Flink回撤流
1.回撤流定义(RetractStream)
Flink 的回撤流是指在 Flink 的流处理算法中,撤回已经发送到下游节点的数据。这是因为在实际应用场景中,有些错误数据可能会发送到下游节点,因此需要回撤流以保证数据的准确性。
回撤流可以理解为流式场景下对数据进行更新,这里的更新数据并不是将发往下游的历史数据进行更改,要知道,已经发往下游的消息是追不回来的。更新历史数据的含义是,在得知某个Key(接在Key BY / Group By后的字段)对应数据已经存在的情况下,如果该Key对应的数据再次到来,会生成一条delete消息和一条新的insert消息发往下游。
在 Flink 中,回撤流的功能可以通过 Flink 提供的事务性 API 来实现。该 API 可以对数据流进行事务支持,以确保数据的准确性。在发生错误时,可以回撤事务中的数据,以保证数据的准确性。
总的来说,Flink 的回撤流是一个非常有用的功能,可以用于保证数据准确性和可靠性,同时也可以提高 Flink 的稳定性和可靠性。
2.回撤流示例
流场景下的一个词频统计例子
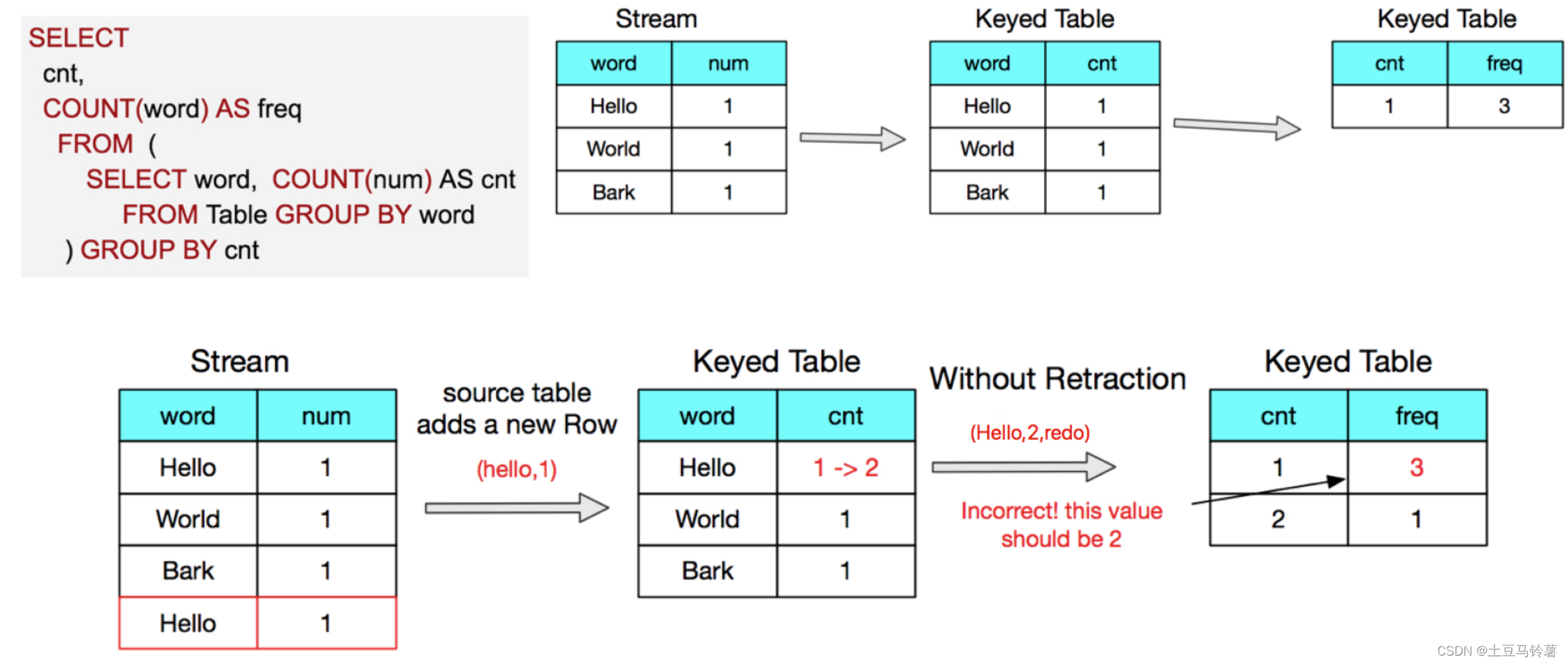
没有retract会导致最终结果不正确
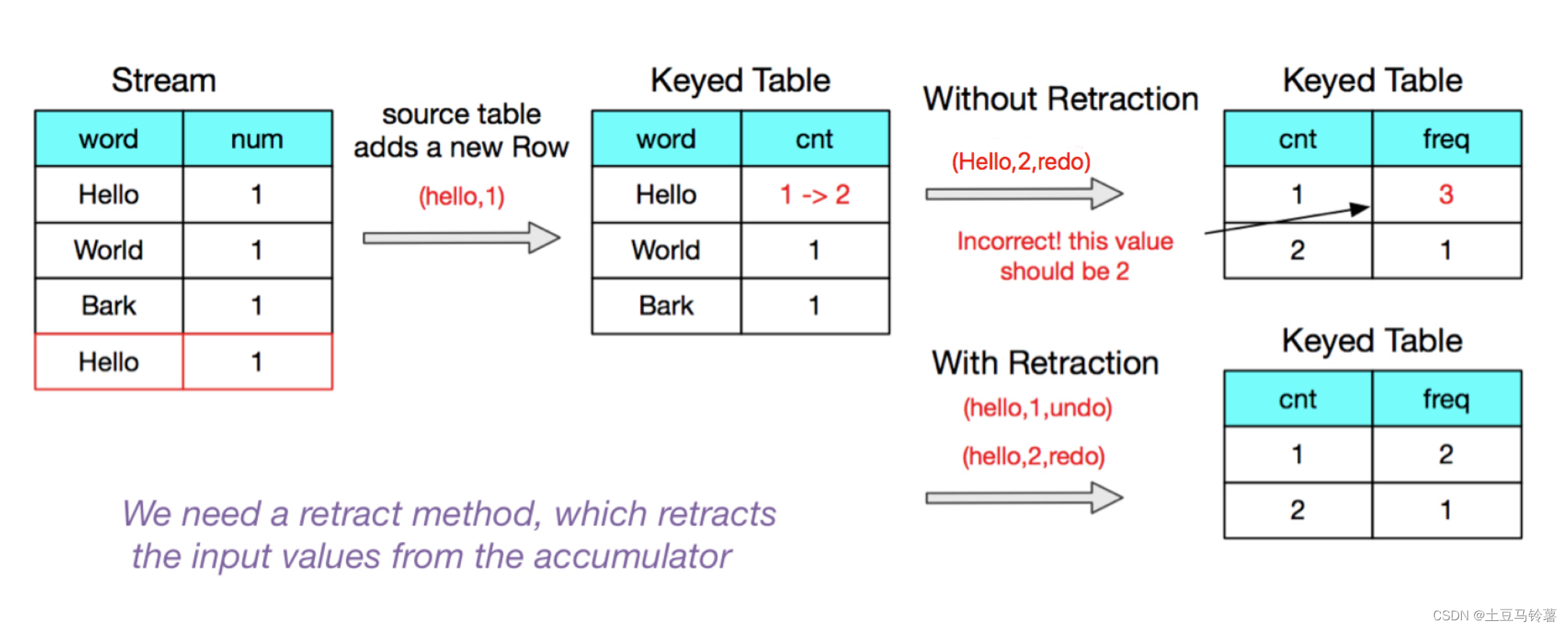
3.聚合算子回撤
聚合算子中包含两种状态,state 存储中间结果状态(如count(id)值)、cntState存储key对应的消息数量(聚合消息+1,回撤消息-1)。state用于不断更新中间聚合状态,cntState用于判断向下游发送当前新的聚合消息,还是上一次聚合消息对应的回撤消息。
4. Sink算子回撤
