如何设计一门计算机编程语言
一、概述
计算机编程语言顾名思义,是用来和计算机进行沟通的语言。计算机编程语言伴随着计算机的发明,作为计算机领域各种软件的基础,不断推动着计算机技术的发展。本文中,将主要关注设计开发一种计算机编程语言,对于其他类似的语言,比如MarkDown、数据查询语言、数据交换语言等不涉及。
计算机编程语言自从诞生以来,不断发展,很多已经逐渐消失在历史的长河中,当前(2022年)最流行的几门语言包括(**排名不分先后**):Python、Java、Javascript、C++、Kotlin、R、PHP、Go、C、Swift、C#等。使用计算机编程语言可能是本文读者在日常工作和生活中经常做的一件事情,那么计算机编程语言是如何设计的呢?设计和实现一门计算机编程语言复杂吗?我们什么时候有必要设计一门计算机编程语言呢?如何实现一门计算机编程语言呢?希望这篇文章能够解答上面的疑惑。
二、TinyLanguage定义及功能
很多人学习的第一门编程语言是C语言,C语言作为一门很古老的语言(1967年发明),至今已经有50多年的历史,但是当今依然非常流行。比如现在已经渗透到大家生活中方方面面的Linux操作系统就是主要用C语言开发的,大家在生活中见到的各种以单片机为主控的嵌入式设备也是大部分以C语言作为编程语言的。这里想表达的意思是,C语言除了历史悠久、非常流行之外,它也拥有独特的设计之美、简洁之美。我们来看一下一个简单的C语言程序:
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[]) {
int i, n;
int t1 = 0, t2 = 1;
int nextTerm = t1 + t2;
if (argc != 2) {
fprintf(stderr, "please input one number\n");
return -1;
}
n = atoi(argv[1]);
for (i = 3; i <= n; ++i) {
t1 = t2;
t2 = nextTerm;
nextTerm = t1 + t2;
}
printf("%dth value is %d\n", n, nextTerm);
return 0;
}上述语言的作用是求出fibonacci数列的第N个数,并进行打印。将其保存为一个文本文件fib.c,然后执行下面命令,可以得出对应的结果。比如本例中,可以得出fibonacci数列的第10个数为55。
➜ tmp gcc -o fib fib.c -O2 -Wall
➜ tmp ./fib 10
10th value is 55仔细观察这段语言,我们可以得出以下结论:
1. C语言程序代码是以文本形式保存的。
2. C语言程序中的关键字、变量、常量、运算符等以特殊符号、空格等形式进行分割
3. 运算符、变量、常量等组成了"表达式",一个或者多个表达式组成了"语句",一个或者多个“语句”又组成了"程序"。
参考伟大的C语言,我们来设计一门语言,也实现类似于上述程序相似的功能,它包括以下支持:
1. 支持变量、常量,但仅支持4字节整型数据
2. 支持if/else,支持for循环
支持内置函数调用
我们可以给这个新的语言叫做Tiny Language,因为它真的是一个非常小的语言。为实现TinyLanguage,参考C语言,我们给它定义几个概念:
l 变量(variable):以字母开头,可以包含数字的字符串可以作为变量,变量中可以存放整数值,所存储的整数值可变。变量的作用域是整个程序(有别于C语言的局部变量)
l 常量:整数数值
l 关键字:if/else/for
内置函数调用:支持输出一个整数值的print方法,参数个数为1,参数类型为int
三、TinyLanguage词法解析
为实现TinyLanguage,我们首先要对TinyLanguage的程序代码进行解析,通过之前的讨论,可以了解到,程序代码一般以文本形式保存,我们设计的TinyLanguage的程序也是以文本形式存在,那么为实现对TinyLanguage程序的解析,实际上就是对文本文件进行解析。
对文本文件进行解析最直接的做法是写一个文本解析器,但是这个过程比较繁琐(注意是繁琐而不是复杂),好在我们生活在2022年,已经有前人设计了很多比较好的工具,比如flex就是为了此类工作而设计的,Flex是为词法解析设计的,它可以根据定义的规则来生成一段C语言,这个C语言程序的主要功能就是对文本文件按照预定义的词法进行解析。Flex的文档可以参考这里https://westes.github.io/flex/manual/。
1. 定义常量和标识符
/* %{ 和 %}中间的字符被原封不动的传递到生成的解析器C代码中 */
%{
#include <stdio.h>
#include <stdlib.h>
%}
/* 使用正则表达式定义了DIGIT/ID */
DIGIT[0-9]
ID[a-zA-Z][a-zA-Z0-9]*
/* %%之前的为定义段,之后的为规则段 */
%%
/* 规则: 行为, 行为多行时,用{} 进行包围 */
{DIGIT}+ { /* 匹配规则与行为 */
printf("An integer%s(%d)\n", yytext, atoi(yytext));
}
{ID} {
printf("Anidentifier(%s)\n", yytext);
}
[\t\n]+ /* eat up whitespace */
. printf( "Unrecognized character:%s\n", yytext );
%%
/* %% 之后的为用户代码段 */
int yywrap() {
return 1;
}
int main(int argc, char *argv[]) {
yyin = stdin;
yylex();
return 0;
}上面的代码段采用flex的格式描述了常量以及标识符(变量是标识符的一种),对此段代码进行编译可以得到一个采用C实现的解析器,这个解析器可以解析常量以及标识符两种类型。我们测试一下,在linuxshell中执行下面命令
flextiny_lang.ll && gcc -o parser lex.yy.c && ./parser
# 以下为输入的字符,输入完成后按回车
123 abc abc123
# 以下为输出
An integer 123(123)
An identifier(abc)
An identifier(abc123)
# 按ctrl-D退出可以看出,这个解析器已经可以正常解析常量、标识符了。
flex的输入文件tiny_lang.ll被“%%”分割为了三部分,第一部分为定义段,中间部分为规则段,最后一部分为用户代码段。
l 定义段用来定义在规则段用到的样式,比如DIGIT就是使用正则表达式定义的一个样式,在规则段可以对它进行引用。
l 规则段的格式为 "Patern Action",其中Patern可以引用定义段定义的样式,Action是指匹配到规则后所要执行的行为,可以省略或者用C语言的语句来表示。
l 用户代码段会被flex原封不动的插入到最终生成的解析器中。
2. 定义关键字与运算符
...
