sheng的学习笔记-IO多路复用,NIO,BIO,AIO
基础概念
IO分为几种:同步阻塞的BIO,同步非阻塞的NIO,异步非阻塞AIO,IO多路复用,信号驱动IO(不常用)
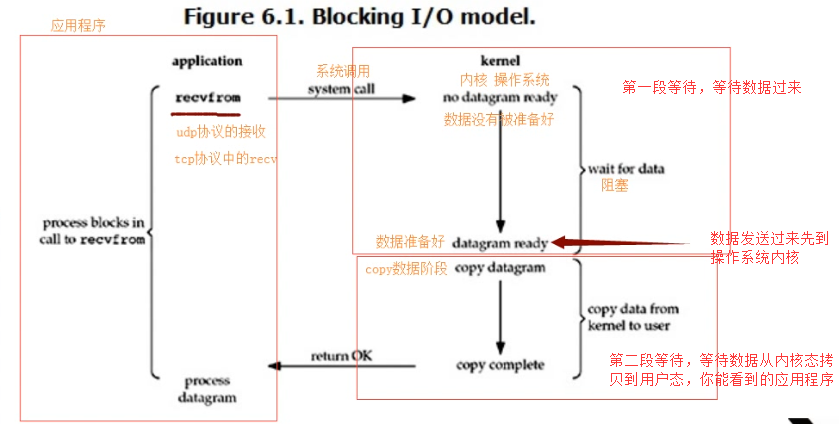
对于一个network IO,它会涉及到两个系统对象,一个是调用这个IO的process(Thread),另一个是系统内核。当一个read/recv读数据的操作发生时,该操作会经历两个阶段:
(1)等待数据准备
(2)将数据从内核拷贝到进程中
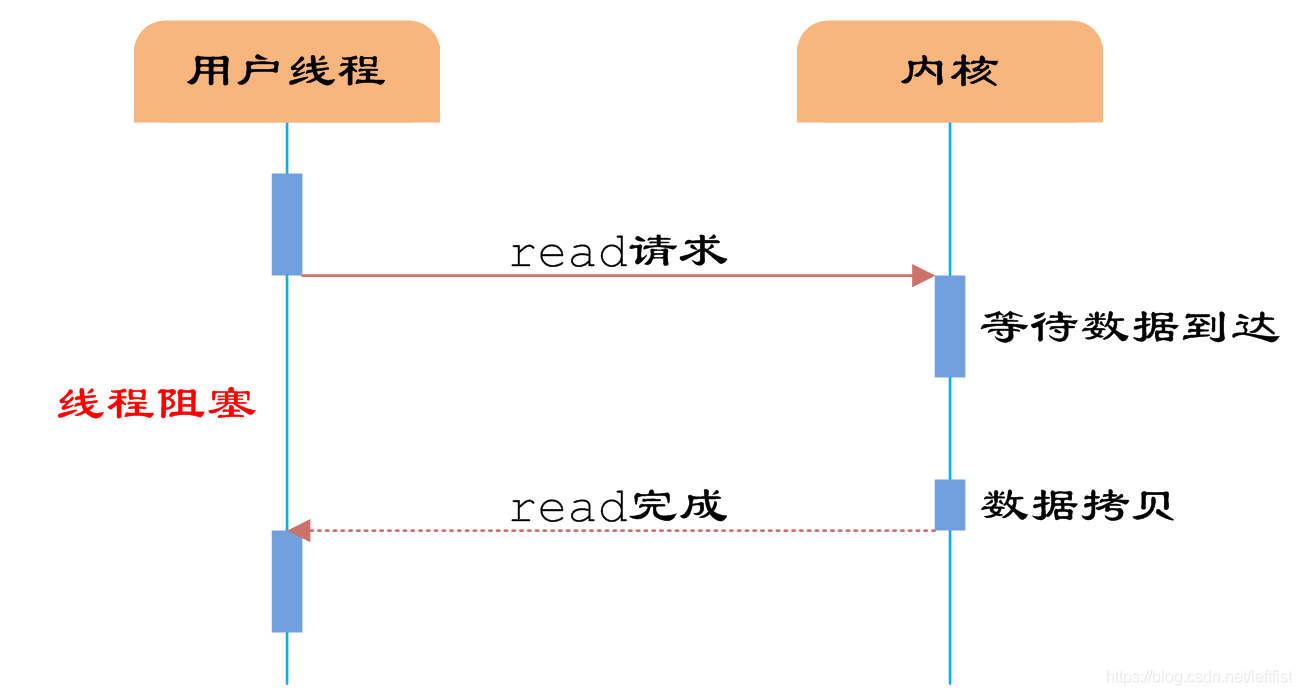
BIO:同步并阻塞
服务端处理请求是串联的。也就是说如果这个请求被阻塞了,那么剩下的请求都要被阻塞``等待``上一个请求处理完成才行。所以,我们上面说,在 服务器读数据的时候,数据还没到(数据还没读到用户态),那么服务器被阻塞,然后其他客户端的请求也不能被处理。
比如:
