MARL算法系列(1):IQL【原理+代码实现】
- 原文题目:Multiagent cooperation and competition with deep reinforcement learning
- 作者:Tampuu, Ardi and Matiisen, Tambet and Kodelja, Dorian等
- 发表时间:2017年
- 主要内容:相互独立的两个DQN智能体,竞争任务下学会了相互竞争的策略,合作任务下学会了合作策略。
1 论文基本原理
1.1 Abstract
相互独立的两个DQN智能体,竞争任务下学会了相互竞争的策略,合作任务下学会了合作策略。
1.2 Introduction
第一段,简要介绍什么是强化学习。
第二段,简要介绍强化学习算法历史,重点介绍DQN。
第三段,属于relative study,介绍了博弈论领域的多智能体合作与竞争,动物群体的合作与竞争。
第三段、第四段,简要介绍如何在雅达利游戏Pong中训练两个DQN智能体,并发现不同奖励下智能体之间会学会竞争或者合作的策略。
1.3 Methods
先介绍什么是DQN。
然后介绍如何将DQN用到Multi-agent问题中,并表示最直接的方法就是,智能体把其他智能体喝环境看作整体,每个智能体之间的决策相互独立(用原文的话说就是each agent is controlled by an independent Deep Q-Network)。
介绍针对原始DQN代码的一些修改。
介绍为什么选择Pong游戏。
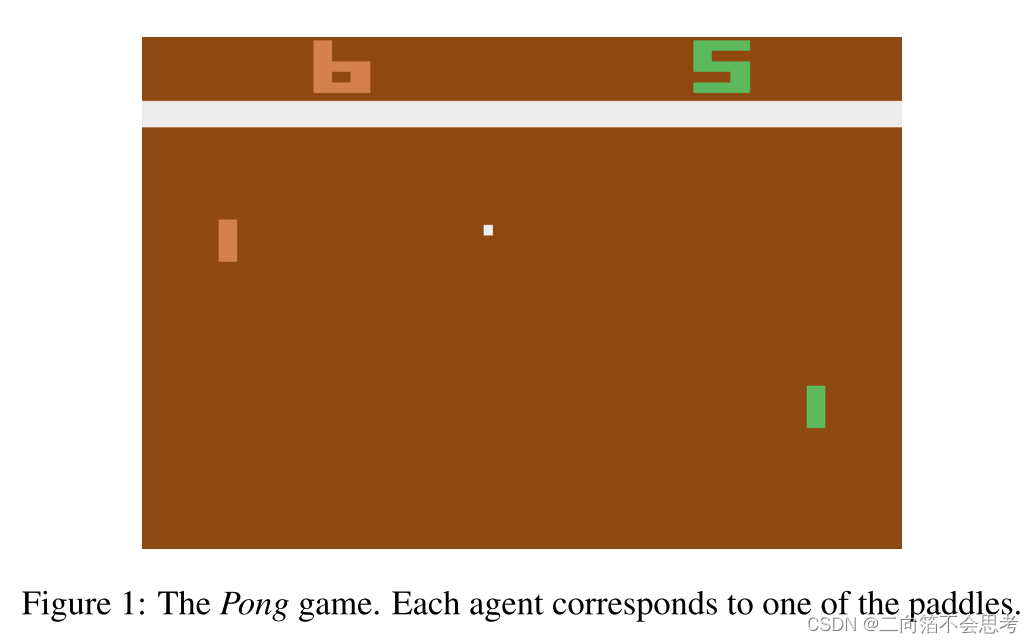
| 场景 | 奖励设置 |
|---|---|
| 完全竞争 | 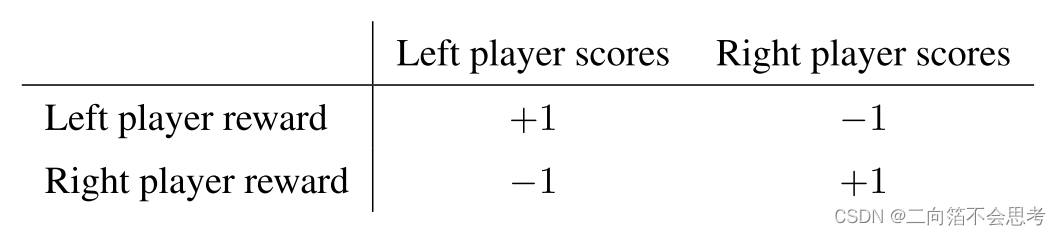 |
| 完全合作 | 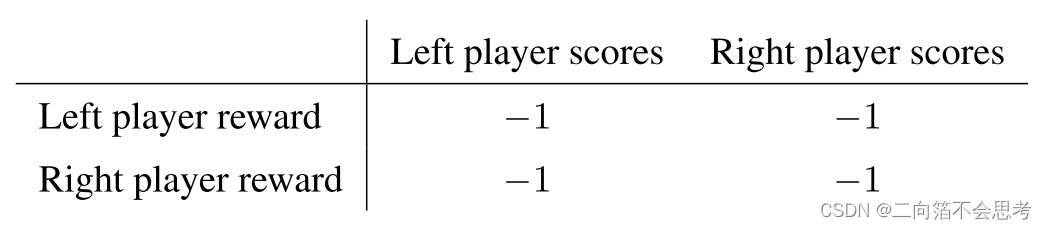 |
| 竞争+合作 | 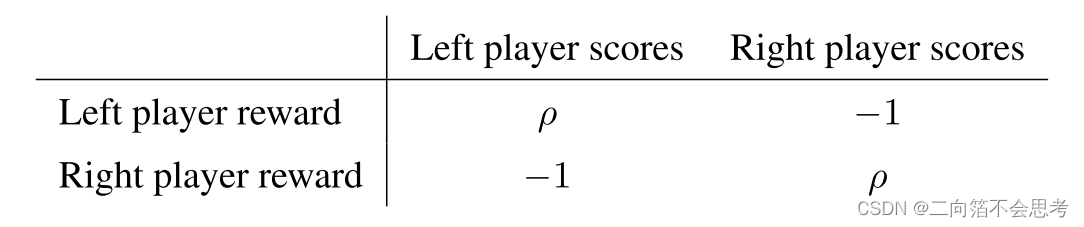 |
介绍训练过程,50个epoch,每个epoch执行250000个step。探索率在一百万步内从1降到0.05然后不变。
介绍游戏的一些统计指标:平均拍数,平均撞到墙壁的次数,待机时间。
1.4 实验结果
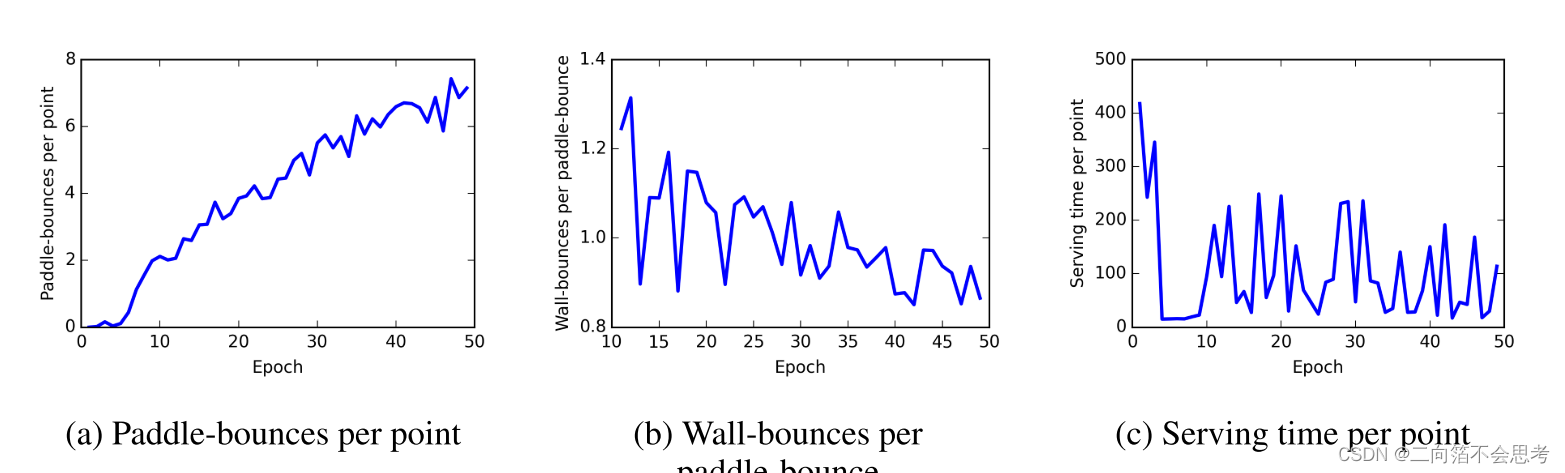

这种直观的解释还是很有说服力的。
实验与代码分析
代码,这是参考这个实现:https://github.com/starry-sky6688/MARL-Algorithms。
import torch
import os
from network.base_net import RNN
class IQL:
def __init__(self, args):
self.n_actions = args.n_actions
self.n_agents = args.n_agents
self.state_shape = args.state_shape
self.obs_shape = args.obs_shape
input_shape = self.obs_shape
# 根据参数决定RNN的输入维度
if args.last_action:
input_shape += self.n_actions
if args.reuse_network:
input_shape += self.n_agents
# 神经网络
self.eval_rnn = RNN(input_shape, args)
self.target_rnn = RNN(input_shape, args)
self.args = args
if self.args.cuda:
self.eval_rnn.cuda()
self.target_rnn.cuda()
self.model_dir = args.model_dir + '/' + args.alg + '/' + args.map
# 如果存在模型则加载模型
if self.args.load_model:
if os.path.exists(self.model_dir + '/rnn_net_params.pkl'):
