聊聊java8中的@sun.misc.Contended与伪共享
“持续创作,加速成长!这是我参与「掘金日新计划 · 6 月更文挑战」的第30天,点击查看活动详情”
@[toc] 在前面学习ConcurrentHashMap的size方法的过程中,对于CounterCell这个类,有个特殊的注解 @sun.misc.Contended。那么今天就来聊聊这个注解的具体作用和其底层的基本原理。
<pre class="prettyprint hljs cs">/**
* A padded cell for distributing counts. Adapted from LongAdder
* and Striped64\. See their internal docs for explanation.
*/
@sun.misc.Contended static final class CounterCell {
volatile long value;
CounterCell(long x) { value = x; }
}</pre>
经过查阅资料之后,不难发现,@sun.misc.Contended注解是被设计用来解决伪共享问题的。那么什么是为伪共享呢?
1.伪共享
在了解伪共享之前,需要了解一下CPU的缓存机制。
1.1 CPU的缓存机制
学过计算机的人都知道,CPU是计算机的大脑,所有的程序,最终都要变成CPU指令在CPU中去执行。CPU的计算速度是非常快的,但是,我们知道,程序必须存储在存储介质中,程序启动之后被加载到内存中才能执行。但是内存的读取速度和CPU的计算速度之间存在非常大的差异。那么为了解决这个计算速度之间的差异,就在CPU上增加了缓存来解决这个问题。通常情况下,CPU是三级缓存结构,如下图:
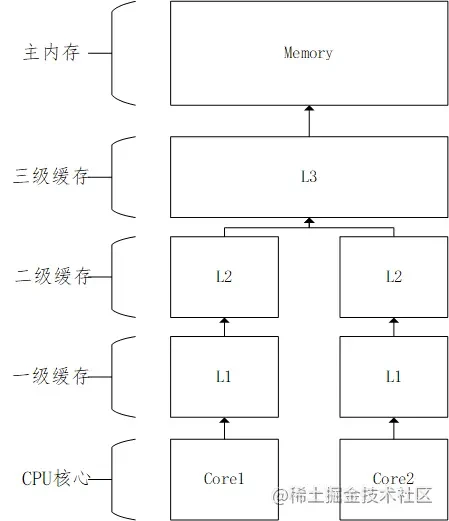
越靠近CPU的缓存,其容量就越小,但是其速度就越快。所以实际上L1的容量是最小的,这取决于CPU的具型号。
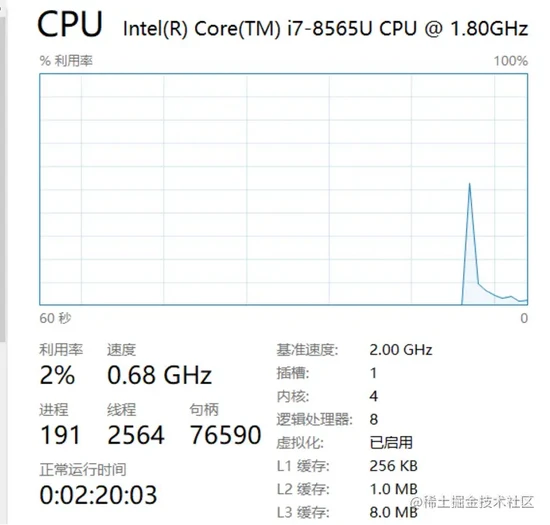
如上图所示,我们笔记本使用的I7CPU的三级缓存,L1为256k,L2为1M,L3为8M。 当CPU在执行计算的时候,先去L1查找数据,然后再去L2、L3,如果都没有数据则需要到主存中去加载。走得越远运算耗费的时间就越长。所以,对于一些高CPU的计算,尽量确保数据都能在L1中,降低加载次数。 Martin Thompson 提供了一些从CPU到缓存加载需要的大值时间:
| 从CPU | CPU周期 | 大致时间 |
|---|---|---|
| 主存 | 60-80ns | |
| QPI总线 | 20ns | |
| L3 cache | 40-45cycles | 15ns |
| L2 cache | 10 cycles | 3ns |
| L1 cache | 3-4cycle | 1ns |
| 寄存器 | 1cycle |
1.2 缓存行和伪共享
我们了解了缓存cache之后,缓存是以行为单位存在在cache中的,通常而言,一个缓存行大概是64byte。对于java类而言,一个javalong的对象长度为8字节,因此一个缓存行就是8个long的长度。因此,在你访问一个long数组的时候,当数组中有一个值被加载到缓存中的时候,它会额外加载另外7个值,以至于遍历数组的速度可以非常快。因此对于连续存储在内存块的数据结构,都是可以非常快速的遍历的。 对于链表,由于数据不连续,因此很难享受到这个优势。也就是说,CPU处理内存的宽度是64byte。但是我们程序中的基本的变量都会小于这个宽度,因此这会带来另外一个问题,这就是伪共享。 伪共享的意思就是说,当线程1在使用变量x的时候,CPU会将X相连的部分共64字节全部都加载到core的L1中。如果此时线程2需要使用的y,但是y在此时已经做为x相邻的64字节的一部分被加载到了L1中。由于L1是按核心各自独立的,因此这个时候就会对这个缓存行产生了竞争。这就是伪共享。 实际上CPU的处理可能比这个描述复杂,但是对于这种竞争的情况,一般在MESI协议的CPU上,是会互相影响的。 在MESI协议中,如果两个不同的处理器都需要操作相同的缓存行,那么就会导致RFO请求。 我们来看看Disruptor的示例图:
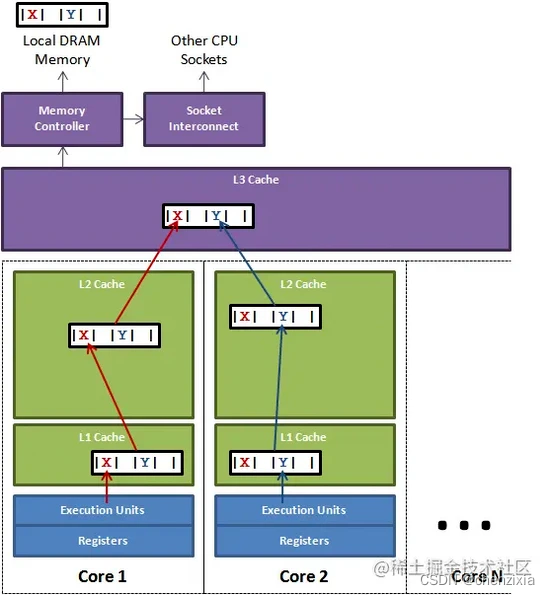
在上图中,当core1上的线程想要修改变量x的值的时候,同时另外一个线程需要修改y的值。但是这两个操作的变量都处于同一缓存行,这样就会导致其中一个线程在操作的过程中,缓存行的数据由于被其他的线程修改,而不得不重新从L3中去加载。在前文中我们了解到,l3的速度会比较慢,这样就产生了性能的差异。 这就是我们说的伪共享。 那么怎么解决这个问题呢,最好的办法就是不让一个行中存在的数据产生竞争。那么最好的办法就是插入几个无效的变量将这两个高频计算的变量分开,使之不能加载到同一行中。 在java7中我们只能通过内存填充来解决这个问题,但是在java8中,提供了@sun.misc.Contended注解,替换了内存填充的工作。这就是@sun.misc.Contended注解的作用。
2.代码验证
我们定义两个变量,分别在两个线程中各自增加到10亿次,看看再各种情况下的计算结果:
2.1 不做任何处理
<pre class="prettyprint hljs java">package com.dhb.map.test;
public class FalseSharingTest {
public static void main(String[] args) throws InterruptedException {
testPointer(new Pointer());
}
private static void testPointer(Pointer pointer) throws InterruptedException{
long start = System.currentTimeMillis();
Thread t1 = new Thread(() -> {
for(int i=0;i<1000000000;i++){