小明和小红两个人访问同一个服务,然后小明先点,但是数据没被处理完成,然后小红在进行发送请求,此时服务器就将小红的请求挂起,等待小明的处理完成在进行处理。
而且小明发了申请,服务器没有返回响应之前,小明也不能动,阻塞在那里等待到应答,才能继续做别的事情
.
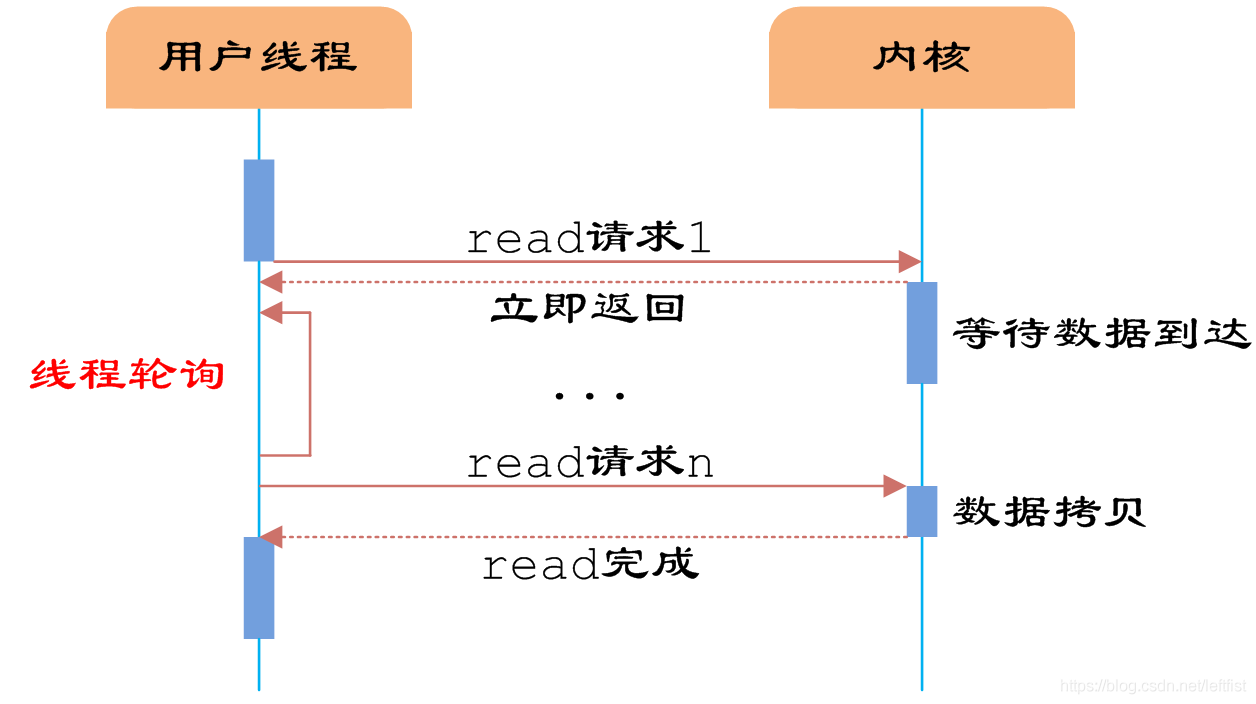
NIO:同步非阻塞
用户线程发起IO请求后,立即返回;这时候可以干点别的,过一会再查,但需要不断地调用read,尝试读取socket中的数据,直到读取成功后,才继续处理接收的数据。
虽然用户线程每次发起IO请求后可以立即返回,但是为了等到数据,仍需要不断地轮询、重复请求,消耗了大量的CPU的资源。一般很少直接使用这种模型,而是在其他IO模型中使用非阻塞IO这一特性。
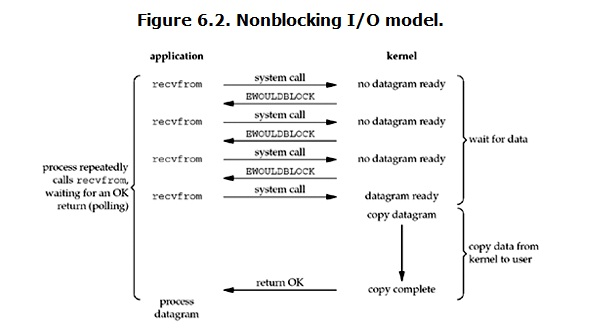
当用户进程发出read操作时,如果kernel中的数据还没准备好,那么它并不会block用户进程,而是立刻返回一个error。