path_rnn = self.model_dir + '/rnn_net_params.pkl'
map_location = 'cuda:0' if self.args.cuda else 'cpu'
self.eval_rnn.load_state_dict(torch.load(path_rnn, map_location=map_location))
print('Successfully load the model: {}'.format(path_rnn))
else:
raise Exception("No model!")
# 让target_net和eval_net的网络参数相同
self.target_rnn.load_state_dict(self.eval_rnn.state_dict())
self.eval_parameters = list(self.eval_rnn.parameters())
if args.optimizer == "RMS":
self.optimizer = torch.optim.RMSprop(self.eval_parameters, lr=args.lr)
# 执行过程中,要为每个agent都维护一个eval_hidden
# 学习过程中,要为每个episode的每个agent都维护一个eval_hidden、target_hidden
self.eval_hidden = None
self.target_hidden = None
print('Init alg IQL')
def learn(self, batch, max_episode_len, train_step, epsilon=None): # train_step表示是第几次学习,用来控制更新target_net网络的参数
'''
在learn的时候,抽取到的数据是四维的,四个维度分别为 1——第几个episode 2——episode中第几个transition
3——第几个agent的数据 4——具体obs维度。因为在选动作时不仅需要输入当前的inputs,还要给神经网络输入hidden_state,
hidden_state和之前的经验相关,因此就不能随机抽取经验进行学习。所以这里一次抽取多个episode,然后一次给神经网络
传入每个episode的同一个位置的transition
'''
episode_num = batch['o'].shape[0]
self.init_hidden(episode_num)
for key in batch.keys(): # 把batch里的数据转化成tensor
if key == 'u':
batch[key] = torch.tensor(batch[key], dtype=torch.long)
else:
batch[key] = torch.tensor(batch[key], dtype=torch.float32)
u, r, avail_u, avail_u_next, terminated = batch['u'], batch['r'].repeat(1, 1, self.n_agents), batch['avail_u'], \
batch['avail_u_next'], batch['terminated'].repeat(1, 1, self.n_agents)
mask = (1 - batch["padded"].float()).repeat(1, 1, self.n_agents) # 用来把那些填充的经验的TD-error置0,从而不让它们影响到学习
# 得到每个agent对应的Q值,维度为(episode个数, max_episode_len, n_agents, n_actions)
q_evals, q_targets = self.get_q_values(batch, max_episode_len)
if self.args.cuda:
u = u.cuda()
r = r.cuda()
terminated = terminated.cuda()
mask = mask.cuda()
