京东云ClickHouse和ES双引擎设计在零售选品中的应用实践
背景介绍
涅槃选品是京东零售内的战略级bigboss项目,项目主要致力于构建商品底层能力,打通提报、投放流程,实现选品的线上化、规则化与智能化;通过多方协作盘货,充分表达营销、品类、运营/采销等多方意志。
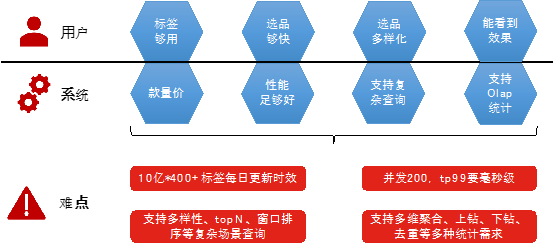
业务上的多样化需求,导致在项目初期面临以下众多技术难点与挑战。
面向研发排障的问题解决
为解决以上技术难点,京东零售整体设计了一套这样的技术方案:
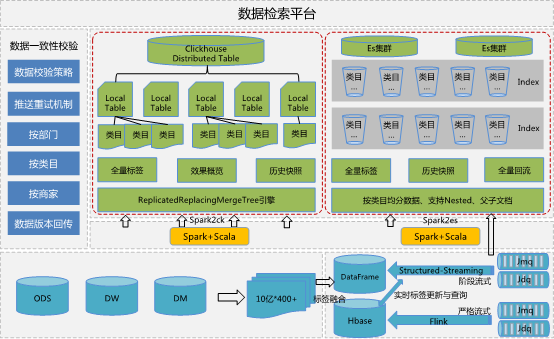
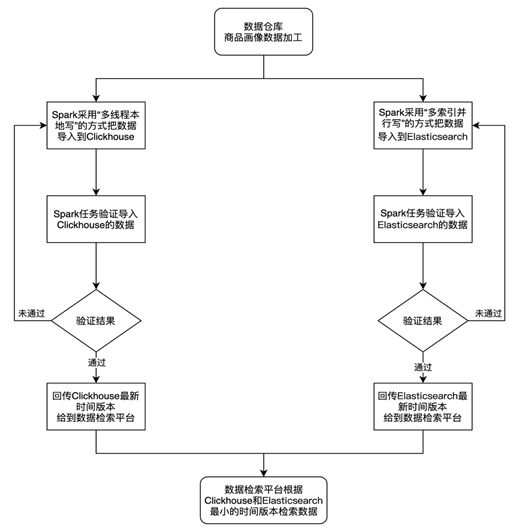
技术方案在数据存储查询上主要分成三个大模块:
模块一:ClickHouse与Elasticsearch存储结构设计模块;
模块二:ClickHouse数据推送与校验模块;
模块三:Elasticsearch数据推送与校验模块。
一、具体技术方案
主要解决的问题分为三点,第一点是解决快速筛选、快速多维统计查询两项不可兼得的问题,第二点是解决海量商品特征数据导入效率低的问题,第三点是解决海量商品特征数据占用存储资源较高的问题。本场景是一个商品规则化选品平台的项目,电商平台上有数百亿的商品,每一个商品都具有不同的特征数据,平台会持续发布一些营销活动,店铺可以提报部分商品参与这些营销活动,以达到平台营销、商家卖货的目的,而一个商家想要对本店铺的商品进行精准提报的话,就需要根据一定的规则选出目标商品,并且期望这些商品提报后能收到很好的效果;为了满足这一需求,会计算出全量商品的特征数据,全量商品数据量大概在百亿级别,通过前期的一些粗过滤,排除掉那部分很明显不适合参与活动的商品后,最终生成一个大宽表,包含数亿商品和数百个标签。
一般的做法是将数据直接导入数据库,或者是对数据进行一些预处理后导入数据库,提供给到检索平台进行查询,但是每种数据库都有其专长,几乎没有一种数据库在同时满足快速简单筛选的同时还能满足快速多维统计的查询需求;另外,大量的筛选任务需要历史数据,随着项目周期增长,历史数据占用大量存储资源的同时,还会影响整体查询效率。
本文提出Elasticsearch结合ClickHouse的方法,在存储上提出快照表的概念,基于Spark对Elasticsearch和ClickHouse进行离线数据导入和校验的方案,在仅保存两份全量最新数据的情况下,大幅降低了存储资源占用,兼顾了快速筛选和多维度统计查询,同时又能快速导入商品特征数据,极大的提高了数据的更新时效。
具体方法如下:
1、ClickHouse与Elasticsearch存储结构设计,具体方案细节如下:
a、存储上采用ClickHouse结合Elasticsearch的方案,主要是为了兼顾快速筛选(多基于Elasticsearch进行)的同时,还能进行快速多维统计查询(多基于ClickHouse进行),双存储引擎首先会遇到一个问题,就是两份数据的一致性问题,本发明通过在ClickHouse和Elasticsearch数据导入阶段进行数据验证来保证数据的一致性;
b、检索平台在进行数据查询的时候,在时间范围上分为两种,一种是新任务的实时查询,针对这部分任务,本发明在ClickHouse和Elasticsearch中分别建立一张表,ClickHouse每天生成一张新表,该表包含每个分片上的分布式表和本地表,分布式表用于进行数据查询,本地表设计为ReplicatedReplacingMergeTree引擎,用于数据导入,每日最新数据导入完成并数据校验通过后会清除该表的历史数据;Elasticsearch每天根据商品的类目信息分类,生成一批索引,这里之所以不用一个索引,是因为一个索引中数据量过大会影响查询效率,每日最新数据导入完成并数据校验通过后会清除历史索引的数据;