当用户进程接收到一个error,就会知道数据还没准备,于是用户就可以做点其他的,过一段时间,再次发送read操作,一旦kernel的数据准备好了,他就会立马把数据拷贝到了用户内存,然后返回。
在这种非阻塞IO模式下,用户进程就不断的询问kernel的数据准备好了没,若没有,返回给 用户一个error,在两次询问期间,用户进程可以干点其他的,若数据准备好了,就直接拷贝,这个询问过程叫轮询。在拷贝数据整个过程,进程任仍然处于阻塞状态
IO多路复用
一个线程内同时处理多个IO请求,这就是IO多路复用
相当于select\epoll,这种IO方式也称为事件驱动IO,select\epoll的好处在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select\epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据响应了,就通知用户进程。
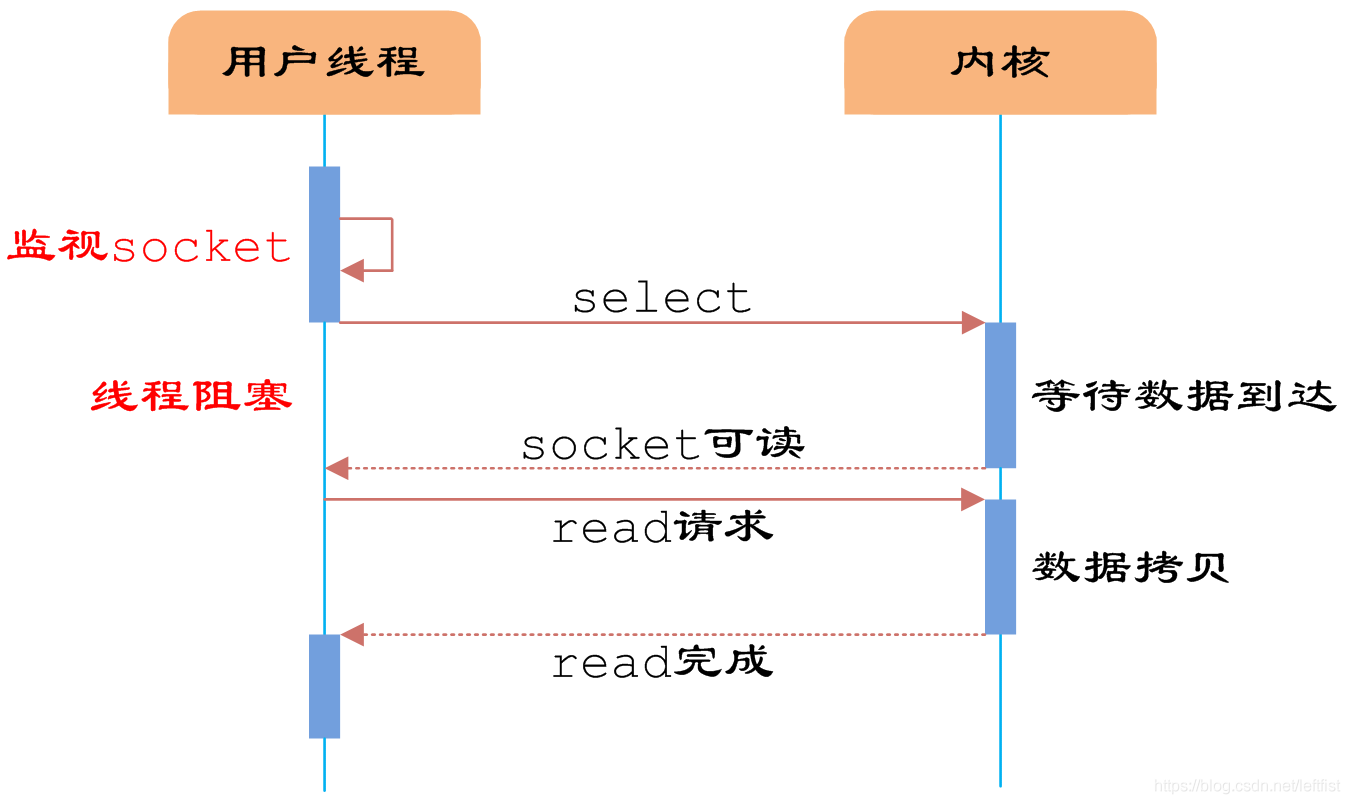