pointer.x++;
}
});
Thread t2 = new Thread(() -> {
for(int i=0;i<1000000000;i++){
pointer.y++;
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("cost ["+(System.currentTimeMillis()-start)+"] ms");
System.out.println(pointer);
}
static class Pointer{
volatile long x;
volatile long y;
@Override
public String toString() {
return "Pointer{" +
"x=" + x +
", y=" + y +
'}';
}
}
}</pre>
上述代码执行之后:
<pre class="hljs xquery">cost [35885] ms
Pointer{x=1000000000, y=1000000000}</pre>
可以看到共计花费35多。
2.2 缓存填充
我们采用填充的方式,如下:
<pre class="prettyprint hljs java">package com.dhb.map.test;
public class FalseSharingTest {
public static void main(String[] args) throws InterruptedException {
testPointer(new Pointer());
}
private static void testPointer(Pointer pointer) throws InterruptedException{
long start = System.currentTimeMillis();
Thread t1 = new Thread(() -> {
for(int i=0;i<1000000000;i++){
pointer.x++;
}
});
Thread t2 = new Thread(() -> {
for(int i=0;i<1000000000;i++){
pointer.y++;
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("cost ["+(System.currentTimeMillis()-start)+"] ms");
System.out.println(pointer);
}
static class Pointer{
volatile long x;
long p1, p2, p3, p4, p5, p6, p7;
volatile long y;
@Override
public String toString() {
return "Pointer{" +
"x=" + x +
", y=" + y +
'}';
}
}
}</pre>
实际上只是增加了7个long变量,计算结果如下:
<pre class="hljs xquery">cost [5218] ms
Pointer{x=1000000000, y=1000000000}</pre>
可以看到,性能有了大幅提升,只需要5秒就能完成,比上个版本的代码快了6倍多。
2.3 通过Contended
<pre class="prettyprint hljs java">package com.dhb.map.test;
public class FalseSharingTest {
//-XX:-RestrictContended
public static void main(String[] args) throws InterruptedException {
testPointer(new Pointer());
}
private static void testPointer(Pointer pointer) throws InterruptedException{
long start = System.currentTimeMillis();
Thread t1 = new Thread(() -> {
for(int i=0;i<1000000000;i++){
pointer.x++;
}
});
Thread t2 = new Thread(() -> {
for(int i=0;i<1000000000;i++){
pointer.y++;
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("cost ["+(System.currentTimeMillis()-start)+"] ms");
System.out.println(pointer);
}
static class Pointer{
@sun.misc.Contended
volatile long x;
@sun.misc.Contended
volatile long y;
@Override
public String toString() {
return "Pointer{" +
"x=" + x +
", y=" + y +
'}';
}
}
}</pre>
我们可以看到,再运行的时候设置了-XX:-RestrictContended之后,通过注解的方式可以生效。Contended注解必须修改jvm运行参数-XX:-RestrictContended,否则会被jvm忽略。

执行结果如下:
<pre class="hljs xquery">cost [5230] ms
Pointer{x=1000000000, y=1000000000}</pre>
我们可以看到花费的时间几乎与缓存填充差不多。比伪共享有显著的提升。
3.总结
通过本文,了解了什么是缓存的伪共享。以及@sun.misc.Contended注解的作用和使用方法。 这也是ConcurrentHashMap中为了性能提升所采取的一个优化措施。自然,这个注解会因为添加了一些无用的变量而带来了内存的浪费。