%%
"if" printf("if keyword\n");
"else" printf("else keyword\n");
"for" printf("for keyword\n");
[-()<>+*/;{}] printf("operator %s\n", yytext);
%%
...执行下面的命令后,根据输出可以看到关键字、运算符都可以被正确解析。这里有一点要注意,关键字要放在标识符的前面,否则其会优先匹配标识符,造成关键字无法被解析:
# 以下命令在linux shell中输入
➜ flex tiny_lang.ll && gcc -o parser lex.yy.c && ./parser
# 以下从终端中输入
+ - if else abc 123
# 输出结果
operator +
operator -
if keyword
else keyword
An identifier(abc)
An integer 123(123)3. 完整的词法解析
从上面的章节,我们了解到了flex中解析词法的基本知识,在这一小节中,我们将会定义TinyLanguage的完整的词法。
/* %{ 和 %}中间的字符被原封不动的传递到生成的解析器C代码中 */
%{
#include <stdio.h>
#include <stdlib.h>
#include "tiny_lang_types.h"
#include "tiny_lang.tab.h"
%}
/* 使用正则表达式定义了DIGIT/ID */
DIGIT [0-9]
ID [a-zA-Z][a-zA-Z0-9]*
/* %%之前的为定义段,之后的为规则段 */
%%
/* 规则: 行为, 行为多行时,用{} 进行包围 */
"if" {
printf("if keyword\n");
return IF;
}
"else" {
printf("else keyword\n");
return ELSE;
}
"for" {
printf("for keyword\n");
return FOR;
}
{DIGIT}+ { /* 匹配规则与行为 */
printf("An integer %s(%d)\n", yytext, atoi(yytext));
//yylval.integer = atoi(yytext);
return INTEGER;
}
{ID} {
printf("An identifier(%s)\n", yytext);
//strcpy(yylval.identifier, yytext);
return VARIABLE;
}
[-()<>+*/;={}] {
printf("operator %s\n", yytext);
return *yytext;
}
[ \t\n]+ /* eat up whitespace */
">=" return GE;
"<=" return LE;
"==" return EQ;
"!=" return NE;
"&&" return AND;
"||" return OR;
. printf( "Unrecognized character: %s\n", yytext );
%%
/* %% 之后的为用户代码段 */
int yywrap() {
return 1;
}
int main(int argc, char *argv[]) {
yyin = stdin;
while (1)
yylex();
return 0;
}上面的代码段中,我们补充了几个额外的操作符,比如">=","&&"等,另外还有一个不同的地方在于对于这些操作符,以及if/else/for等关键字等,在其"行为"代码中,return了GE/IF/ELSE等,它们是由tiny_lang.tab.h文件定义的,我们在后面的章节中进行描述。
在main函数中,我们调用yylex()时使用了一个while(1)循环,这是因为现在的词法解析“行为”中,已经有包含return语句,这代表本次解析结束,如果不加如while(1)循环,则程序不会继续解析了。
这样我们就定义好了完整的TinyLang的词法,一共用了60行左右的代码,可以用下面的命令运行:
➜ flex tiny_lang.l && gcc -o parser lex.yy.c && ./parser
for (i=0;i<10;i++) a=a+1;
for keyword
operator (
An identifier(i)
operator =
An integer 0(0)
operator ;
An identifier(i)
operator <
An integer 10(10)
operator ;
An identifier(i)
operator +
operator +
operator )
An identifier(a)
operator =
An identifier(a)
operator +
An integer 1(1)
operator ;可以看出对于一个常见的for循环语句,我们的词法解析已经可以正常工作了。
四、TinyLanguage的语法解析
讲到语法解析,不得不提一下巴科斯范式,巴科斯范式描述的是一种上下文无关文法语言。什么是上下文无关文法呢,这里举一个知乎上看到的一个例子(https://www.zhihu.com/question/21833944):
Sent -> S V O
S -> 人 | 天
V -> 吃 | 下
O -> 雨 | 雪 | 饭 | 肉
左边的Sent、S、V、O,z什么是上下文无关文法呢,这里举一个知乎上看到的一个自然语言的例子:
Sent-> S V O
S -> 人 | 天
V -> 吃 | 下
O -> 雨 | 雪 | 饭 | 肉左边的Sent、S、V、O等称之为non-terminal,它是由右边的字符推导出来的,右边的字符,比如S V O,人,天等可以是non-terminal或者terminal,不会出现在左边的字符称之为terminal,比如人、吃、雨、雪等。“|”代表的是“或”的意思,比如S->人|天,代表的意思是“人”或者“天”均可以推导出S。
我们来看一段话,“天吃肉”的推导过程为:
Sent-> SVO -> 天VO -> 天吃O-> 天吃肉
虽然“天吃肉”读起来有点奇怪,但是由于Sent/S/V/O都是单一的non-terminal,不需要与其他的non-terminal后者terminal搭配,因此与“上下文”无关。当我们按照下述规则来表示时,
Sent-> S V O
S -> 人 | 天
人V ->人吃
天V ->天下
下O ->下雨 | 下雪
吃O ->吃饭 | 吃肉想要推导出“天吃肉”这样的规则是无法进行的,可以看出推导到第四步时就无法进行了。
Sent->SV O->天VO->天下O
巴科斯范式就是描述的一种上下文无关的文法,我们常见的语言中,比如C中的大部分文法是上下文无关的,但是一些特殊的语句是上下文相关的,比如“a * b;” 这条语句,被解析为乘法操作还是指针定义操作,实际上是与上下文相关的,如果前面定义了一个有一个语句"typedef int a",那它可以解析为一个指针定义操作。若前面顶一个符号“a”和“b”,那这里可以解析为乘法操作,跟前面的上下文相关的。
我们这里的TinyLanguage使用上下文无关文法来表示,不涉及较复杂的上下文相关文法。
1. Bison语法
Bison是GNU的一个Parser生成器(注意是生成解析器的工具,本身不是一个解析器),可以将上下文无关的语法解析为确定的LR parser,关于LR parser的相关内容
可以参考https://en.wikipedia.org/wiki/LR_parser。
本章中将会使用Bison来生成一个TinyLanguage的语法解析器。
%{
前言部分
%}
声明部分
%%
语法规则
%%
结尾部分Bison的规则文件如上述分为三个部分,分别是声明部分、语法规则、结尾部分,其中声明部分中,还可以用 "%{ %}"来前言部分。
l 前言部分可以用C语言的语法添加#include,声明函数或者定义全局变量,用于后面的代码使用。
l 声明部分用来定义terminal与non-terminal,并且可以用来声明优先级等。
l 语法规则部分的唯一用途就是定义语法规则,格式如下:
result:
rule1-components…
|rule2-components…
…其中result是non-terminal,而comonents是生成这个result的non-terminal或者terminal的组合。
结尾部分与前言部分类似,会原封不动的copy到解析器中,用来保证解析器的正确执行。
2. 声明部分
%union {
int integer;
char identifier[256];
struct listnode *node_ptr;
};
%token <integer> INTEGER
%token <identifier> VARIABLE
%nterm <node_ptr> expr stmt stmt_list
%token IF
%nonassoc IFX FOR
%nonassoc ELSE
%nonassoc '='
%left AND OR
%left GE LE EQ NE '>' '<'
%left '+' '-'
%left '*' '/'
%precedence NEG声明部分用来定义terminal和non-terminal,上面的代码段是TinyLanguage的声明部分。
声明部分中,首先使用到了%union关键字,%union关键字是用来定义语义类型的,TinyLanguage中定义了三种数据类型,分别是integer代表整数,identifier代表标识符,node_ptr用来代表复杂数据类型,可以进行动态扩展。
这里面用到了%token关键字,%token是用来定义一个terminal类型的符号,比如“%token <integer> INTEGER”是定义了一个名称为INTEGER的terminal,它的类型是integer类型,一般情况下,若语法中支持多种类型的数据,则需要通过<>来指明一下terminal或者non-terminal的类型。在TinyLanguage中,由于要支持整数、变量、以及复杂类型,因此我们需要特殊声明terminal INTERGER的类型为integer,声明VARIABLE的类型为identifier,声明expr stmt stmt_list的类型为node_ptr。
注意到exprstmt stmt_list的定义中,用到了%nterm,这个关键字是用来定义non-terminal类型的符号的关键字,其余用法用%token类似。
%left%right %precedence %nonassoc除了定义符号本身之外,还定义了符号(运算符)的关联性、优先级。在同一行语句中声明的符号(运算符)具有相同优先级,否则在后面的符号(运算符)具有更高的优先级。如果运算符(符号)具有关联性,还可以用%left、%right来指明其关联性,比如“+-*/”等是左关联的,"="一般是右关联的,TinyLanguage中,使用%nonassoc来声明“=”,其目的是将“a=b=1;”这样的语句认为是不合法的。
注意到“-”可以代表减法也可以代表取相反数,这里声明了NEG的优先级为最高,且是右关联,这样就可以正常使用“-1-2-3”这样的表达式了,其中第一个“-”代表的是相反数,其优先级是最高的,后面的“-”是减法,优先级相对较低。NEG后面的章节中还会用到。
%precedence来定义则会仅声明了优先级,而没有声明其关联性,当出现conflict时,就会出现一些异常。
我们还定义了IFELSE IFX FOR等关键字的优先级和关联性,以“if”语句为例,假如有下面规则(规则定义参考下面章节)
IF '('expr ')' IF '(' expr ')' stmt • ELSE stmt可以按照下面方式进行解析,这种方式叫做shift,当解析到第二个IF时(•处),继续寻找下一个ELSE。
↳1: IF '(' expr ')' stmt
↳2: IF '(' expr ')' stmt • ELSE stmt也可按照下面方式进行解析,当解析到第二个IF时(•处),与第一个IF进行匹配,然后与ELSE匹配,这种方式叫做reduce。
↳ 1: IF '(' expr ')' stmt ELSE stmt
↳2: IF '(' expr ')' stmt •当出现两种解析结果时,就叫做产生了conflict,上述conflict称之为shift-reduce
conflict。
在TinyLanguage中,“else”要匹配与之最近的规则,为了达成这个目的,我们为第一条规则为了解决上面的问题,我们引入了"%nonassoc IFX",并且在规则中这样写
stmt:
IF '(' expr ')' stmt %prec IFX { $$ =parse_operator(IF, 2, $3, $5); }这里的IFX指明了,当遇到ELSE这个%token时(•处),本条规则(reduce)采用IFX的优先级,其优先级低于ELSE(reduce),因此优先执行reduce操作,也就是让else与最近的if进行匹配。
3. 语法规则
program:
function { DEBUG("program done!\n"); }
;
function:
function stmt {
list_add_tail(&g_stmt_list, $2);
}
| /* NULL */
;
stmt:
';' { $$ = parse_operator(';', 2, NULL, NULL); }
| expr ';' { $$ = $1; }
| '{' stmt_list '}' { $$ = $2;}
| '{' '}' { $$ = parse_operator(';', 2, NULL, NULL); }
| IF '(' expr ')' stmt %prec IFX { $$ = parse_operator(IF, 2, $3, $5); }
| IF '(' expr ')' stmt ELSE stmt { $$ = parse_operator(IF, 3, $3, $5, $7); }
| FOR '(' expr ';' expr ';' expr ')' stmt { $$ = parse_operator(FOR, 4, $3, $5, $7, $9); }
;
stmt_list:
stmt { $$ = $1 }
| stmt_list stmt { $$ = parse_operator(';', 2, $1, $2); }
;
expr:
INTEGER { $$ = parse_constant($1); }
| VARIABLE { $$ = parse_variable($1); }
| VARIABLE '=' expr { $$ = parse_operator('=', 2, parse_variable($1), $3); }
| expr '+' expr { $$ = parse_operator('+', 2, $1, $3); }
| expr '-' expr { $$ = parse_operator('-', 2, $1, $3); }
| expr '*' expr { $$ = parse_operator('*', 2, $1, $3); }
| expr '/' expr { $$ = parse_operator('/', 2, $1, $3); }
| expr '<' expr { $$ = parse_operator('<', 2, $1, $3); }
| expr '>' expr { $$ = parse_operator('>', 2, $1, $3); }
| expr AND expr { $$ = parse_operator(AND, 2, $1, $3); }
| expr OR expr { $$ = parse_operator(OR, 2, $1, $3); }
| expr GE expr { $$ = parse_operator(GE, 2, $1, $3); }
| expr LE expr { $$ = parse_operator(LE, 2, $1, $3); }
| expr EQ expr { $$ = parse_operator(EQ, 2, $1, $3); }
| expr NE expr { $$ = parse_operator(NE, 2, $1, $3); }
| '(' expr ')' { $$ = $2; }
| '-' expr %prec NEG {$$ = parse_operator(NEG, 1, $2); }
;规则部分的一般形式为:
result:
rule1-components…
|rule2-components…
…
;其中result是non-terminal类型的符号,表明本条规则是描述的是哪个non-terminal,components表明是哪些terminal和non-terminal组成了这个目标“result”。
每条comonents后面还可以跟一个用 “{}”括起来的C表达式,用来表明本条规则在解析的同时,所需执行的操作,是不是相当简单。
TinyLanguage中,将整体程序分成了表达式(expr),语句(stmt),语句表(stmt_list),程序(program)几部分。其中表达式与C语言中的表达式类似,包括普通的算术预算、逻辑运算、条件判断等,还包括括号操作等;语句是表达式加结尾符号“;”、“{}”括起来的语句、if/else语句、for循环等。语句表是由一条或者多条语句组成,程序是由语句组成的。
上面代码中的语法规则即是对TinyLanguage的语法设计,以表达式(expr)为例,表达式(expr)可以是整数,也可以是变量,因此可以这样书写规则:
expr:
INTEGER
| VARIABLE
;表达式(expr)还可以是表达式间的算术运算,还可以使用括号括起来,因此可以这样书写规则:
expr:
expr '+' expr
| expr '-' expr
...
| '(' expr ')'
;同样的,语句(stmt)是由表达式(expr)加';'组成,或者是由“{}”括起来的语句列表,因此可以这样书写:
stmt:
expr ';'
| '{' stmt_list '}'
;还可以是“if”语句、“for”语句等,因此可以这样书写:
stmt:
IF '(' expr ')' stmt %prec IFX
| IF '(' expr ')' stmt ELSE stmt
| FOR '(' expr ';' expr ';' expr ')' stmt
;同理,按照规则可以写出语句列表(stmt_list),函数(function),程序(program)的语法规则,本章节中不做详细描述。
这里注意到,result可以由多条规则生成,规则之间使用“|”进行分割。例子中规则后面还一般情况下,书写了“{}”, 并且在“{}”内,使用了类似C语言的代码,还使用了“$$”,"$1", "parse_operator"等,这些内容是bison里面与这条规则对应的行为(action),它的目的是当此规则被识别出来时,需要执行的操作。由于规则描述的是产生语义值(semantic value)的产生过程,因此规则对应的行为即是产生此语义值对应的操作。
在行为段中,"$$"代表语义值,$N代表第N个组成部分的语义值,比如下述行为,代表的是表达式的语义结果是由第一个组件(第一个expr)与第三个组件(第二个expr)的加法产生的。且最终会真正转化成C语言的语句,产生在最终的TinyLanguage Parse中。
expr:
expr '+'expr { $$ = $1 + $3; }五、语法解析过程
前面章节描述了TinyLanguage的词法解析、语法解析、语法规则对应的行为等,本章节主要描述语法解析的实现。
1. 解析整型常量
整型常量的解析是相对简单的,在前面章节中,我们介绍了TinyLanguage的数据类型,使用integer、identifier、node_ptr来表示TinyLanguage中的数据类型。这里我们首先介绍的是整型数据类型的语法解析。
expr:
INTEGER { $$ = parse_constant($1); }从前面的知识我们可以知道,parse_contant($1)即为生成语义值(semantic value)的过程,由于expr的数据类型被设置为了node_ptr类型,而INTEGER的数据类型被设置为了integer,因此parse_constant的原型为:
struct listnode* parse_constant(int);根据上面的知识,我们可以把这个声明放到前言部分。以便于后续使用到它时避免发生函数未定义的错误。
parse_contant的具体实现也比较简单:
struct listnode* parse_constant(int val) {
struct nbr_node *ptr = malloc(sizeof(struct nbr_node));
ptr->ast_node.type = NT_NBR;
ptr->value = val;
return &ptr->ast_node.node;
}申请了一个nbr_node大小的内存,并且将其中的元素进行赋值,并将listnode类型的数据指针放回。其中,相关的定义如下:
enum NodeType {
NT_OPR = 0,
NT_NBR,
NT_VAR,
NT_NON,
};
struct listnode
{
struct listnode *next;
struct listnode *prev;
};
struct ast_node {
enum NodeType type;
struct listnode node;
};
struct nbr_node {
struct ast_node ast_node;
int value;
};对linux内核比较熟悉的读者看到上述数据结构,应该已经猜出,TinyLanguage在这里是要把掐中的各种数据结构通过listnode,组装成一个树状的结构。
可能读者在这里会产生这样的疑惑,parse_contant的形参val,是怎么被赋值过来的呢。其实这里的赋值操作是需要跟词法解析里面相关联的:
{DIGIT}+ { /* 匹配规则与行为 */
printf("An integer %s(%d)\n", yytext, atoi(yytext));
yylval.integer = atoi(yytext);
return INTEGER;
}这样bison在解析”$$= parse_constant($1);”时,才会自动把$1解析为yylval.integer,从而保证整条链路的正确执行。
2. 解析变量
变量的解析与整数的解析类似,规则的定义如下
expr:
VARIABLE { $$= parse_variable($1); }parse_variable的实现方式如下:
struct listnode* parse_variable(const char* name) {
struct var_node *ptr = malloc(sizeof(struct var_node));
printf("parsing variable %s\n", name);
ptr->ast_node.type = NT_VAR;
ptr->name[sizeof(ptr->name) - 1] = '\0';
strncpy(ptr->name, name, sizeof(ptr->name) - 1);
return &ptr->ast_node.node;
}var_node的定义如下:
struct var_node {
struct ast_node ast_node;
char name[256];
int value;
};与解析常量类似,需要在词法解析中,也添加对应的数据才可以。这样parse_variable的实参才会被正确设置为yylval.identifier。
{ID} {
printf("An identifier(%s)\n", yytext);
strcpy(yylval.identifier, yytext);
return VARIABLE;
}3. 解析运算符
TinyLanguage中用来描述运算符的数据结构是opr_node,其定义方式如下,可以看到除了包含默认的struct ast_node类型之外,还多了3个成员,分别是opr,用来保存运算符的类型;nops,用来记录有几个操作数,以及使用listnode双向链表来表示的expr_list,其将多个操作数通过链表串接了起来。
struct opr_node {
struct ast_node ast_node;
int opr;
int nops;
struct listnode expr_list;
};parse_operator的实现方式,跟之前解析整型与解析变量最大的不同在于其引入了可变参数,这是因为对于一个运算符来讲,它的操作数的数量是可变的,因此我们试用了va_start、va_arg系列函数来处理可变参数。
由于操作数的数量是可变的,在解析操作符时,我们还试用双向链表把几个操作数链接了起来。
struct listnode* parse_operator(int op, int nops, ...) {
va_list ap;
struct opr_node *ptr = malloc(sizeof(struct opr_node));
ptr->ast_node.type = NT_OPR;
ptr->opr = op;
ptr->nops = nops;
list_init(&ptr->expr_list);
va_start(ap, nops);
for (int i = 0; i < nops; i++) {
struct listnode *node;
node = va_arg(ap, struct listnode*);
/* 将操作数加到链表的末尾 */
list_add_tail(&ptr->expr_list, node);
}
va_end(ap);
return &ptr->ast_node.node;
}上述代码看似简单,实际上是语法数生成过程的精髓,以’b=a+3;‘为例,它实际上会生成以下形式的抽象语法树:
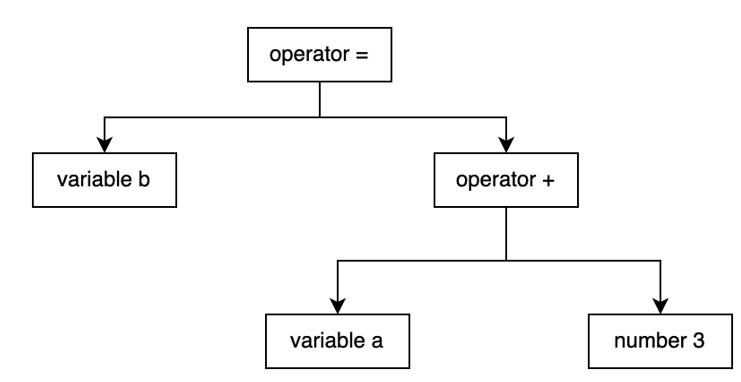
以稍微复杂的下述语句为例,其生成的抽象语法树为:
if (a> 0) {
sum = sum + 1;
}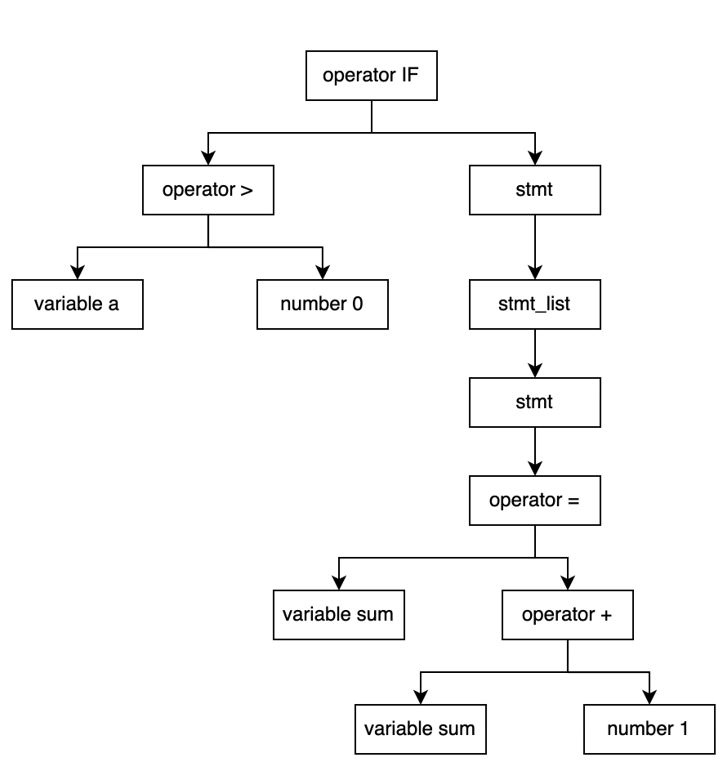
可以看出,即使一条简单的if语句,通过TinyLanguage生成的抽象语法树也是比较复杂的,但是复杂的图形下,也蕴含着最单纯的数据简单数据结构:nbr_node, var_node, opr_node。通过它们内部的链表节点的相互串接,组成了一个漂亮的图。
六、语法树的执行过程
生成抽象语法树之后,就可以对语法树进行执行操作了。执行操作的输入参数为struct listnode*, 代表执行的实体是expr, stmt, stmt_list中的一种。后面将从简单到复杂,讲述NUMBER类型、VARIABLE类型以及OPERATOR类型的node的执行过程
1. 执行整型常量
对于整型常量的执行,我们直接返回这个node中记录的数值即可。
struct ast_node *ast = node_to_item(node, struct ast_node, node);
struct nbr_node *nbr_node = node_to_item(ast, struct nbr_node, ast_node);
return nbr_node->value;这里使用到的node_to_item与linux内核中的container_of是一种实现方式,其目的是为了获取nbr_node的地址,从而获取到value的数值。
2. 执行变量
变量的执行稍微复杂,因为变量的保存与读取涉及到变量的保存、查找两个流程。为了对变量进行保存,我们定义了如下数据结构:
struct sym_node {
char name[256];
int value;
struct listnode node;
};
static struct listnode g_sym_list;其中name保存的是变量的名称,最长为255个字符;value是变量的值;node是方便将变量按链表方式进行保存所定义的链表节点。定义了g_sum_list全局变量,代表变量存储结构的头部节点。
因此变量数值的查找过程可以使用如下方式:
struct var_node *var_node = node_to_item(ast, struct var_node, ast_node);
struct listnode *tmp;
struct sym_node *sym_node;
/* 查找变量*/
list_for_each(tmp, &g_sym_list) {
struct sym_node *sym_node = node_to_item(tmp, struct sym_node, node);
/* 若找到变量,则返回变量的值 */
