BIO到NIO、多路复用器, 从理论到实践, 结合实际案例对比各自效率与特点(下)
本篇文章是BIO到NIO、多路复用器, 从理论到实践, 结合实际案例对比各自效率与特点(上)的下一篇, 如果没有看的小伙伴, 可以先看下, 不然可能会不连贯.
多路复用器简介
多路复用器是对于传统NIO的优化, 解决了传统NIO无法直接获取所有所有连接的状态, 需要挨个遍历所有连接查看是否准备就绪的问题, 这种方式会涉及到很多次系统调用, 用户态和内核态的切换,效率不高.
那多路复用器是怎样优化的呢?
首先要明白 多路的路是谁-------->其实就是每个IO连接
每个路有没有数据谁知道呢-------->内核知道, 那既然内核自己知道某一时刻有哪些连接是有连接的, 是不是我们直接调用对应功能方法即可, 所以这里就有个多路复用器, 你调用这个多路复用器, 它就会给你返回所有的路的IO状态.
这个就可以通过一次系统调用,获取所有连接的IO状态的结果集
然后程序自己对有状态的(准备好的)连接进行读写,这样才是高性能
这里注意,多说一句, 只要程序自己读写数据, 你的IO模型就是同步的
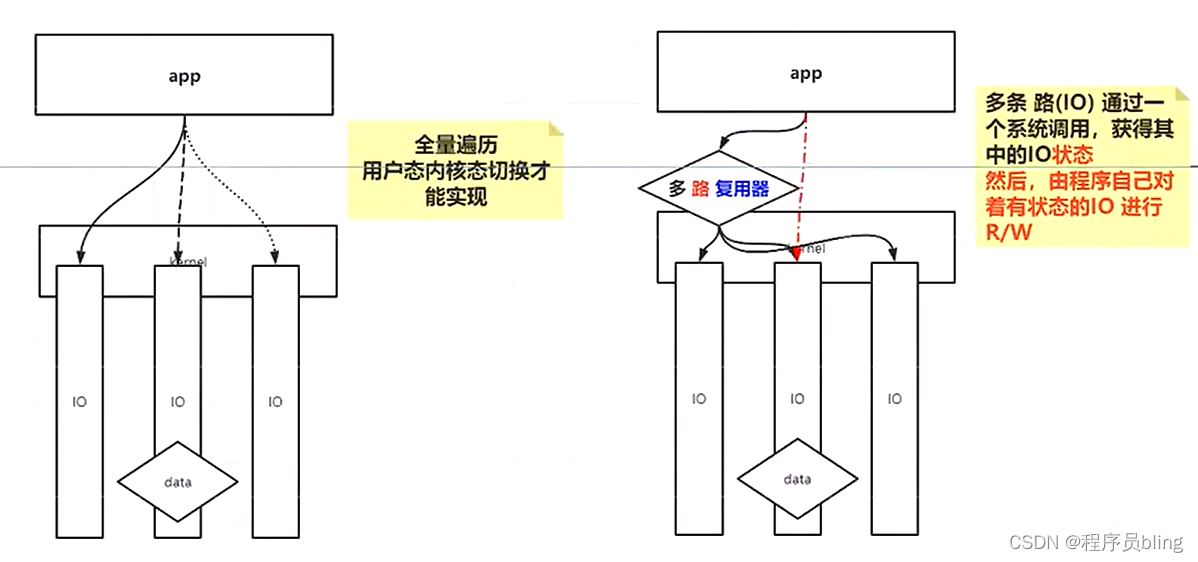
多路复用器的两个阶段
多路复用器有两个阶段, 或者说是内核的两类实现, 这两类实现的最终目的都是一样的, 就是帮你返回所有IO连接的IO状态(是否可读), 但是实现细节有些许差别, 可以理解为epoll是select poll的升级版.
这里还是再提示下, 以下的两种实现讲的操作系统中的实现, 并不是Java中的方法.
-
select poll
需要把所有IO连接存到一个集合中, 把这个集合传递拷贝给内核, 也就是调用select或者poll, 内核会把集合中准备就绪的连接给个特殊标识, 然后返回.
这样程序就可以直接知道哪些连接是有状态的, 从而直接进行读取数据
弊端:
假如有1w个连接, 每次都需要把这个1w个连接拷贝给内核, 这个拷贝就是损耗点, 每次需要重复拷贝数据给内核. -
epoll
正是因为select, poll 有自身的弊端, 这才催生了epoll.