当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
这个图和blocking IO的图其实并没有太大的不同,事实上还更差一些。因为它不仅阻塞了还多需要使用两个系统调用(select和recvfrom),而blocking IO只调用了一个系统调用(recvfrom),当只有一个连接请求的时候,这个模型还不如阻塞IO效率高。但是,用select的优势在于它可以同时处理多个connection,而阻塞IO那里不能,我不管阻塞不阻塞,你所有的连接包括recv等操作,我都帮你监听着(以什么形式监听的呢?先不要考虑,下面会讲的~~),其中任何一个有变动(有链接,有数据),我就告诉你用户,那么你就可以去调用这个数据了,这就是他的NB之处。
select模块及使用方法:select的优势在于处理多个连接,不适用于单个连接
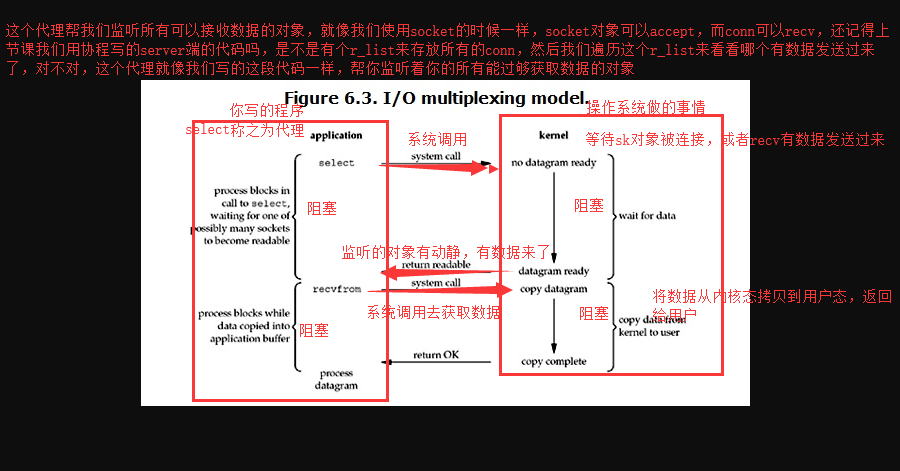
