HDFS HA 模式namenode1无法启动,JournalNode报错
一、问题描述
数据突然写不进去,重启hdfs发现datasophon01节点namenode掉线
grep “ERROR” xxx.log 查看日志报错
1.1 查看datasophon01 节点namenode报错
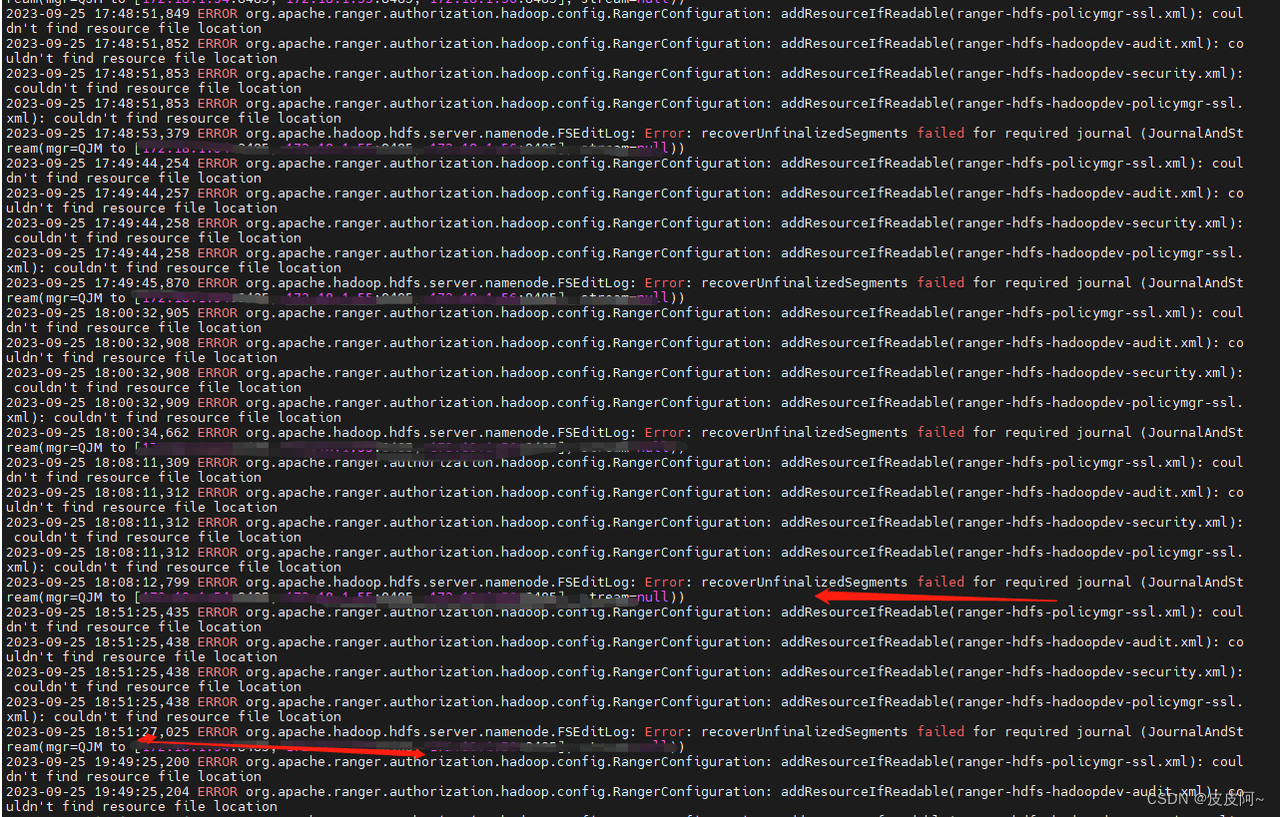
通过报错发现 JournalNode 有问题
1.2 查看 JournalNode 节点
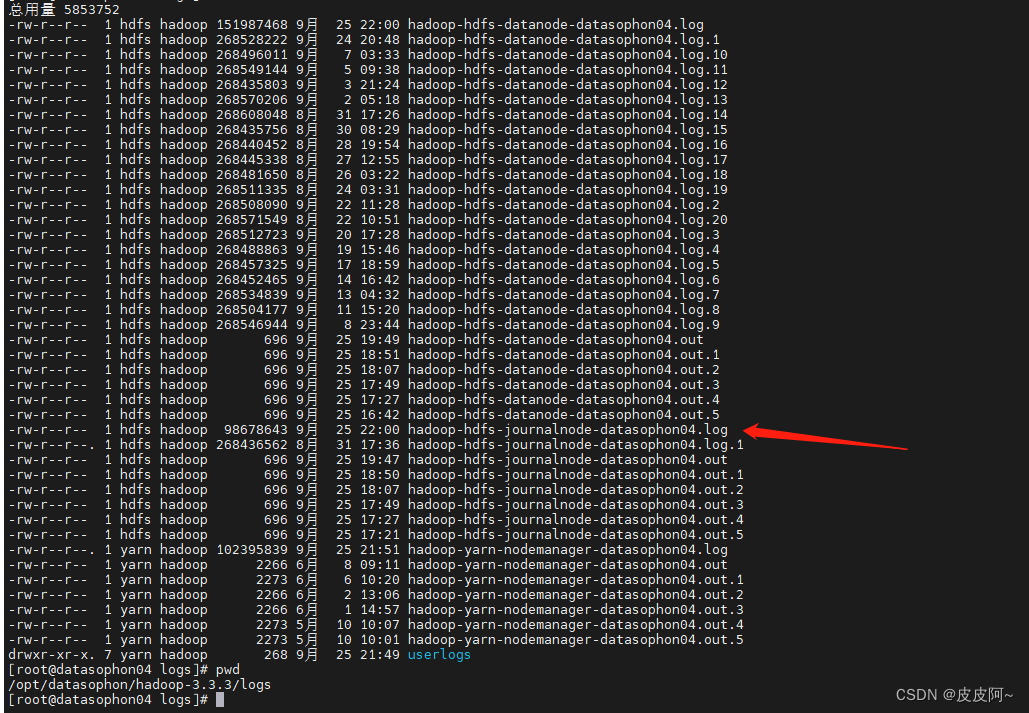
报错日志
JournalNode 原理
为了保证 Active 节点和 Standby 节点,即可以可靠的保持数据的一致性,又不会影响集群的可用性,HDFS 在 Active 节点和 Standby 节点之间引入了另外一个节点 JournalNode 节点。
JournalNode 节点作为 Active 节点和 Standby 节点的中间节点,它为两个节点解决了数据的同步的问题。首先 Active 节点会将元数据发送给 JournalNode 节点,然后 Standby 节点会从 JournalNode 节点获取需要同步的元数据。即使 Standby 节点故障了、产生问题了,在它恢复正常状态后,也可以从 JournalNode 节点中同步相应的数据。这就要求 JournalNode 节点需要有持久化的功能来保证元数据不丢。
但是,问题又来了,JournalNode 节点如果挂掉又怎么办?那么这就对 JournalNode 节点提出了新的要求,它需要保证自己的可靠性,才能保证为 Standby 节点提供数据。因此 JournalNode 节点本身也是一个多节点的集群,从而保证它自身的可靠性。