优化
以空间换时间, 开辟了内核空间, 缓存了应用程序的连接信息. 这样就不需要重复的拷贝数据.无损耗才是高性能.实现步骤
1. 在一个linux机器上, 有很多的应用程序, 所以一个应用程序想要使用epoll的话, 首先需要在内核中 开辟空间------对应epoll_create系统调用
2. 然后当连接创建后, 把这个连接加入到该空间------对应epoll_ctl(add)系统调用
3. 然后才是进行询问, 看看有哪些IO连接准备就绪------对应epoll_wait系统调用
Java中的多路复用器封装
在java.nio的包下,封装了对于多路复用的实习和使用,也就是Selector类
Java中的Seletor底层用的是哪种实现? select poll 还是epoll?
Java其实会在运行的时候会动态的决定使用哪种实现, 因为它会调用固定的方法去启动多路复用器,即Selector.open, 你的程序可能跑在不同的内核之上, jdk会优先选择好的epoll, 但是如果没有epoll这个多路复用器的话,只有select或者poll, 也是可以正常运行的
主要使用方法介绍:
这里有三个主要的方法, 不管底层使用的是哪种实现, 都会调用这三个方法, 但是根据不同实现, 具体做的事情又不一样,区别如下:
- Selector.open
启动多路复用器, 优先选择epoll, 没有的话选择select或者poll.
如果是epoll的话, 需要在内核中开辟空间, 即调用epoll_create. - register
select、poll: 会在jvm里建一个数组, 把每个连接对应的文件描述符(fd4)都放进去.
epoll: 则相当于调用内核方法epoll_ctl(add), 将该连接加入到内核空间, 直接由内核管理. - select
select、poll: 则会将jvm中的数组传给内核, 即调用select(fd4)或者poll(fd4)
epoll: 相当于直接调用内核方法epol_wait, 直接询问内核
测试代码
服务端
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.*;
import java.util.Iterator;
import java.util.Set;
/**
* @ClassName:
* @Description:(描述这个类的作用)
* @author:
* @date:
*
*/
public class SelectorTest {
private static ServerSocketChannel server=null;
private static Selector selector;
static int port=9090;
static int count=5000;
static long startTime;
public static void initServer(){
try {
server = ServerSocketChannel.open();
server.configureBlocking(false);
server.bind(new InetSocketAddress(port));
//这里会在编译期间自动选择 多路复用器的 实现
//可能为select poll 也可能为epoll
selector = Selector.open();
server.register(selector, SelectionKey.OP_ACCEPT);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
initServer();
System.out.println("服务器启动了......");
startTime = System.currentTimeMillis();
try {
flag:
while (true){
//select相当于询问内核有无数据可读取 或者 有无连接可建立
//里面传入的参数是超时时间,传入0代表阻塞,一直等待有人建立连接或发送数据
//如果传入的>0, 比如200, 则会最多等待200毫秒,有没有都会返回一个结果
while(selector.select(0)>0){
//从多路复用器中取出所有有效的key
Set<SelectionKey> selectionKeys = selector.selectedKeys();
Iterator<SelectionKey> iterator = selectionKeys.iterator();
while(iterator.hasNext()){
SelectionKey key = iterator.next();
//获取之后要进行移除,否则会重复获取
iterator.remove();
//有新连接可建立
if(key.isAcceptable()){
acceptHander(key);
//可以进行读取
}else if(key.isReadable()){
readHander(key);
}
}
if(count <= 0){
System.out.println("处理5000个连接用时:"+(System.currentTimeMillis()-startTime)/1000+"s");
server.close();
selector.close();
break flag;
}
}
}
}catch (Exception e){
e.printStackTrace();
}
}
private static void readHander(SelectionKey key) {
//取出当前key所关联的客户端
SocketChannel client = (SocketChannel) key.channel();
//取出该客户端 对应的 buffer
//这个buffer是我们建立连接时传进去和 channel一对一绑定的
ByteBuffer buffer = (ByteBuffer) key.attachment();
buffer.clear();
int read=0;
try {
for(;;){
//从channel中读取数据写入到buffer中
read = client.read(buffer);
if(read==0){
break;
//这里可能有bug,客户端可能关掉,处理close_wait状态, 会一直监听到这个事件
// 这里直接简单暴力的关掉
}else if(read<0){
client.close();
break;
}else{
//对于buffer,刚刚是写,现在进行读操作,调用flip
buffer.flip();
byte[] bytes = new byte[buffer.limit()];
buffer.get(bytes);
String str = new String(bytes);
System.out.println(client.socket().getRemoteSocketAddress()+" -->" +str);
}
}
}catch (Exception e){
e.printStackTrace();
}
}
private static void acceptHander(SelectionKey key) {
try {
ServerSocketChannel channel = (ServerSocketChannel) key.channel();
SocketChannel client = channel.accept();
client.configureBlocking(false);
ByteBuffer buffer = ByteBuffer.allocate(8192);
//将这个新连接交给多路复用器去管理,后面多路复用器中才能监控这个连接, 在我们去获取的时候,给我们返回有状态的连接
//同时这里将channel和buffer 一对一 进行绑定,可以很方便的往里写入, 或者 读出来
client.register(selector, SelectionKey.OP_READ,buffer);
System.out.println("add client port:"+client.socket().getPort());
count--;
} catch (IOException e) {
e.printStackTrace();
}
}
}
测试使用的客户端代码还是和上篇文章中保持一致, 这里不再放了.