虽然上述方式允许单线程内处理多个IO请求,但是每个IO请求的过程还是阻塞的(在select函数上阻塞),平均时间甚至比同步阻塞IO模型还要长。如果用户线程只注册自己感兴趣的socket或者IO请求,然后去做自己的事情,等到数据到来时再进行处理,则可以提高CPU的利用率。以下是改良版:
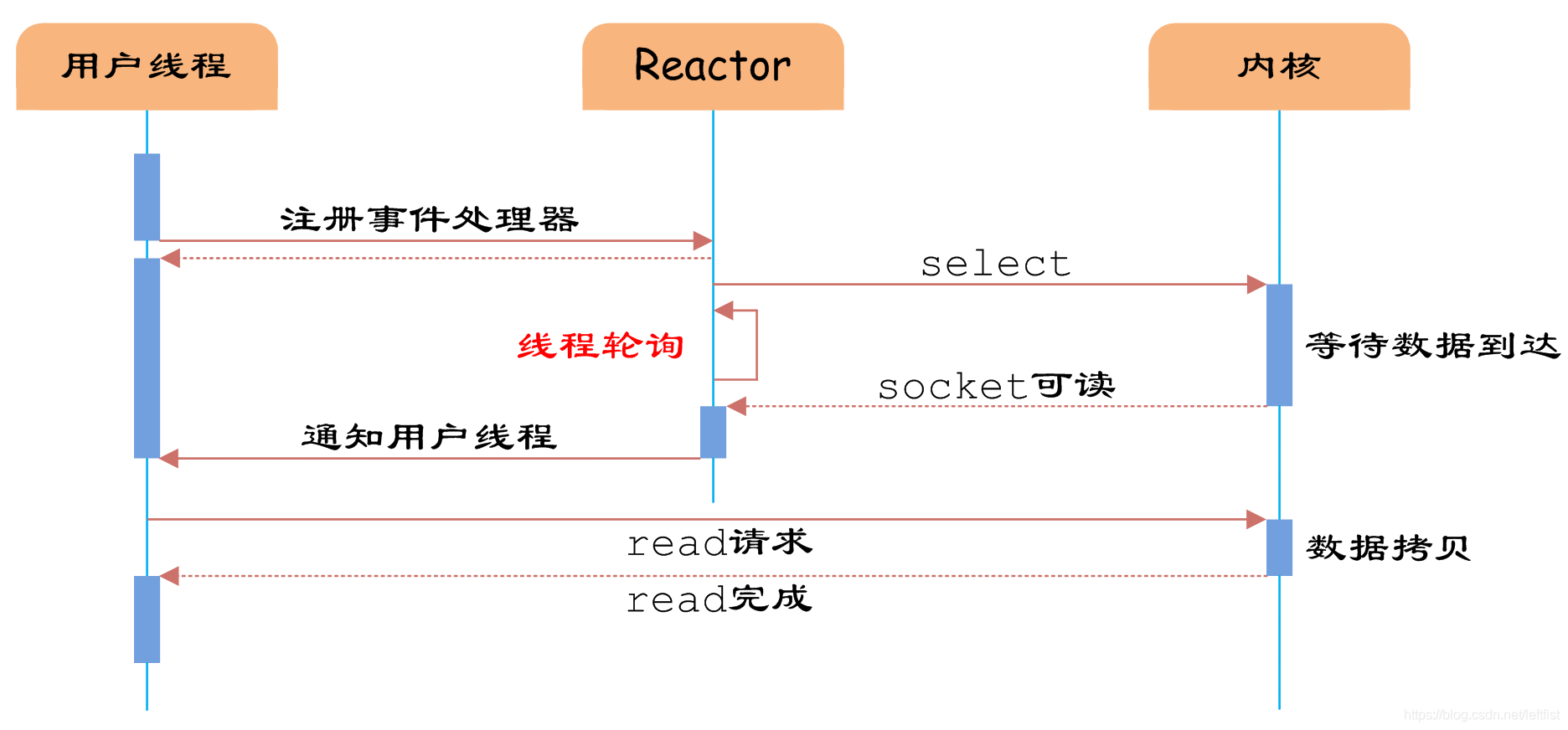
reactor设计模式,就是基于IO多路复用,可以参考
https://blog.csdn.net/coldstarry/article/details/129433822
AIO:异步IO
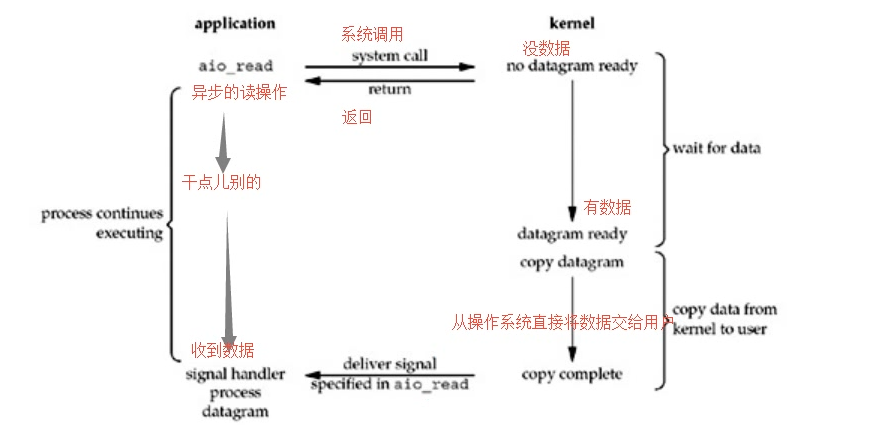
用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel操作系统会等待数据(阻塞)准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
