es搜索引擎
ES的优势及使用场景、ES的功能及使用简介
简介:
Elaticsearch简称为ES,是一个开源的可扩展的分布式的全文检索引擎,它可以近乎实时的存储、检索数 据。本身扩展性很好,可扩展到上百台服务器,处理PB级别的数据。ES使用Java开发并使用Lucene作 为其核心来实现索引和搜索的功能,但是它通过简单的RestfulAPI和javaAPI来隐藏Lucene的复杂性, 从而让全文搜索变得简单。
优势
分布式的搜索引擎
1、分布式:Elasticsearch自动将海量数据分散到多台服务器上去存储和检索 搜索:百度、谷歌,站内搜索 2、全文检索 提供模糊搜索等自动度很高的查询方式,并进行相关性排名,高亮等功能 3、数据分析引擎(分组聚合) 电商网站,最近一周笔记本电脑这种商品销量排名top10的商家有哪些?新闻网站,最近1个月访 问量排名top3的新闻板块是哪些 4、对海量数据进行近实时的处理 海量数据的处理:因为是分布式架构,Elasticsearch可以采用大量的服务器去存储和检索数据,自 然而然就可以实现海量数据的处理 近实时:Elasticsearch可以实现秒级别的数据搜索和分析。
场景
1.常见场景
-
搜索类场景 比如说电商网站、招聘网站、新闻资讯类网站、各种app内的搜索。
-
日志分析类场景 经典的ELK组合(Elasticsearch/Logstash/Kibana),可以完成日志收集,日志存储,日志分析查 询界面基本功能,目前该方案的实现很普及,大部分企业日志分析系统使用了该方案。
-
数据预警平台及数据分析场景 例如电商价格预警,在支持的电商平台设置价格预警,当优惠的价格低于某个值时,触发通知消 息,通知用户购买。 数据分析常见的比如分析电商平台销售量top 10的品牌,分析博客系统、头条网站top 10关注度、 评论数、访问量的内容等等。
-
商业BI(Business Intelligence)系统 比如大型零售超市,需要分析上一季度用户消费金额,年龄段,每天各时间段到店人数分布等信 息,输出相应的报表数据,并预测下一季度的热卖商品,根据年龄段定向推荐适宜产品。 Elasticsearch执行数据分析和挖掘,Kibana做数据可视化。
2.常见案例 维基百科、百度百科:有全文检索、高亮、搜索推荐功能 stack overflow:有全文检索,可以根据报错关键信息,去搜索解决方法。 github:从上千亿行代码中搜索你想要的关键代码和项目。 日志分析系统:各企业内部搭建的ELK平台。
ES的可靠性设计:
数据可靠性:
-
引入translog 当一个文档写入Lucence后是存储在内存中的,即使执行了refresh操作仍然是在文件系统缓存中,如果此时服务器宕机,那么这部分数据将会丢失。为此ES增加了translog, 当进行文档写操作时会先将文档写入Lucene,然后写入一份到translog,写入translog是落盘的(如果对可靠性要求不是很高,也可以设置异步落盘,可以提高性能,由配置
index.translog.durability和index.translog.sync_interval控制),这样就可以防止服务器宕机后数据的丢失。由于translog是追加写入,因此性能比较好。与传统的分布式系统不同,这里是先写入Lucene再写入translog,原因是写入Lucene可能会失败,为了减少写入失败回滚的复杂度,因此先写入Lucene. -
flush操作 另外每30分钟或当translog达到一定大小(由
index.translog.flush_threshold_size控制,默认512mb), ES会触发一次flush操作,此时ES会先执行refresh操作将buffer中的数据生成segment,然后调用lucene的commit方法将所有内存中的segment fsync到磁盘。此时lucene中的数据就完成了持久化,会清空translog中的数据(6.x版本为了实现sequenceIDs,不删除translog)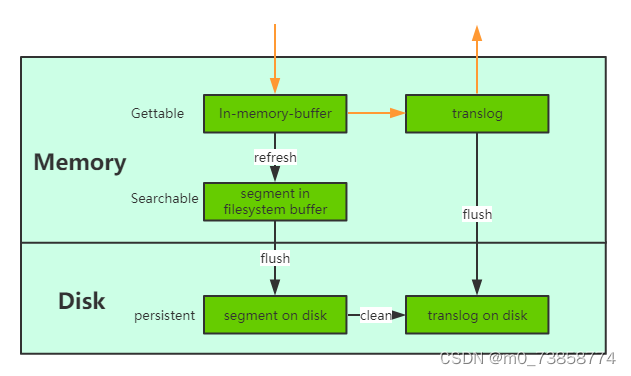
-
merge操作 由于refresh默认间隔为1s中,因此会产生大量的小segment,为此ES会运行一个任务检测当前磁盘中的segment,对符合条件的segment进行合并操作,减少lucene中的segment个数,提高查询速度,降低负载。不仅如此,merge过程也是文档删除和更新操作后,旧的doc真正被删除的时候。用户还可以手动调用_forcemerge API来主动触发merge,以减少集群的segment个数和清理已删除或更新的文档。
-
多副本机制
另外ES有多副本机制,一个分片的主副分片不能分片在同一个节点上,进一步保证数据的可靠性。
2.4 部分更新
lucene支持对文档的整体更新,ES为了支持局部更新,在Lucene的Store索引中存储了一个source字段,该字段的key值是文档ID, 内容是文档的原文。当进行更新操作时先从source中获取原文,与更新部分合并后,再调用lucene API进行全量更新, 对于写入了ES但是还没有refresh的文档,可以从translog中获取。另外为了防止读取文档过程后执行更新前有其他线程修改了文档,ES增加了版本机制,当执行更新操作时发现当前文档的版本与预期不符,则会重新获取文档再更新。
ES的高性能设计:
1.倒排索引的设计让ElasticSearch查询更快
ES的搜索数据结构模型基于倒排索引。倒排索引是指数据存储时,进行分词建立term索引库。倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(inverted file)。
-
FST的设计让ElasticSearch用最小的内存存储Term Index
-
Frame Of Reference的设计让ElasticSearch用最小的磁盘存储Posting List
-
Roaring Bitmaps的设计让ElasticSearch用最小的磁盘存储缓存filter
-
跳表实现多个field的联合索引做倒排索引