另一种是历史任务的实时查询,这部分查询需要用到历史数据,针对这类查询,本发明设计出一套快照表的概念,具体方案细节是:每日凌晨会针对前一天新建的任务进行一次遍历查询,获取到具体的商品id后,在数据仓库中进行加工,最终获取到前一天新建任务的全量商品特征数据,这部分数据不会再发生更新,是前一天新建任务的一个快照,在ClickHouse和Elasticsearch中分别建立一张快照表进行存储,与每日存储最新数据不同的是,Elasticsearch中的快照索引是根据快照数据中的任务信息生成的一批索引,不再是根据商品的类目信息,因为后续所有针对快照数据的查询,均是在一个任务范围内,这样设计能实现能快的查询效率。
c、除了上述两种时间范围上的查询,本场景还存在一种二次选品的实时查询,二次选品是指在历史任务的基础之上,再次进行简单的筛选,获取目标商品,这种选品场景比较特殊的是要用到一部分实时标签,针对这部分实时标签的存储设计,本发明采用了Elasticsearch的父子文档;具体方案是:每天在Elasticsearch中根据任务信息生成一批索引(架构图中的回流表),存储历史任务的商品特征数据,与快照不同的是,这批索引每天存储尚在有效期内的全量历史数据,并且索引采用的是父子文档结构,每天离线数据导入完成并数据校验通过后会清除历史索引数据,离线任务数据导入索引父文档,Structured-streaming任务会实时对子文档中的标签进行更新,这么设计,是因为父文档中存在数百个标签,每次更新效率低下,将仅有的几个实时标签放入子文档中更新,效率会比较高。
2、ClickHouse数据推送与校验
ClickHouse数据推送与校验架构流程图如下:
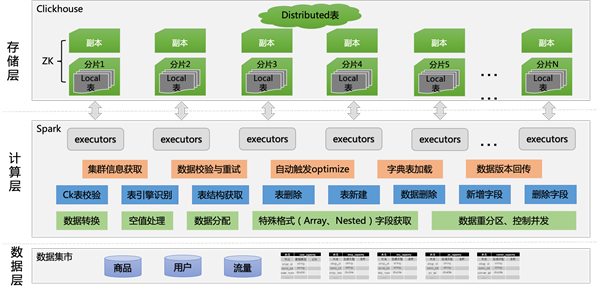
具体方案实施细节如下:
a、每日在数据仓库中对商品、用户、流量等数据进行加工融合,生成所需商品的特征数据,最终产生一张特征数据宽表;
b、启动Spark任务,首先读取到上一步产生的数据宽表,对数据进行处理,主要包含:根据配置文件中的ClickHouse表字段类型,对每个标签字段进行类型转换,对空值进行填充处理(ClickHouse表默认不能存储空值),对需要存储为Array、Nested等结构的字段进行特殊处理、格式转换等;
c、Spark任务从配置文件中获取到需要在ClickHouse中创建的表元数据信息,在ClickHouse集群中首先进行检测,查验最新表是否存在(分布式表和本地表是否都存在),如果存在则先进行数据删除(清除当天的误写的错误数据,不是历史数据),然后校验当前表的结构和配置文件是否一致,不一致则进行字段删除、字段增加等操作,保证表结构和配置文件一致;如果表不存在,则新建表,首先根据配置文件新建ClickHouse集群每个节点上的本地表,本地表引擎为ReplicatedReplacingMergeTree,而后根据本地表新建分布式表,本地表引擎设计为ReplicatedReplacingMergeTree主要有以下目的:一是利用Zookeeper的能力,保证ClickHouse每个分片中的副本间数据一致,这样数据导入只需要导入每个分片中的一个节点即可;二是利用ReplacingMergeTree引擎的能力,在数据导入完成后,进行optimize操作,来保证每个节点上没有重复数据;
d、对ClickHouse的表进行新建或更新完成后,Spark对读取到的数据,依据数据主键字段进行数据分配(对主键进行hash,再对ClickHouse的分片数量进行取模),以保证每个分片上的数据具有相同的规则,然后对分配好的数据进行repartition操作,将数据集控制到集群能接受的并行度,最后在Spark的Driver端多线程并行启动数据推送程序,利用JDBC的PreparedStatement按一定批次将数据写入ClickHouse表,以降低Spark对ClickHouse的请求频次;
