大数据Hadoop学习之——好友推荐
一、算法说明
好友关系如图:
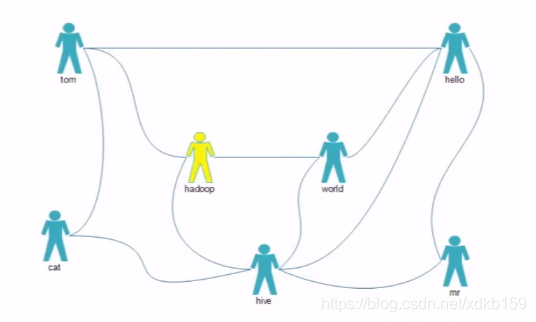
1、直接相连的表示两个人是直接好友关系;
2、两个人有相同的好友表示两个人是间接好友(当然可能两个人同时也是直接好友,如图hello和hive)。
3、好友推荐列表就是按照两个用户的共同好友数量排名
二、MapReduce分析
1、分两步MapReduce计算完成;
2、第一步先得到用户的间接好友关系数目,注意有直接好友关系的用户需要过滤掉;
3、第二步根据间接好友关系数就可以得到用户推荐列表。
三、MapReduce实现
输入数据
tom hello hadoop cat
word hadoop hello hive
cat tom hive
mr hive hello
hive cat hadoop word hello mr
hadoop tom hive word
hello tom word hive mr第一个是当前用户,后面的是其好友列表
第一步——计算好友间接关系数
一、mapper输出两种数据
1、对各用户的好友列表好友俩俩组合,输出间接好友关系;
2、当前用户和好友列表好友一一组合,输出直接好友关系。
注意!!!这里好友关系key需要顺序排序,避免重复记录,如hello:tom和tom:hello都表示同样两个人的关系。
public class FriendMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final Text text = new Text();
private final IntWritable mval = new IntWritable();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//样本数据:tom hello hadoop cat
String[] users = StringUtils.split(value.toString(), ' ');
for (int i = 1; i < users.length; i++) {
//和好友组成直接关系,组合好友关系按顺序排列,确保user1和user2不会因为顺序问题,而被认为是两对关系
text.set(MrCommUtil.orderConcat(users[0], users[i]));
mval.set(0);
context.write(text, mval);
for (int j = i + 1; j < users.length; j++) {
//列表好友俩俩组合间接关系
text.set(MrCommUtil.orderConcat(users[i], users[j]));
mval.set(1);
context.write(text, mval);
}
}
}
}
二、reducer统计同两个用户的间接关系数,并过滤已经是直接关系的一组用户。
public class FriendReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private final IntWritable rval = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//数据样本
//hadoop word 0
//hadoop word 1
//hadoop word 0
int num = 0;
for (IntWritable value : values) {
if (value.get() == 0) {
return;
}
num += 1;
}
rval.set(num);
context.write(key, rval);
}
}
三、输出结果集如下
cat:hadoop 2
cat:hello 2
cat:mr 1
cat:word 1
hadoop:hello 3
hadoop:mr 1
hive:tom 3
mr:tom 1
mr:word 2
tom:word 2
第二步——统计最佳推荐好友
一、mapper输入数据集为第一步的结果集,map把记录映射成正反两组
public class Friend2Mapper extends Mapper<LongWritable, Text, FriendRelation, IntWritable> {
private final FriendRelation mkey = new FriendRelation();
private final IntWritable mval = new IntWritable();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//数据样本:cat:hadoop 2
String[] strs = StringUtils.split(value.toString(), '\t');
String[] users = StringUtils.split(strs[0], ':');
mkey.setFrom(users[0]);
mkey.setTo(users[1]);
int n = Integer.parseInt(strs[1]);
mkey.setN(n);
mval.set(n);
context.write(mkey, mval);
mkey.setFrom(users[1]);
mkey.setTo(users[0]);
context.write(mkey, mval);
}
}
二、排序比价器根据第一个用户和关系数倒排序
public class Friend2SortComparator extends WritableComparator {
public Friend2SortComparator() {
super(FriendRelation.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
//排序先根据from,同from再根据n排倒序
FriendRelation f1 = (FriendRelation) a;
FriendRelation f2 = (FriendRelation) b;
int i = f1.getFrom().compareTo(f2.getFrom());
if (i == 0) {
return -Integer.compare(f1.getN(), f2.getN());
}
return i;
}
}
三、分组比较器根据第一个用户分组
public class Friend2GroupComparator extends WritableComparator {
public Friend2GroupComparator() {
super(FriendRelation.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
//分组只根据from分组
FriendRelation f1 = (FriendRelation) a;
FriendRelation f2 = (FriendRelation) b;
int i = f1.getFrom().compareTo(f2.getFrom());
return i;
}
}四、reduce取出关系数最大的推荐关系
public class Friend2Reducer extends Reducer<FriendRelation, IntWritable, Text, IntWritable> {
private final Text rkev= new Text();
private final IntWritable rval = new IntWritable();
@Override
protected void reduce(FriendRelation key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//样本数据:
//cat:hadoop 2
// cat:hello 2
// cat:mr 1
// cat:word 1
int n = key.getN();
//输出最大间接关系数的所有推荐
for (IntWritable value : values) {
if (n != value.get()) {
break;
}
rkev.set(key.getFrom() + "->" + key.getTo());
rval.set(key.getN());
context.write(rkev, rval);
}
}
}五、输出最终结果,用户推荐分最高的前两名
cat->hello 2
cat->hadoop 2
hadoop->hello 3
hello->hadoop 3
hive->tom 3
mr->word 2
tom->hive 3
word->mr 2
word->tom 2
六、完整代码及测试数据详见码云:hadoop-test传送门