压测结果
以上所有说的都是理论, 而理论一定是需要实际结果来验证的, 我们这里就还是同样处理5000个连接, 并接收同样消息, 看看多路复用器的实际效果如何.
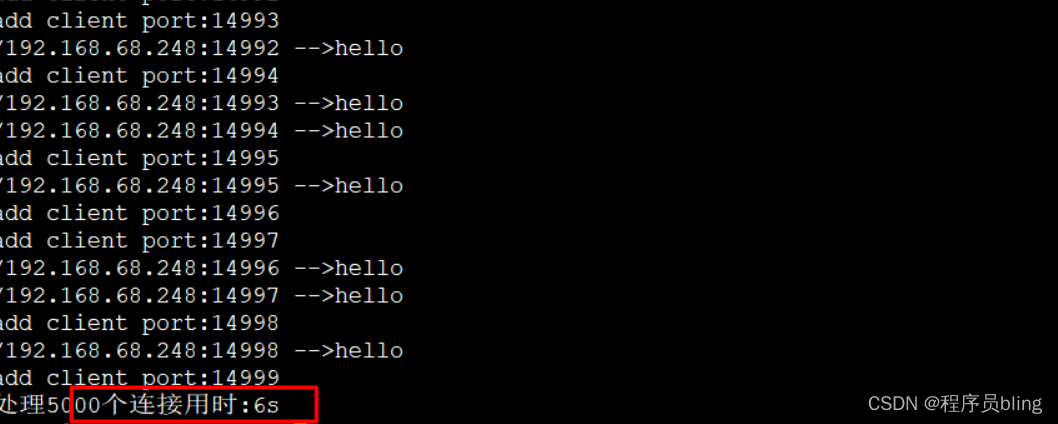
可以看到, 效果是非常非常明显的, 比BIO,NIO都要快太多了, 而且还代码还是单线程模型, 将其扩展成多线程, 效率将会更高.
总结
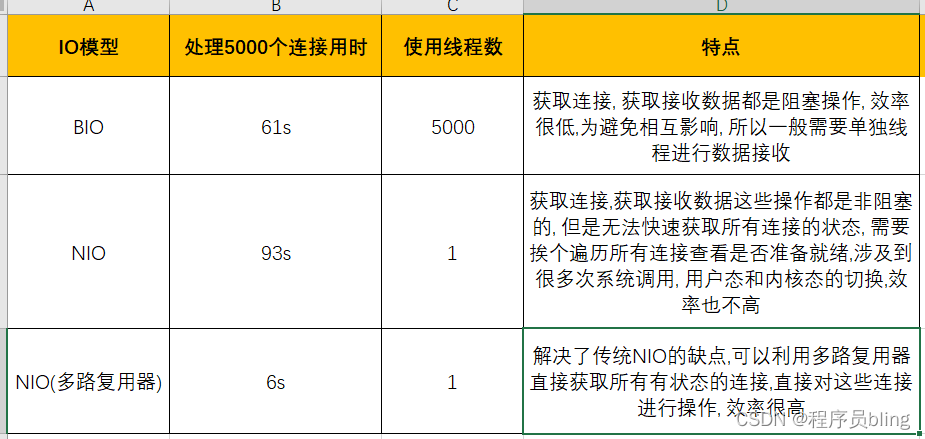
从BIO -> NIO -> 多路复用器, 我们分析了各自的缺点及演变过程, 并是实际结果对比了各自的效率, 相信你会更加印象深刻.
针对本文的测试结果总结如下:
今天的分享就到这里了,有问题可以在评论区留言,均会及时回复呀.
我是bling,未来不会太差,只要我们不要太懒就行, 咱们下期见.