if (strcmp(sym_node->name, var_node->name) == 0) {
return sym_node->value;
}
}
/* 未找到变量,则为此变量创建一个存储空间,并将其数值初始化为0,并添加到全局链表中*/
sym_node = malloc(sizeof(struct sym_node));
strcpy(sym_node->name, var_node->name);
sym_node->value = 0;
list_add_tail(&g_sym_list, &sym_node->node);
return 0;3. 执行运算符
运算符的执行过程,实际上是一个递归调用过程,由于我们解析好的抽象语法树的叶子节点均为terminal,且已经被成功解析,而作为terminal类型的整型常量和变量的执行方式均已经实现,因此递归调用最终肯定可以退出,而不会无线递归下去。
int run_stmt(struct listnode *node) {
struct ast_node *ast = node_to_item(node, struct ast_node, node);
switch (ast->type) {
case NT_OPR:
return run_operator(node_to_item(ast, struct opr_node, ast_node));
break;
case NT_NBR:
...
break;
case NT_VAR:
...
break
default:
break;
}
return 0;
}
int run_operator(struct opr_node *opr_node) {
struct listnode *node;
int expr_num = 0;
int result = 0;
switch(opr_node->opr) {
case '>': {
struct listnode *left_node = list_head(&opr_node->expr_list);
struct listnode *right_node = left_node->next;
/* 递归调用run_stmt, 将结果使用 > 进行比较 */
return run_stmt(left_node) > run_stmt(right_node);
}
break;
...
}
return 0
}4. 整体执行
在TinyLanguage中,一个完成的程序会被归一为program,program又是以单一的funciton形式组成的(仅支持一个function),而function由一条条的stmt组成。TinyLanuage设计中,采用如下的形式组织数据结构:
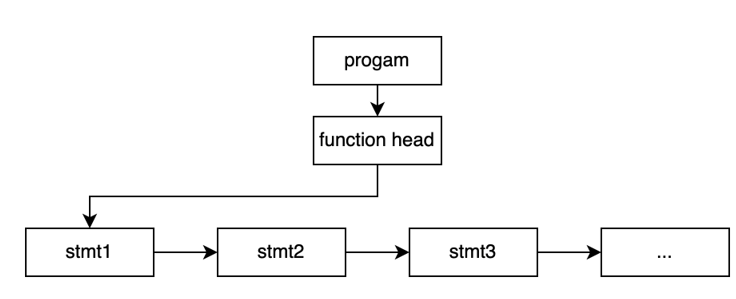
这里设置了一个全局的链表,作为头部,将stmt依次链接起来。
static struct listnode g_stmt_list;
...
function:
function stmt {
list_add_tail(&g_stmt_list, $2);
}
| /* NULL */
;
...
int run_program(const char* source) {
/* parsing source code */
set_input_string(source);
int ret = yyparse();
if (ret < 0) {
fprintf(stderr, "parse program failed");
end_lexical_scan();
return -1;
}
end_lexical_scan();
/* run program kernel */
struct listnode* node;
int result = 0;
list_for_each(node, &g_stmt_list) {
result = run_stmt(node);
}
return result;
}核心的执行代码为遍历g_stmt_list,依次执行run_stmt。
为了将TinyLanguage看起来更像一个语言,需要将TinyLanguage的执行引擎可以读取源码文件,然后进行词法解析、语法解析,因此整个过程包括:
l 打开源码文件,并读取内容
l 进行词法解析、语法解析等代码解析
l 执行语法树
int fd = open(argv[1], O_RDONLY);
if (fd < 0) {
fprintf(stderr, "open %s failed(%s)\n", argv[1], strerror(errno));
return -1;
}
int len = lseek(fd, 0, SEEK_END);
lseek(fd, 0, SEEK_SET);
char *source = malloc(len + 1);
int bytes;
if (source == NULL) {
fprintf(stderr, "malloc %d bytes faild\n", len + 1);
close(fd);
return -1;
}
source[len] = '\0';
if ((bytes = read(fd, source, len)) <= 0) {
fprintf(stderr, "read %s with %d:%d failed(%s)\n", argv[1], len, bytes, strerror(errno));
close(fd);
free(source);
return -1;
}
close(fd);
......
