Elasticsearch 向量搜索应用介绍
本文将会介绍 Elasticsearch 向量搜索的两种方式。
向量搜索
提到向量搜索,我想你一定想知道:
-
向量搜索是什么?
-
向量搜索的应用场景有哪些?
-
向量搜索与全文搜索有何不同?
ES 的全文搜索简而言之就是将文本进行分词,然后基于词通过 BM25 算法计算相关性得分,从而找到与搜索语句相似的文本,其本质上是一种 term-based(基于词)的搜索。
全文搜索的实际使用已经非常广泛,核心技术也非常成熟。但是,除了文本内容之外,现实生活中还有非常多其它的数据形式,例如:图片、音频、视频等等,我们能不能也对这些数据进行搜索呢?
答案是 Yes !
随着机器学习和人工智能等技术的发展,万物皆可 Embedding。换句话说就是,我们可以对文本、图片、音频、视频等等一切数据通过 Embedding 相关技术将其转换成特征向量,而一旦向量有了,向量搜索的需求随之也越发强烈,向量搜索的应用场景也变得一望无际、充满想象力。
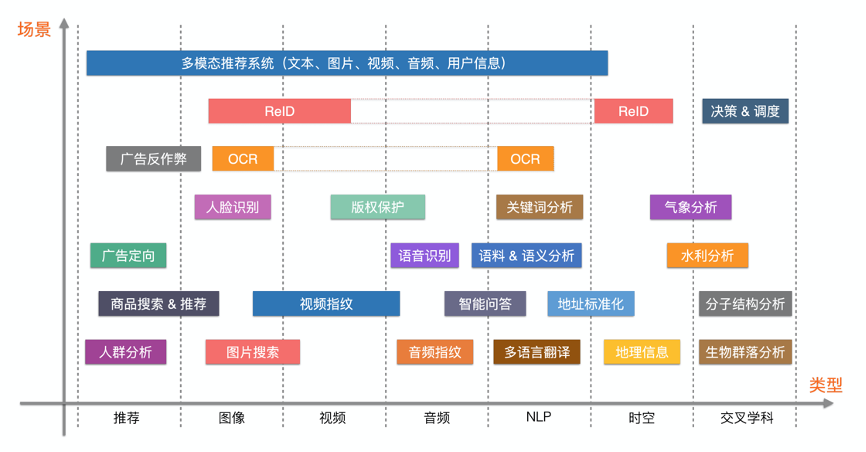
图片来源 damo.alibaba.com/events/112
ES 向量搜索说明
ES 向量搜索目前有两种方式:
-
script_score -
_knn_search
script_score 精确搜索
ES 7.6 版本对新增的字段类型 dense_vector 确认了稳定性保证,这个字段类型就是用来表示向量数据的。
数据建模示例:
PUT my-index
{
"mappings": {
"properties": {
"my_vector": {
"type": "dense_vector",
"dims": 128
},
"my_text" : {
"type" : "keyword"
}
}
}
}
如上图所示,我们在索引中建立了一个 dims 维度为 128 的向量数据字段。
script_score 搜索示例:
{
"script_score": {
"query": {"match_all": {}},
"script": {
"source": "cosineSimilarity(params.query_vector, 'my_vector') + 1.0",
"params": {"query_vector": query_vector}
}
}
}
上图所示的含义是使用 ES 7.3 版本之后内置的 cosineSimilarity 余弦相似度函数计算向量之间的相似度得分。
需要注意的是,script_score 这种搜索方式是先执行 query ,然后对匹配的文档再进行向量相似度算分,其隐含的含义是:
-
数据建模时向量字段可以与其它字段类型一起使用,也就是支持混合查询(先进行全文搜索,再基于搜索结果进行向量搜索)。
-
script_score是一种暴力计算,数据集越大,性能损耗就越大。
_knn_search 搜索
由于 script_score 的性能问题,ES 在 8.0 版本引入了一种新的向量搜索方法 _knn_search(目前处于试验性功能)。
所谓的 _knn_search 其实就是一种 approximate nearest neighbor search (ANN) 即 近似最近邻搜索。这种搜索方式在牺牲一定准确性的情况下优先追求搜索性能。
为了使用 _knn_search 搜索,在数据建模时有所不同。
示例:
PUT my-index-knn
{
"mappings": {
"properties": {
"my_vector": {
"type": "dense_vector",
"dims": 128,
"index": true,
"similarity": "dot_product"
}
}
}
}
如上所示,我们必须额外指定:
-
index为 true 。 -
similarity指定向量相似度算法,可以是l2_norm、dot_product、cosine其中之一。
额外指定 index 为 true 是因为,为了实现 _knn_search,ES 必须在底层构建一个新的数据结构(目前使用的是 HNSW graph )。
_knn_search 搜索示例:
GET my-index-knn/_knn_search
{
"knn": {
"field": "my_vector",
"query_vector": [0.3, 0.1, 1.2, ...],
"k": 10,
"num_candidates": 100
},
"_source": ["name", "date"]
}
使用 _knn_search 搜索的优点就是搜索速度非常快,缺点就是精确度不是百分百,同时无法与 Query DSL 一起使用,即无法进行混合搜索。