RocketMQ - 集群管理
在分布式服务架构中,任何中间件或者应用都不允许单点存在,服务发现机制是必备的。服务实例有多个,且数量是动态变化的。注册中心会提供服务管理能力,服务调用方在注册中心获取服务提供者的信息,从而进行远程调用。接下来介绍一下RocketMQ的整体架构设计、集群管理。
整体架构设计
首先介绍一下RocketMQ和Kafka的渊源, Kafka是一款高性能的消息中间件,经常在大数据场景中被使用,但由于Kafka不支持消费失败重试、定时消息、事务消息,顺序消息也有明显缺陷,难以支撑淘宝交易、订单、充值等复杂业务场景。淘宝中间件团队参考Kafka重新设计并用Java编写了RocketMQ,因此在RocketMQ中会有一些概念和Kafka相似。
常见的消息中间件Kafak、RabbitMQ、RocketMQ等都基于发布/订阅机制,消息发送者把消息发送到消息服务器,消息消费者从消息服务器订阅感兴趣的消息。这个过程中消息发送者和消息消费者是客户端,消息服务器是服务端,客户端与服务端双方都需要通过注册中心感知彼此。
RocketMQ部署架构主要分为四部分,如下图所示
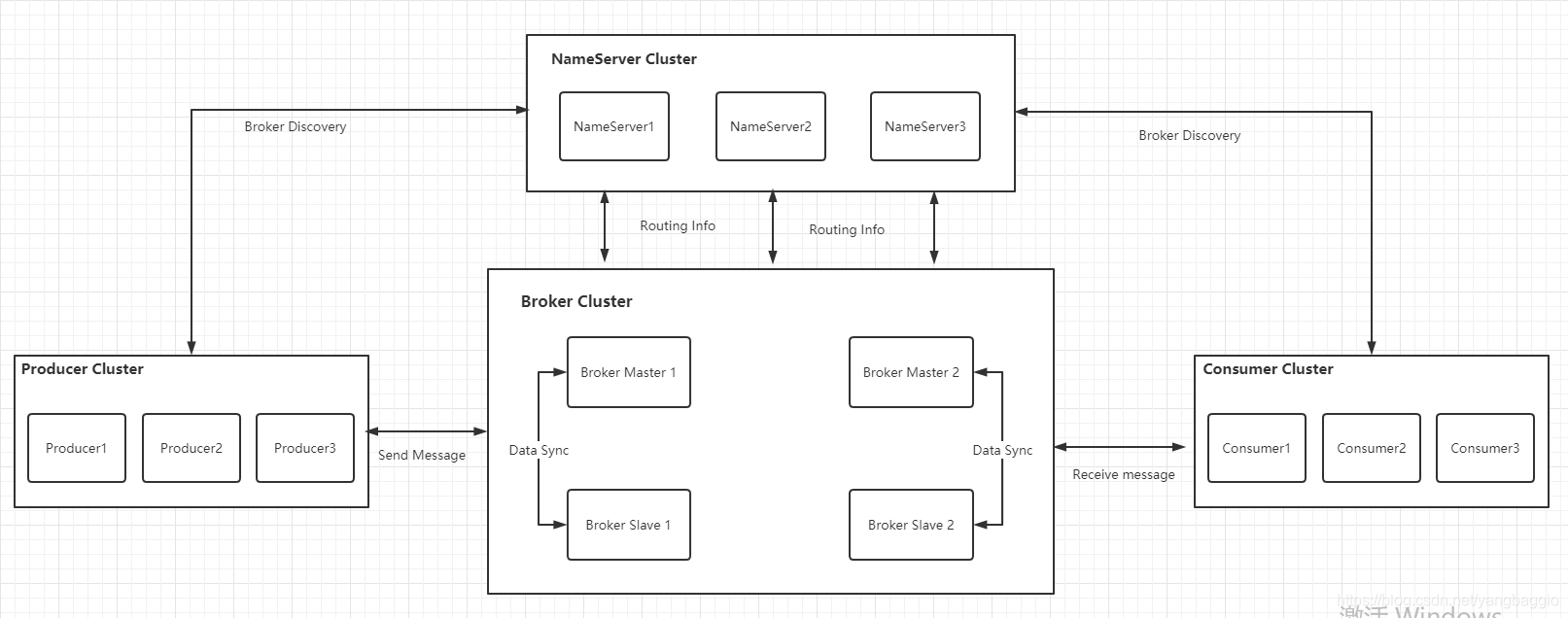
- Producer:消息发布的角色,主要负责把消息发送到Broker,支持分布式集群方式部署。
- Consumer:消息消费者的角色,主要负责从Broker订阅消息消费,支持分布式集群方式部署。
- Broker:消息存储的角色,主要负责消息的存储、投递和查询,以及服务高可用保证,支持分布式集群方式部署。
- NameServer:服务管理的角色,主要负责管理Broker集群的路由信息,支持分布式集群方式部署。
NameServer是一个非常简单的Topic路由注册中心,其角色类似于Dubbo中依赖的ZooKeeper,支持Broker的动态注册与发现。主要包含以下两个功能:
- 服务注册:NameServer接收Broker集群的注册信息,保存下来作为路由信息的基本数据,并提供心跳检测机制,检查Broker是否还存活。
- 路由信息管理:NameServer保存了Broker集群的路由信息,用于提供给客户端查询Broker的队列信息。Producer和Consumer通过NameServer可以知道Broker集群的路由信息,从而进行消息的投递和消费。
基本概念
- Message:消息,系统所传输信息的物理载体,生产和消费数据的最小单位,每条消息必须属于一个Topic,RocketMQ中每条消息拥有一个唯一的MessageID,并且可以携带具有业务表示的Key。
- Topic:主题,表示一类消息的集合,每个主题都包含若干条消息,每条消息都只能属于一个主题,Topic是RocketMQ进行消息订阅的基本单位。
- Queue:消息队列,组成Topic的最小单元,默认情况下一个Topic会对应多个Queue,Topic是逻辑概念,Queue是物理存储,在Consumer消费Topic消息时,底层实际则拉取Queue的消息。
- Tag:为消息设置的标志,用于同一主题下区分不同类型的消息。来自同一业务单元的消息,可以根据不同业务目的在同一主题下设置不同标签。标签能够有效地保持代码的清晰度和连贯性,并优化RocketMQ提供的查询系统。消费者可以根据Tag实现对不同子主题的不同消费的处理逻辑,实现更好的扩展性。
- UserProperties:用户自定义属性集合,属于Message的一部分。
- ProducerGroup:同一类Producer集合,这类Producer发送同一类消息且发送逻辑一致。如果发送的是事务消息且原始生产者在发送之后崩溃,则Broker服务器会联系同一生产者组的其它生产者实例提交或者回溯消费。
- ConsumerGroup:同一类Consumer的集合,这类Consumer通常消费同一类消息且消费逻辑一致。消费者组使得在消息消费方面,实现负载均衡和容错的目标变得非常容易。消费者组的消费者实例必须订阅完全相同的Topic。
为什么使用NameServer
在Kafka中的服务注册与发现通常是用ZooKeeper来完成的,RocketMQ早期也使用了ZooKeeper做集群管理,但后来放弃了转而使用自己开发的NameServer。
在Kafka中,Topic是逻辑概念,分区是物理概念。1个Topic可以设置多个分区,每个分区可以设置多个副本,即有一个Master分区、多个Slave分区。
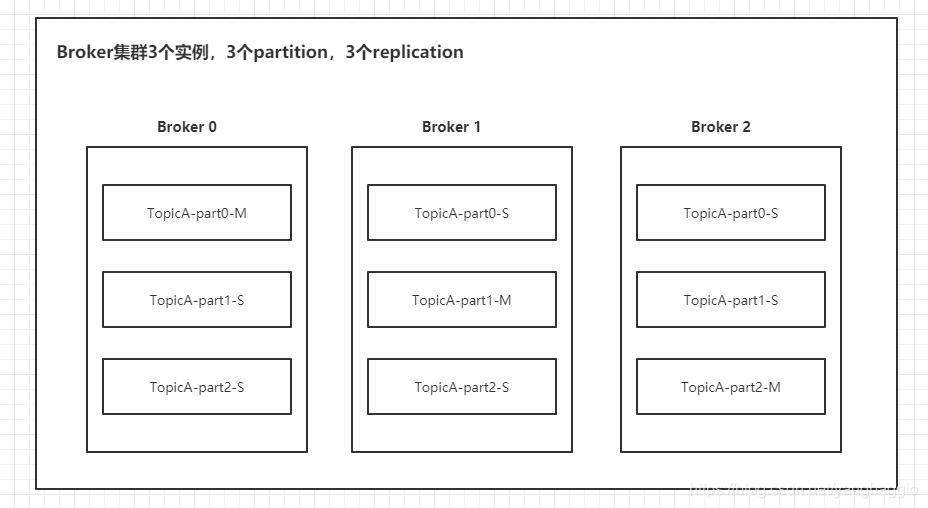
比如,搭建3个Broker构成一个集群,创建一个Topic取名为TopicA,分区是3个,副本数是2个。在上图中part表示分区,M表示Master,S表示Slave。
在Kafka中消息只能发送到Master分区中,消息发送给Topic时会发送到具体某个分区。如果发送给part0就只会发送到Broker0这个实例中,再由Broker0同步到Broker1和Broker2中的part0的副本中;如果发送给part1的消息,就只会发送到Broker1这个实例中,再由Broker1同步到Broker0和Broker2中的part1的副本中。
在RocketMQ中,Topic也是逻辑概念,队列(Queue)是物理概念(对应Kafka中的分区)。1个Topic可以设置多个队列,每个队列也可以有多个副本,即有一个Master队列、多个Slave队列。
RocketMQ的部署拓扑图如下:
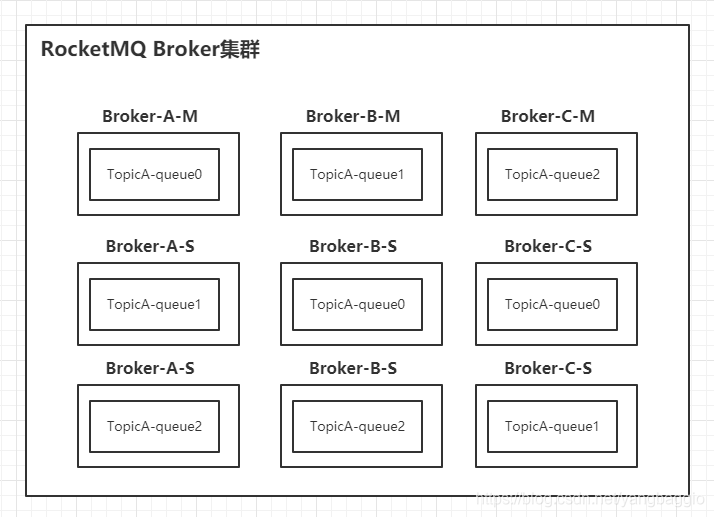
为了方便对比,同样创建一个Topic取名为TopicA,队列是3个,副本数也是2个,但构成Broker集群的实例有9个。
Kafka与RocketMQ两者在概念上相似,但又有明显的差异
- 在Kafka中,Master和Slave在同一台Broker机器上,Broker机器上有多个分区,每个分区的Master/Slave身份是在运行过程中选举出来的。Broker机器具有双重身份,既有Master分区,也有Slave分区。
- 在RocketMQ中,Master和Slave不在同一台Broker机器上,每台Broker机器不是Master就是Slave,Broker的Master/Slave身份是在Broker的配置文件中预先定义好的,在Broker启动之前就已经决定了。
这个差异的影响在哪里呢?Kafka的Master/Slave需要通过ZooKeeper选举出来,而RocketMQ不需要。问题就在这个选举上,ZooKeeper具备选举功能,选举机制的原理就是少数服从多数,那么ZooKeeper的选举机制必须由ZooKeeper集群中的多个实例共同完成。ZooKeeper集群中的多个实例必须相互通信,如果实例数很多,网络通信就会变得非常复杂且低效。
NameServer的设计目标是让网络通信变的简单,从而使性能得到极大的提升。为了避免单点故障,NameServer也必须以集群的方式部署,但集群中各个实例之间相互不进行网络通信。NameServer是无状态的,可以任意部署多个实例。Broker向每一台NameServer注册自己的路由信息,因此每一个NameServer实例都保存一份完整的路由信息。NameServer与每台Broker机器保持长连接,每隔30s从路由注册表中将故障机器移除。NameServer为了降低实现的复杂度,并不会立即通知客户端的Producer和Consumer。
集群环境下实例很多,偶尔会出现各种各样的问题,以下几种场景需要思考:
- 当某个NameServer因宕机或者网络问题下线了,Broker如何同步路由信息?
由于Broker会连接NameServer集群的每一个实例,Broker仍然可以向其它NameServer同步路由信息,Producer和Consumer仍然可以动态感知Broker的路由信息。 - NameServer如果检测到Broker宕机,并没有立即通知Producer和Consumer,Producer将消息发送到故障的Broker怎么办?Consumer从Broker订阅消息失败怎么办?
RocketMQ为了简化NameServer的设计,这两个问题都是在客户端解决的,可以参考RocketMQ高可用相关的文章。 - 由于NameServer集群中的实例相互不通信,在某个时间点不同NameServer实例保存的路由信息可能不一致。
这对发送消息和消费消息并不会有什么影响,原理和上一个问题是一样的,从这里可以看出NameServer是CAP种的AP架构。
彩蛋
点击下方链接,可以免费获取大量电子书资源
免费领取资源