# 取每个agent动作对应的Q值,并且把最后不需要的一维去掉,因为最后一维只有一个值了
q_evals = torch.gather(q_evals, dim=3, index=u).squeeze(3)
# 得到target_q
q_targets[avail_u_next == 0.0] = - 9999999
q_targets = q_targets.max(dim=3)[0]
targets = r + self.args.gamma * q_targets * (1 - terminated)
td_error = (q_evals - targets.detach())
masked_td_error = mask * td_error # 抹掉填充的经验的td_error
# 不能直接用mean,因为还有许多经验是没用的,所以要求和再比真实的经验数,才是真正的均值
loss = (masked_td_error ** 2).sum() / mask.sum()
# print('loss is ', loss)
self.optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(self.eval_parameters, self.args.grad_norm_clip)
self.optimizer.step()
if train_step > 0 and train_step % self.args.target_update_cycle == 0:
self.target_rnn.load_state_dict(self.eval_rnn.state_dict())
return loss
def _get_inputs(self, batch, transition_idx):
# 取出所有episode上该transition_idx的经验,u_onehot要取出所有,因为要用到上一条
obs, obs_next, u_onehot = batch['o'][:, transition_idx], \
batch['o_next'][:, transition_idx], batch['u_onehot'][:]
episode_num = obs.shape[0]
inputs, inputs_next = [], []
inputs.append(obs)
inputs_next.append(obs_next)
# 给obs添加上一个动作、agent编号
if self.args.last_action:
if transition_idx == 0: # 如果是第一条经验,就让前一个动作为0向量
inputs.append(torch.zeros_like(u_onehot[:, transition_idx]))
else:
inputs.append(u_onehot[:, transition_idx - 1])
inputs_next.append(u_onehot[:, transition_idx])
if self.args.reuse_network:
# 因为当前的obs三维的数据,每一维分别代表(episode编号,agent编号,obs维度),直接在dim_1上添加对应的向量
# 即可,比如给agent_0后面加(1, 0, 0, 0, 0),表示5个agent中的0号。而agent_0的数据正好在第0行,那么需要加的
# agent编号恰好就是一个单位矩阵,即对角线为1,其余为0
inputs.append(torch.eye(self.args.n_agents).unsqueeze(0).expand(episode_num, -1, -1))
inputs_next.append(torch.eye(self.args.n_agents).unsqueeze(0).expand(episode_num, -1, -1))