而且 JournalNode 节点会在集群自动的选择一个"主"节点出来,Active 节点会和 JournalNode 的主节点通信,然后 JournalNode 集群的主节点会将数据发送给其他的节点,只要有过半的节点完成了数据的存储,JournalNode 集群的主节点,就会将成功信息返回给 Active 节点。当 JournalNode 集群的主节点挂掉,其他的 JournalNode 节点会快速选举出新的"主"节点来。
这样,通过 JournalNode 通过自身具备存储能力,和保证自身的可靠性,为 Active 节点和 Standby 节点之间的数据最终一致性提供了服务。
通过报错发现三个JournalNode 节点元数据同步不一致
二、问题解决
2.1 解决流程
1.停掉集群
2.将三台JournalNode 元数据备份
3.修改nameservice1名为nameservice1_bak
4.找到无故障JournalNode 节点 将其复制到其他节点
5.重启hdfs集群
2.2 解决
1.首先停掉集群
2.到/data/dfs/jn路径下备份元数据(注意三台JournalNode 都进行备份)
3.压缩元无故障节点元数据(因为比较大,也是保证发送过去文件不损坏)
4.修改故障节点nameservice1名为nameservice1_bak,然后解压复制的元数据压缩包

5.各个节点查看文件大小
6.重启集群
三、 重启集群后文件块损坏问题
登录hdfs集群
https://ip:9871/dfshealth.html#tab-overview
发现文件块损坏
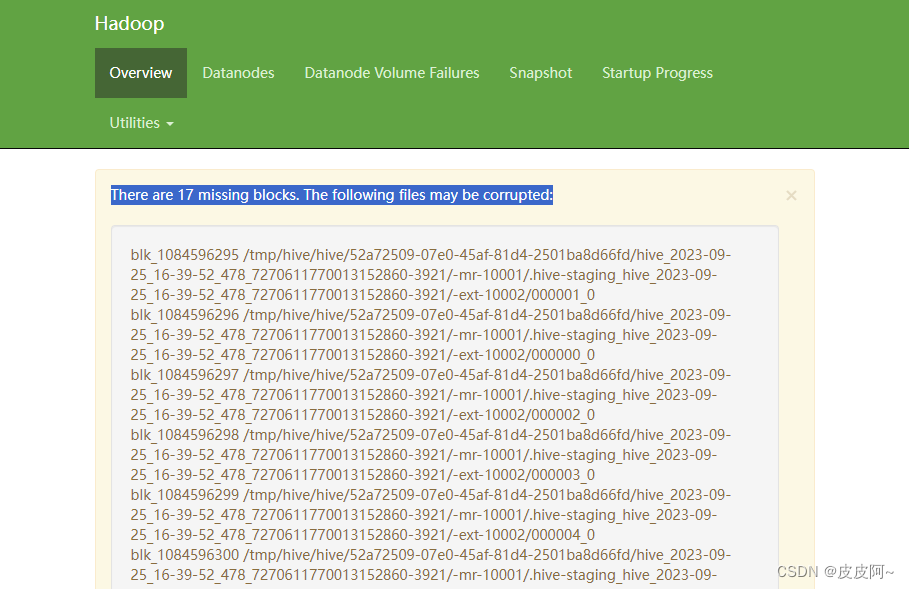
根据报错提供的,复制报错的文件块,然后进行删除
hdfs dfs -rmr /文件块路径