官方对于sink的插入模式有以下三种描述:
- Append 模式:该模式用户在定义Sink的DDL时候不定义PK,在Apache Flink内部生成的所有只有INSERT语句;
- Upsert 模式:该模式用户在定义Sink的DDL时候可以定义PK,在Apache Flink内部会根据事件打标(retract机制)生成INSERT/UPDATE和DELETE 语句,其中如果定义了PK, UPDATE语句按PK进行更新,如果没有定义PK UPDATE会按整行更新;
- Retract 模式:该模式下会产生INSERT和DELETE两种信息,Sink Connector 根据这两种信息构造对应的数据操作指令;
Sink算子是否支持回撤流,要根据sink数据源的特性而定。例如kafka sink只支持append模式,jdbc sink在Flink1.11中只支持upsert(不配置primary key会报错)。这都跟sink数据源的特性密切相关。
以Kafka Sink为例,Kafka是利用log中顺序追加消息的方式存储消息,因此只支持append模式,网上有修改kafka sink connector以支持upsert的方法:将聚合算子中的回撤消息(false)过滤掉,只留下聚合消息(true),并写入kafka,带来的现象就是一个聚合结果会多次出现在kafka中,算是一种阉割版的upsert模式。
结论:聚合算子和Sink算子关于回撤的概念相似,但原理不同且使用场景也不同,聚合算子的回撤用于聚合状态的更新,Sink算子的回撤则更多的是应用于CDC场景。
聚合算子的撤回机制,保证了FlinkSQL持续查询/增量查询的正确语义;而Sink算子的回撤机制,保证了CDC场景下的正确语义。