Elasticsearch:生成 AI 中的微调与 RAG
在自然语言处理 (NLP) 领域,出现了两种卓越的技术,每种技术都有其独特的功能:微调大型语言模型 (LLM) 和 RAG(检索增强生成)。 这些方法极大地影响了我们利用语言模型的方式,使它们更加通用和有效。 在本文中,我们将详细介绍微调和 RAG 的含义,并强调它们之间的主要区别。
深入研究微调 LLM:为特定任务定制语言模型
微调是生成人工智能中的一个关键过程,其中预训练的语言模型是针对特定任务或领域/任务定制的。 它涉及完善模型执行专门任务的能力。 (例如,领域:财务,任务:总结)
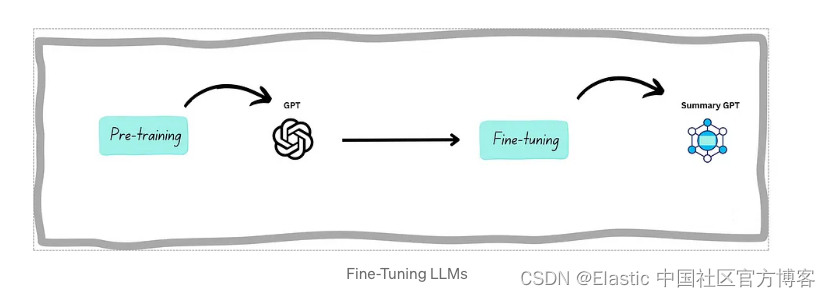
理解 RAG:使 AI 生成的文本更加上下文相关、事实准确
RAG 代表 “检索增强生成”。 简单来说,RAG是人工智能中一种将信息检索与文本生成相结合的技术。 它可以帮助人工智能模型提供更准确且与上下文相关的响应。
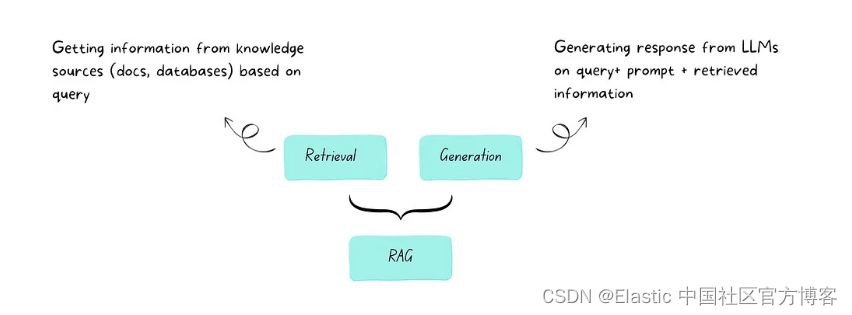
区别:微调与 RAG
微调大语言模型 (LLM) 和 RAG(检索增强生成)是构建和使用自然语言处理模型的两种不同方法。 以下是两者之间主要区别的细分:
目的:
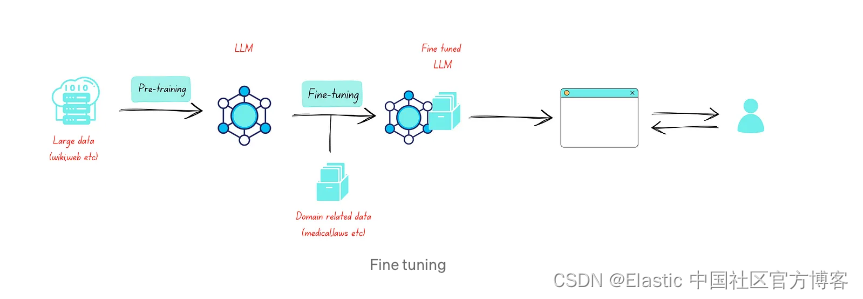