# 要把obs中的三个拼起来,并且要把episode_num个episode、self.args.n_agents个agent的数据拼成40条(40,96)的数据,
# 因为这里所有agent共享一个神经网络,每条数据中带上了自己的编号,所以还是自己的数据
inputs = torch.cat([x.reshape(episode_num * self.args.n_agents, -1) for x in inputs], dim=1)
inputs_next = torch.cat([x.reshape(episode_num * self.args.n_agents, -1) for x in inputs_next], dim=1)
return inputs, inputs_next
def get_q_values(self, batch, max_episode_len):
episode_num = batch['o'].shape[0]
q_evals, q_targets = [], []
for transition_idx in range(max_episode_len):
inputs, inputs_next = self._get_inputs(batch, transition_idx) # 给obs加last_action、agent_id
if self.args.cuda:
inputs = inputs.cuda()
inputs_next = inputs_next.cuda()
self.eval_hidden = self.eval_hidden.cuda()
self.target_hidden = self.target_hidden.cuda()
q_eval, self.eval_hidden = self.eval_rnn(inputs, self.eval_hidden) # inputs维度为(40,96),得到的q_eval维度为(40,n_actions)
q_target, self.target_hidden = self.target_rnn(inputs_next, self.target_hidden)
# 把q_eval维度重新变回(8, 5,n_actions)
q_eval = q_eval.view(episode_num, self.n_agents, -1)
q_target = q_target.view(episode_num, self.n_agents, -1)
q_evals.append(q_eval)
q_targets.append(q_target)
# 得的q_eval和q_target是一个列表,列表里装着max_episode_len个数组,数组的的维度是(episode个数, n_agents,n_actions)
# 把该列表转化成(episode个数, max_episode_len, n_agents,n_actions)的数组
q_evals = torch.stack(q_evals, dim=1)
q_targets = torch.stack(q_targets, dim=1)
return q_evals, q_targets
def init_hidden(self, episode_num):
# 为每个episode中的每个agent都初始化一个eval_hidden、target_hidden
self.eval_hidden = torch.zeros((episode_num, self.n_agents, self.args.rnn_hidden_dim))
self.target_hidden = torch.zeros((episode_num, self.n_agents, self.args.rnn_hidden_dim))
def save_model(self, train_step):
num = str(train_step // self.args.save_cycle)
if not os.path.exists(self.model_dir):
os.makedirs(self.model_dir)
torch.save(self.eval_rnn.state_dict(), self.model_dir + '/' + num + '_rnn_net_params.pkl')