =1