python中pandas包使用的一个header参数
也许有人会不明白panda在读取excel时的语句里边的header参数
如下:
a = pd.read_excel("建模题目一.xlsx", header=None)那么header=None是什么意思呢?--->字面上就是没有表头。
没有表头会怎么办呢?---->你表里边的第一行就会被pandas解析为表头
下边给出演示:
我的原始Excel表:
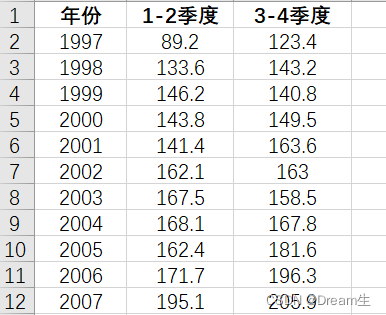
处理代码:
a = pd.read_excel("建模题目一.xlsx", header=None)
返回结果:
0 年份 1-2季度 3-4季度
1 1997 89.2 123.4
2 1998 133.6 143.2
3 1999 146.2 140.8
4 2000 143.8 149.5结果分析:
pandas把我们的第一行解析为了表头。
header拓展用法:
指定从第几行为表头。比如我要把第三行作为表头【前两行的数据就不会读取了】,那么我的 header = 2,对应的代码为:
a = pd.read_excel("建模题目一.xlsx", header=2)运行结果:
1998.0 133.6 143.2
0 1999 146.2 140.8
1 2000 143.8 149.5
2 2001 141.4 163.6
3 2002 162.1 163.0
4 2003 167.5 158.51998恰好对应原始Excel表的第三行