printf("program result:%d\n", run_program(source));
free(source);
print_sym_list(&g_sym_list);
free_program();为了让TineyLanguage可以从读取外部输入,TinyLanuage中设计了预置的全局变量,通过g_sym_list发送给TinyLanuage的源码。
/* parse input parameters */
for (int i = 2; i < argc; i++) {
struct sym_node* ptr = malloc(sizeof(struct sym_node));
sprintf(ptr->name, "R%d", i - 2);
ptr->value = atoi(argv[i]);
list_add_tail(&g_sym_list, &ptr->node);
}有了上述代码后,TinyLanguage中就可以按照如下方式来执行代码和获取外部输入了。
./tiny_lang TINY_LANGUAGE_SOURCE_CODE.T INPUT_VALUE其中"./tiny_lang"为TinyLanguage的引擎,也就是本文中最终生成的TinyLanguage的解释器;
TINY_LANGUAGE_SOURCE_CODE.T为TinyLanuage的源代码文件;第3个参数INPUT_VALUE为输入给TINY_LANGUAGE_SOURCE_CODE.T的输入变量。
a = R0 +2;TINY_LANGUAGE_SOURCE_CODE.T中就可以用类似上述方式来获取外部输入的变量了。
为了便于TinyLanguage代码的调试,我们还需要添加一个调试接口,作为输出:
# tiny_lang.l
"print" {
DEBUG("print keyword\n");
return PRINT;
}
# tiny_lang.y
stmt:
PRINT '(' expr ')' ';' { $$ = parse_operator(PRINT, 1, $3); }
...
int run_operator(struct opr_node *opr_node) {
struct listnode *node;
int expr_num = 0;
int result = 0;
switch(opr_node->opr) {
case PRINT: {
printf("=====PRINT:%d=====\n", run_stmt(list_head(&opr_node->expr_list)));
}
break;
}
}七、实现斐波那契数列
有了前期的铺垫,那么实现斐波那契数列就变得很直接了:
if (R0 <= 0) print(0);
if (R0 >= 1) print(1);
if (R0 >= 2) print(1);
n = R0;
t1 = 0;
t2 = 1;
nextTerm = t1 + t2;
for (i = 3; i <= n; i = i+1) {
t1 = t2;
t2 = nextTerm;
nextTerm = t1 + t2;
print(nextTerm);
}将上述内容保存为fibonacci.t,R0作为其输入的参数。当输入小于等于2的时候,均输出1。当数值大于2时,则会执行循环,依次将前面两个的数据进行累加。
可以使用下述命令对其进行执行,比如计算10以内的fibonacci数列:
./tiny_lang fibonacci.t 10
=====PRINT:1=====
=====PRINT:1=====
=====PRINT:2=====
=====PRINT:3=====
=====PRINT:5=====
=====PRINT:8=====
=====PRINT:13=====
=====PRINT:21=====
=====PRINT:34=====
=====PRINT:55=====
program result:0八、后记
本文通过flex和bison实现了一个简单的语言,它虽然还是相当简单的,但是有了常见语言的特性。
1. 变量、常量
2. if/else语句支持
3. for循环支持
4. 表达式的优先级
5. 外部输入、外部输出
语言一般包括解释型语言和编译型语言,当前TinyLanguage还输入解释型语言。解释性语言的执行效率比编译型语言的执行效率要低,那么有没有可能把TinyLanguage改造成编译型语言呢?答案是可以的,借助于LLVM的工具链,我们还是可以比较容易的将之改造为编译型语言,让TinyLanuage的源码可以编译为binary文件,直接运行在目标机器上。这部分内容不输入本文的讲述内容,有兴趣的读者可以参考https://llvm.org/docs/tutorial/MyFirstLanguageFrontend/进行尝试。
受限于本文的篇幅限制,无法进行过于详尽的描述。本文中使用的代码以开源形式放置在github中,便于大家参考、练习和修正,请关注本文评论区。
参考链接:
1. https://www.gnu.org/software/bison/manual/bison.html
2. https://llvm.org/docs/tutorial/MyFirstLanguageFrontend/
3. https://westes.github.io/flex/manual/
4. https://www.zhihu.com/question/21833944
5. https://en.wikipedia.org/wiki/Backus%E2%80%93Naur_form

长按关注内核工匠微信
Linux 内核黑科技 | 技术文章 | 精选教程