【数据结构和算法】独一无二的出现次数
其他系列文章导航
文章目录
前言
这是力扣的 1207 题,难度为简单,解题方案有很多种,本文讲解我认为最奇妙的一种。
一、题目描述
给你一个整数数组 arr,请你帮忙统计数组中每个数的出现次数。
如果每个数的出现次数都是独一无二的,就返回 true;否则返回 false。
示例 1:
输入:arr = [1,2,2,1,1,3] 输出:true 解释:在该数组中,1 出现了 3 次,2 出现了 2 次,3 只出现了 1 次。没有两个数的出现次数相同。
示例 2:
输入:arr = [1,2] 输出:false
示例 3:
输入:arr = [-3,0,1,-3,1,1,1,-3,10,0] 输出:true
提示:
1 <= arr.length <= 1000-1000 <= arr[i] <= 1000
二、题解
2.1 哈希类算法题注意事项
解决哈希类的算法题需要注意以下几点:
- 理解哈希表的基本原理:哈希表是一种数据结构,它使用哈希函数将键映射到数组中的位置。理解哈希表如何工作是解决这类问题的关键。
- 选择合适的哈希函数:一个好的哈希函数能够将键均匀地分布到哈希表中,以减少冲突。你需要选择或设计一个能够满足题目要求的哈希函数。
- 处理冲突:即使有好的哈希函数,也可能会有冲突(即两个不同的键映射到同一个位置)。你需要决定如何处理这些冲突,例如使用链表、开放地址法等。
- 考虑哈希表的负载因子:负载因子是哈希表中元素的数量与哈希表大小的比值。当负载因子过高时,哈希表的性能会下降。因此,你可能需要动态调整哈希表的大小以保持合适的负载因子。
- 优化空间和时间效率:在解决这类问题时,你需要权衡空间和时间效率。一个空间效率高的解决方案可能不那么高效,反之亦然。你需要找到一个合适的平衡点。
- 测试和验证:在提交解决方案之前,一定要进行彻底的测试和验证。确保你的解决方案在各种情况下都能正常工作。
- 阅读和理解题目要求:仔细阅读题目,确保你完全理解了题目的要求。如果有任何疑问,应该向老师或教练询问,以确保没有误解。
- 使用适当的数据结构:在许多情况下,使用哈希表并不是唯一的解决方案。其他数据结构(如数组、树或图)可能更适合解决特定的问题。选择最适合的数据结构可以提高解决问题的效率。
- 注意算法的复杂度:了解算法的时间复杂度和空间复杂度对于选择合适的算法非常重要。对于大规模数据,应选择复杂度较低的算法以提高效率。
- 多做练习:解决哈希类的算法题需要大量的练习和经验积累。通过参与在线编程挑战、参加算法竞赛等方式,可以提高解决这类问题的能力。
2.2 方法一:判断长度
思路与算法:
先计算每个数出现的次数。最后只需要判断这个出现次数的数组中元素是否有重复的即可。
我们知道集合 set 是不能有重复元素的,如果有就会替换掉,我们可以把出现次数的数组放到集合 set 中,如果有重复的就会被替换掉,那么 set 的大小肯定和出现次数的数组长度不一样。
否则如果没有重复的,他们的长度肯定是一样的。

2.3 方法二: set 判断
思路与算法:
先计算每个数出现的次数。
在set集合中如果有相同的元素,就会存储失败,返回false,每次存储的时候我们只要判断是否存储成功即可。
2.4 方法三:使用数组
思路与算法:
题中提示中数组的大小和长度都有了限制,所以我们还可以使用数组。
先创建一个 2001 容量的数组,记录每个数的出现次数。
再次进行遍历这个数组,如果元素等于 0 那就继续遍历,不等于 0 的就向 set 数组里存元素,在set集合中如果有相同的元素,就会存储失败,返回false。
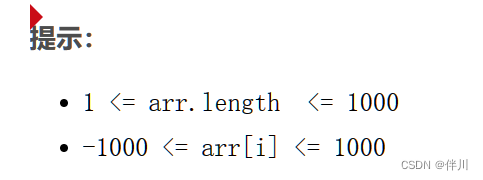
三、代码
2.2 方法一:判断长度
Java版本:
class Solution {
HashMap<Integer, Integer> map = new HashMap<>();
for (int i : arr) {
map.put(i, map.getOrDefault(i, 0) + 1);
}
return map.size() == new HashSet<>(map.values()).size();
}C++版本:
class Solution {
public:
bool uniqueOccurrences(vector<int>& arr) {
unordered_map<int, int> map;
for (int i : arr) {
map[i]++;
}
return map.size() == unordered_set<int>(map.begin(), map.end()).size();
}
};
2.3 方法二: set 判断
Java版本:
class Solution {
HashMap<Integer, Integer> map = new HashMap<>();
for (int i : arr) {
map.put(i, map.getOrDefault(i, 0) + 1);
}
HashSet<Integer> set = new HashSet<>();
for (Integer value : map.values()) {
if (!set.add(value)) {
return false;
}
}
return true;
}C++版本:
class Solution {
public:
bool uniqueOccurrences(vector<int>& arr) {
unordered_map<int, int> map;
for (int i : arr) {
map[i]++;
}
unordered_set<int> set;
for (auto& pair : map) {
if (!set.insert(pair.second).second) {
return false;
}
}
return true;
}
};
2.4 方法三:使用数组
Java版本:
class Solution {
public boolean uniqueOccurrences(int[] arr) {
int[] count = new int[2001];
for (int i : arr) {
count[1000 + i]++;
}
HashSet<Integer> set = new HashSet<>();
for (int i : count) {
if (i == 0) continue;
if (!set.add(i)) return false;
}
return true;
}
}C++版本:
class Solution {
public:
bool uniqueOccurrences(vector<int>& arr) {
vector<int> count(2001, 0);
for (int i : arr) {
count[1000 + i]++;
}
unordered_set<int> set;
for (int i : count) {
if (i == 0) continue;
if (set.count(i) > 0) return false;
set.insert(i);
}
return true;
}
};
四、复杂度分析
2.2 方法一:判断长度
- 时间复杂度:O(N)。
- 空间复杂度:O(N)。
2.3 方法二: set 判断
- 时间复杂度:O(N)。
- 空间复杂度:O(N)。
2.4 方法三:使用数组
- 时间复杂度:O(N)。
- 空间复杂度:O(N)。