貌似异步IO这个模型很牛~~但是你发现没有,这不是我们自己代码控制的,都是操作系统完成的,而python在copy数据这个阶段没有提供操纵操作系统的接口,所以用python没法实现这套异步IO机制,其他几个IO模型都没有解决第二阶段的阻塞(用户态和内核态之间copy数据),但是C语言是可以实现的,因为大家都知道C语言是最接近底层的,虽然我们用python实现不了,但是python仍然有异步的模块和框架(tornado、twstied,高并发需求的时候用),这些模块和框架很多都是用底层的C语言实现的,它帮我们实现了异步,你只要使用就可以了,但是你要知道这个异步是不是很好呀,不需要你自己等待了,操作系统帮你做了所有的事情,你就直接收数据就行了,就像你有一张银行卡,银行定期给你打钱一样。
信号驱动IO
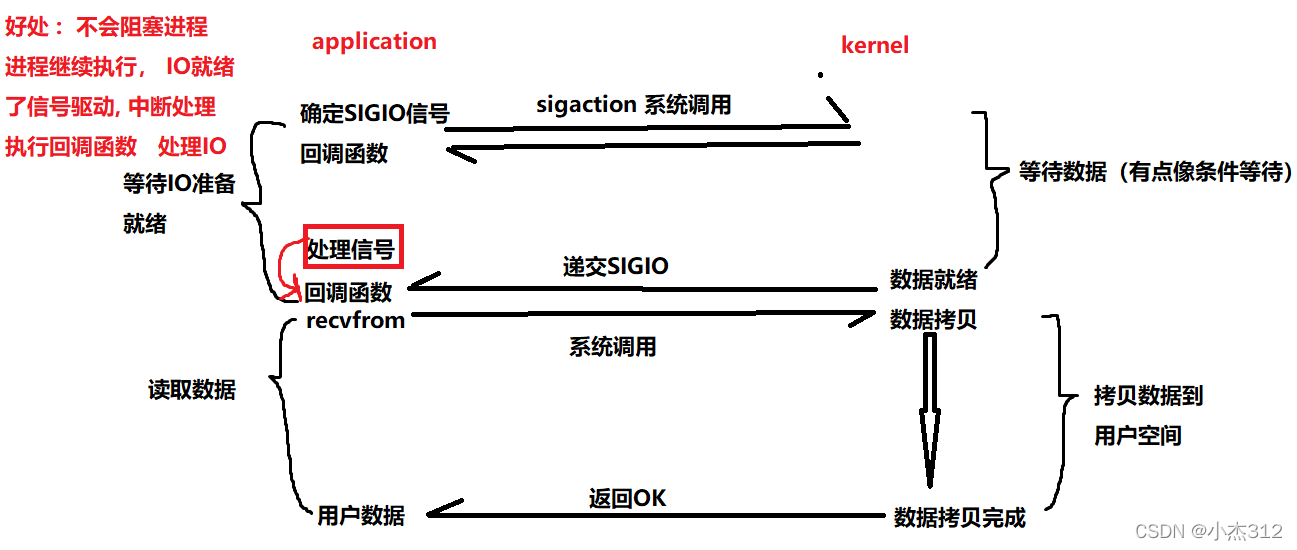
信号驱动IO: 内核将数据准备好的时候, 使用SIGIO信号通知应用程序进行IO操作
