利用kaggle的GPU训练自己的模型(项目)
目录
一、上传项目
网址:
登陆后,将项目(连同数据集和代码一起)压缩上传,上传需要梯子。

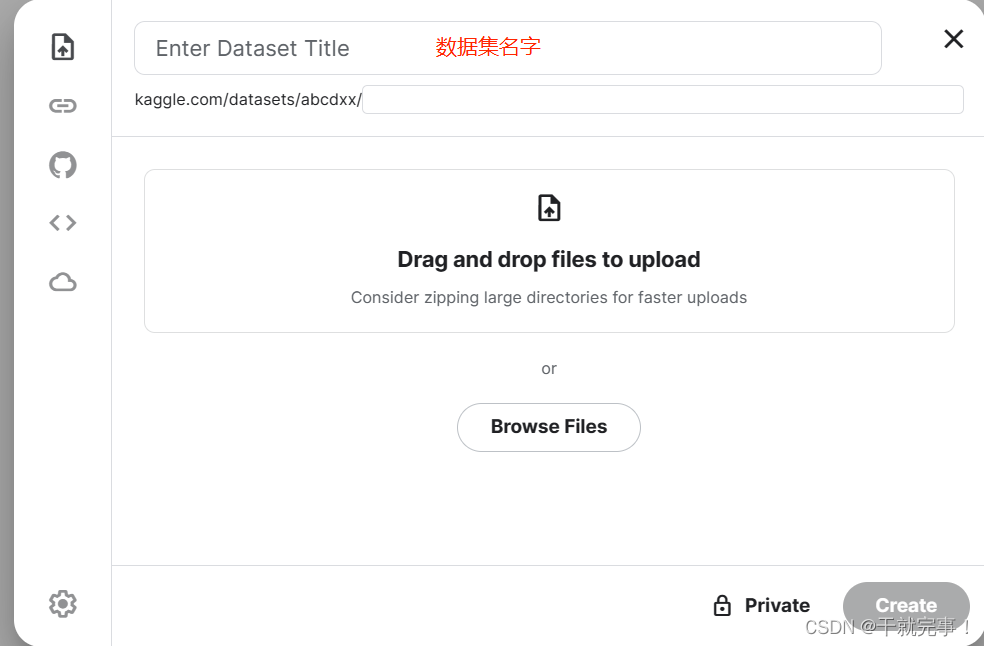
上传成功后点击create,kaggle会自动解压压缩包,处理完成后会有successful提示。
二、训练模型
1.导入项目
新建一个笔记本(同Jupyter notebook)

左上角的"note..."为该笔记本的名称,可以自行重命名,点击 + 新增一个cell,点击垃圾桶形状的按钮删除当前选定的cell。
选择Add Data添加数据

选择Your Datasets将显示你上传的数据集,选择数据集旁边的 + 则可以将数据集添加到当前笔记本

2.关于下包以及配置虚拟环境的问题
1)创建虚拟环境
我用conda创建虚拟环境报错,解决不了遂放弃。
2)下包
!pip install 包名(感叹号为英文感叹号)
ps:哦对,下包要连接网络,第一次使用kaggle的话需要先手机验证

