torch.nn.CrossEntropyLoss()用法
CLASS torch.nn.CrossEntropyLoss(weight: Optional[torch.Tensor] = None, size_average=None, ignore_index: int = -100, reduce=None, reduction: str = 'mean')这个评价损失将 nn.LogSoftmax() 和 nn.NLLLoss() 结合在一个类中。
在训练带有C类的分类问题时很有用(这里指的是多类别单分类问题)。 如果提供,则可选参数weight应为一维张量,为每个类分配权重。 当您的训练集不平衡时,这特别有用。
input预期将包含每个类的原始未标准化分数。(即网络的输出概率值)
input 必须为张量,其大小为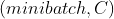 (通常指的是单类别预测)或
(通常指的是单类别预测)或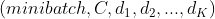 (通常指的是多维单类别预测,即图像像素级单类别预测),K≥1对于K维情况(后述)。
(通常指的是多维单类别预测,即图像像素级单类别预测),K≥1对于K维情况(后述)。
该评价损失期望类别索引范围为![[0, C-1]](https://images2.imgbox.com/3e/3f/9IOqmzmL_o.gif) ,作为大小为minibatch的一维张量target的每个值(指的是target中的每个值都是0-C-1的整数值)。 如果指定了ignore_index,则此评价损失也接受该类索引(此索引可能不一定在类范围内)。
,作为大小为minibatch的一维张量target的每个值(指的是target中的每个值都是0-C-1的整数值)。 如果指定了ignore_index,则此评价损失也接受该类索引(此索引可能不一定在类范围内)。
损失可以描述为:
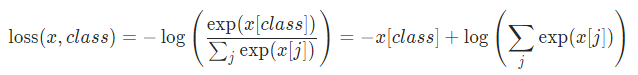
或在指定weight参数的情况下:
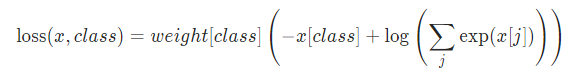
损失是对每个minibatch的观察结果的平均值。 如果指定了weight参数,则这是一个加权平均值:
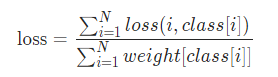
还可用于更高维度的输入,例如2D图像,提供一个大小为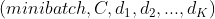 ,K≥1的input,其中K是维度数,target具有适当形状(请参见下文)。
,K≥1的input,其中K是维度数,target具有适当形状(请参见下文)。
Parameters
-
weight (Tensor, 可选) – 给定每个类手动调整缩放权重。 如果给定,则必须是大小为C维的张量. a manual rescaling weight given to each class. If given, has to be a Tensor of size C
-
size_average (bool, 可选) – 弃用(见
reduction). 默认情况下,损失是batch中每个损失元素的平均值。 请注意,对于某些损失,每个样本有多个元素。如果将size_average字段设置为False,则损失不是每个minibatch的总和。 当reduce为False时被忽略。默认值:True.By default, the losses are averaged over each loss element in the batch. Note that for some losses, there are multiple elements per sample. If the fieldsize_averageis set toFalse, the losses are instead summed for each minibatch. Ignored when reduce isFalse. Default:True -
ignore_index (int, 可选) – 指定一个目标值,该目标值将被忽略并且不会影响输入梯度。当
size_average为True时,损失是对non-ignored目标的平均值。Specifies a target value that is ignored and does not contribute to the input gradient. Whensize_averageisTrue, the loss is averaged over non-ignored targets. -
reduce (bool, 可选) – 弃用(见
reduction). By default, the losses are averaged or summed over observations for each minibatch depending onsize_average. WhenreduceisFalse, returns a loss per batch element instead and ignoressize_average. Default:True。默认情况下,损失是根据size_average对每个minibatch的观察结果求平均或求和。当reduce为False时,返回每个batch 的元素损失,并忽略size_average。 默认值:True。 -
reduction (string, 可选) – Specifies the reduction to apply to the output:
'none'|'mean'|'sum'.'none': no reduction will be applied,'mean': the weighted mean of the output is taken,'sum': the output will be summed. Note:size_averageandreduceare in the process of being deprecated, and in the meantime, specifying either of those two args will overridereduction. Default:'mean'。指定要应用于输出的缩减量:'none'| 'mean' | 'sum'。'none':不应用reduction,'mean':采用输出的加权平均值,'sum': 对输出求和。注意:size_average和reduce正在弃用过程中,与此同时,指定这两个args中的任何一个将覆盖reduction。 默认值:'mean'。
Shape:
-
Input: (N, C) where C = number of classes, or
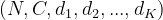 with K≥1 in the case of K-dimensional loss.
with K≥1 in the case of K-dimensional loss. -
Target: (N) where each value is
![0 \leq \text{targets}[i] \leq C-1](https://images2.imgbox.com/a1/e4/ra5kFFmA_o.gif) , or
, or 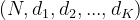 with K≥1 in the case of K-dimensional loss.
with K≥1 in the case of K-dimensional loss. -
Output: scalar. If
reductionis'none', then the same size as the target: (N) , or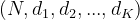 with K≥1 in the case of K-dimensional loss.
with K≥1 in the case of K-dimensional loss.