通知应用程序处理IO, 是开始处理IO, 这个时候还是存在阻塞的,将数据从内核态拷贝进入到用户态的过程至少是阻塞住的 (应用程序将数据从内核态拷贝到用户态的过程是阻塞等待的, 和异步IO的区别) (此处是区分信号驱动IO和异步IO的关键所在)
信号驱动IO, 我们提前在信号集合中设置好IO信号等待, 注册好对应的IO处理函数 handler,IO数据准备就绪后,会递交SIGIO信号,通知应用程序中断然后开始进行对应的IO处理逻辑. 但是通知处理IO的时候存在将数据从 内核空间拷贝到用户空间的过程,(而异步IO是数据拷贝完成之后内核再通知应用程序直接开始处理, 应用程序直接处理,不需要拷贝数据阻塞等待)
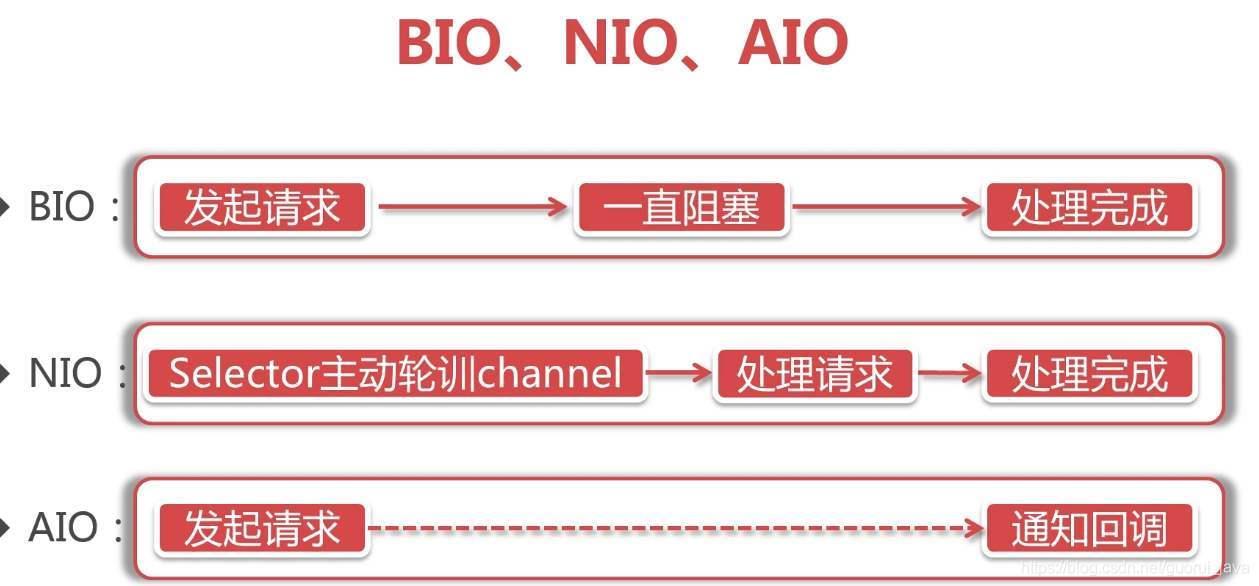
各IO对比

参考文章
https://blog.csdn.net/guorui_java/article/details/107081776
https://www.cnblogs.com/zhangxiaoji/p/16152141.html
https://zhuanlan.zhihu.com/p/555459665