注:
有的时候会发现之前下了的包一段时间后又不存在了,这个时候报错"no model name..."只能重新下。
因为我的项目用到了transformers,虽然kaggle内含transformers,但它的版本比我需要的高,想去降级transformers,下不下来,遂放弃,后来直接使用kaggle内置的transformers运行项目,发现成功跑起来了,不懂,能跑就行。
kaggle内的tensorflow版本是2.0的,我尝试过下载tensorflow1.0版本,下载失败,遂放弃。
综上,kaggle内有很多库,直接运吧,缺啥补啥。
3.训练模型
1)两种方法:
1.!python xxx.py
注:使用此语句需确保代码在本地的时候已调试通,否则报错只能在本地改好后再重新上传,如果项目很大的话上传很浪费时间。
2.将你需要运行的代码复制粘贴到一个cell里,这样你可以直接在这里调试你的代码,不需要回到本地改了再上传。
(很重要!!!)不管你使用哪种方法,都建议在你的代码里面使用的文件路径最好用相对路径,因为你使用Add Data添加数据时,你的数据的路径其实是/kaggle/input/数据集的名字(就是上传数据时命名那个),如果使用绝对路径的话,只能回到本地改了再上传,但使用相对路径的话,你就可以通过
cd /kaggle/input/数据集的名字
将你的工作路径定位到此,此时运行程序的话就不会报找不到文件的错误。
2)关于写文件的问题
如果你的模型在训练过程需要写文件,那么你就可以通过下述方法将你的数据复制到/kaggle/working/目录下,因为input目录只可读,而working目录可读可写。
(如果想在input运,则要更改写文件的地址,很麻烦不推荐)
import shutil # 复制文件或目录 shutil.copytree('/kaggle/input/数据集名字', '/kaggle/working/随便取个名字')注:能不能就这样 ‘/kaggle/working/’ 答:不知道,可以尝试一下
欸,写到这里,既然working目录可读可写,那是不是可以将需要修改的文件复制到此修改呢,网上搜一搜有博主这么讲过,但因为我的模型训练时要用到别的文件,所以我将整个项目复制到working后,查看下一级目录后转半天转不出来,目录分级较多的我直接放弃。
还有一个注意点,working下的文件在一段时间后会被清空。但将模型放到该目录下离线训练没有问题。
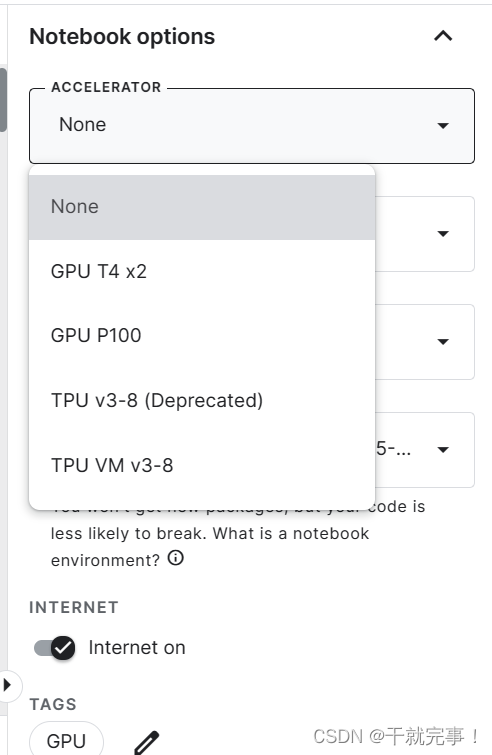
3)开启GPU
免费的GPU训练时间一周只有30个小时,建议先用CPU调试好了之后再启动GPU。
4)离线训练
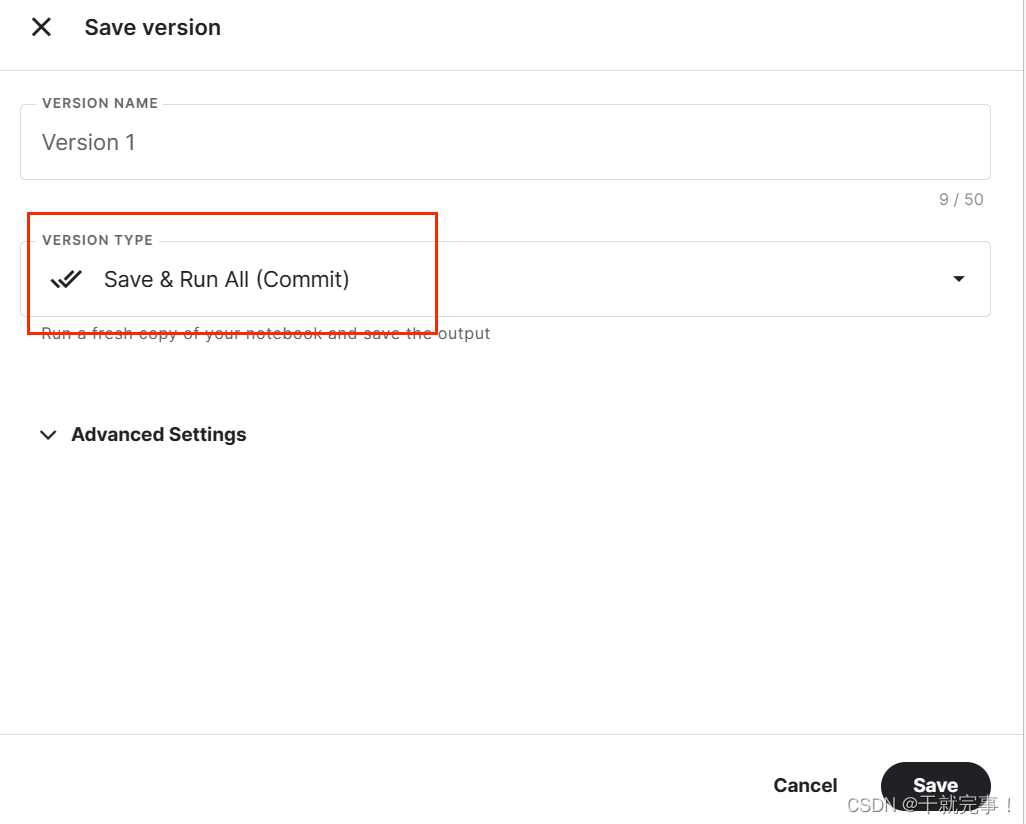
若模型训练时间较久的,不建议直接在cell中训练,因为你一段时间不操作后会掉线。建议选择右上角的 "save version”离线训练,但一次训练好像最多只能跑9小时。
记得选这个,然后save就行。
4.下载日志、运行结果什么的


5.关掉GPU
关GPU也是在这里,然后 "save version”

注:
不要在这里关GPU,没有用

三、模型预测
如果模型预测可以用CPU的话,从kaggle上下载输出结果后可直接在本地运行。
当然也可以在kaggle里运行。