- 微调 LLM:微调涉及采用预先训练的 LLM(例如 GPT-3 或 BERT)并使其适应特定任务。 它是一种用于各种 NLP 任务的通用方法,包括文本分类、语言翻译、情感分析等。 当仅使用模型本身即可完成任务并且不需要外部信息检索时,通常会使用微调的 LLM。
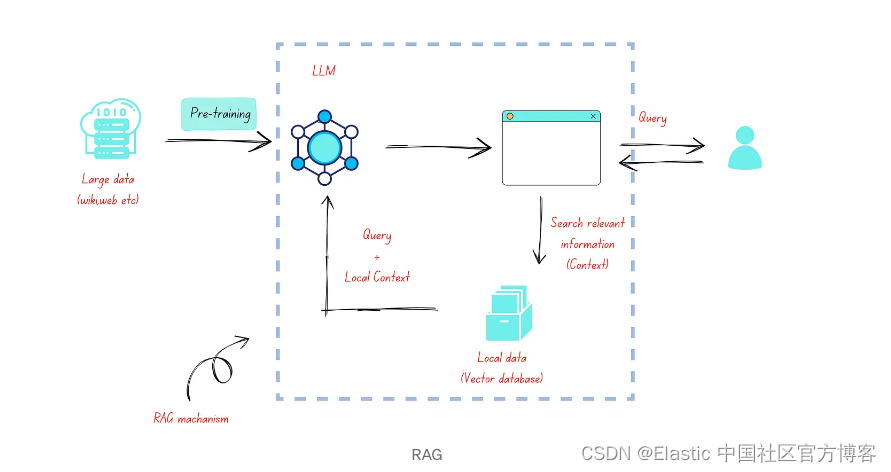
- RAG:RAG 模型专为涉及文本检索和生成的任务而设计。 它们结合了检索机制(从大型数据库中获取相关信息)和生成机制(根据检索到的信息生成类似人类的文本)。 RAG 模型通常用于问答、文档摘要以及其他访问本地信息至关重要的任务。
架构:
- 微调 LLM:微调 LLM 通常从预先训练的模型(如 GPT-3)开始,并通过针对特定任务的数据进行训练来对其进行微调。 该架构基本保持不变,只是对模型参数进行了调整,以优化特定任务的性能。
- RAG:RAG 模型具有混合架构,将基于转换器的 LLM(如 GPT)与外部内存模块相结合,允许从知识源(例如数据库或一组文档)进行高效检索。
训练数据:
- 微调 LLM:微调 LLM 依赖于特定于任务的训练数据,通常由与目标任务匹配的标记示例组成,但它们没有明确涉及检索机制。
- RAG:RAG 模型经过训练可以处理检索和生成,这通常涉及监督数据(用于生成)和演示如何有效检索和使用外部信息的数据的组合。
用例:
- 微调 LLM:微调 LLM 适用于各种 NLP 任务,包括文本分类、情感分析、文本生成等,其中任务主要涉及根据输入理解和生成文本。
- RAG:RAG 模型在任务需要访问外部知识的场景中表现出色,例如开放域问答、文档摘要或可以从知识库提供信息的聊天机器人。
使用 Elasticsearch 拥抱 RAG
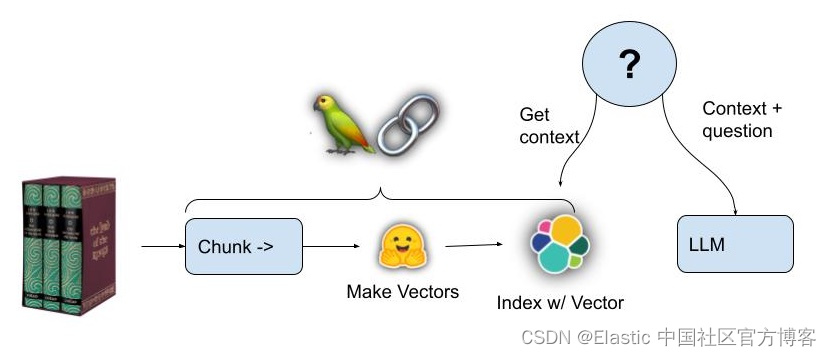
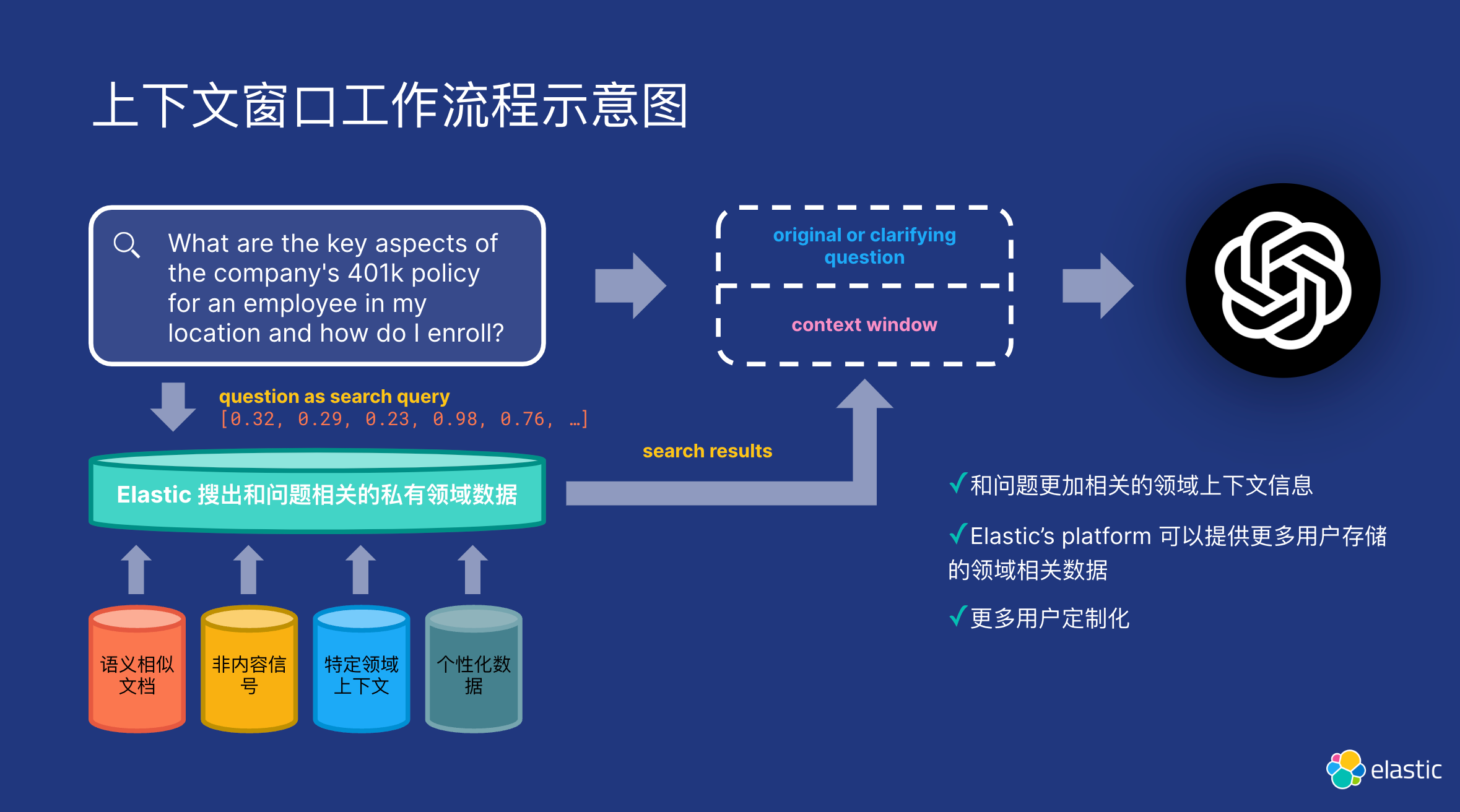
RAG 是 NLP 领域的一项关键创新,它集成了检索模型和生成模型的功能,以生成连贯、上下文丰富的文本。
RAG 将检索模型(如我们上面所描述的)与生成模型相结合,检索模型充当 “图书馆员”,扫描大型数据库以获取相关信息,生成模型充当 “作家”,将这些信息合成为与任务更相关的文本。 它用途广泛,适用于实时新闻摘要、自动化客户服务和复杂研究任务等多种领域。
RAG 需要检索模型,例如跨嵌入的向量搜索,与通常基于 LLMs 构建的生成模型相结合,该模型能够将检索到的信息合成为有用的响应。
总结
总之,RAG 和微调 LLM 之间的主要区别在于它们的架构设计和目的。 RAG 模型专门用于需要信息检索和文本生成相结合的任务,而微调 LLM 则适用于特定的 NLP 任务,而不需要外部知识检索。 这些方法之间的选择取决于任务的性质以及是否涉及与外部信息源交互。