e、在每个分片上的数据推送完成后,Spark会按照既定的规则对ClickHouse中的数据进行验证,本发明以商品的类目维度进行校验,即查询ClickHouse中所有类目下的数据量,和Spark从仓库中获取到的数据量进行校验,校验过程中会出现以下三种情况:
一是ClickHouse与仓库中统计到的数据量一致,那么当前类目数据验证通过;
二是ClickHouse中统计到的数据量要大于仓库中统计到的数据量,这时对当前分片的本地表进行optimize操作,合并数据后,再进行数据验证;
三是ClickHouse中统计到的数据量要小于仓库中统计到的数据量,这时对当前分片本地表中当前校验类目的数据进行重新推送,推送完成后再进行数据校验;
采取分维度的方式进行数据校验,能便于发现数据导入中的出现问题、及时高效的完成数据导入和校验;在整体数据校验通过后,Spark任务会将当前的时间版本回传给数据检索平台,告知ClickHouse中的最新数据已可用,然后对前天的历史数据进行清理,降低整体的存储资源占用。
该方案同样适用于快照数据、二次选品等数据的导入,仅是数据清理策略上不同。
3、Elasticsearch数据推送与校验
Elasticsearch数据推送与校验架构流程图如下:
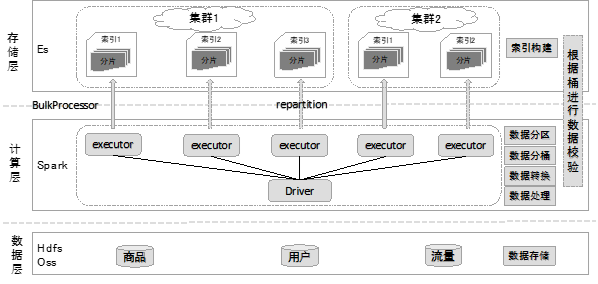
具体方案实施细节如下:
a、每日在数据仓库中对商品、用户、流量等数据进行加工融合,生成所需商品的特征数据,最终产生一张特征数据宽表(该步骤与ClickHouse数据推送与校验中的第一步共用);
b、启动Spark任务,首先读取到上一步产生的数据宽表,对数据进行处理,主要包含:根据配置文件中的Elasticsearch索引字段类型,对每个标签字段进行类型转换,用ClickHouse导入模块中相同的方式对空值进行填充处理(保证与ClickHouse中的数据一致性),对需要存储为Array、Nested等结构的字段进行特殊处理、格式转换,当推送的索引为父子文档时,还需要对数据集进行重组,以满足父子文档的数据结构;
c、Spark任务对数据集进行数据分维度统计,以便于创建一系列的索引,本发明是对数据集在商品类目维度上进行统计,得到每个类目的数据量后,依据当前Elasticsearch索引最新的配置信息,在Elasticsearch集群中创建既定数量的索引,再依据一定的算法逻辑,将每个类目分配到其中的一个索引上,保证同一类目的商品数据一定处于同一个索引中,而且每个索引的数据量尽可能的均匀;这样设计的目的是为了避免一个索引中数据量过大影响查询效率,同时能一定程度上提升整体的查询并发性能,而且该方案可依据业务体量进行横向扩充,比如增加集群数量;
d、从上一步中获取到了数据集每个类目的Elasticsearch索引归属信息,依据该关系,Spark任务对全量数据集进行分桶处理,每一个数据桶中的数据全部属于同一个Elasticsearch索引,分桶完成后基于Elasticsearch的Bulkprocessor方法,将数据批量的写入Elasticsearch,整体的写入逻辑是:以数据集的主键为Elasticsearch索引的_id,多集群的索引并行写、同集群的索引串行写;采用这种方式能避免同一个Elasticsearch集群存在多个写入点,导致大量reject,致使数据写入效率低下的问题,而多集群不存在共用写入点的问题,可以采用并行写来提升写入效率,同时以主键为_id,能避免数据写入重复的问题;
e、在每个索引的数据推送完成后,Spark会按照既定的规则对Elasticsearch中的数据进行验证,本发明以商品的类目维度进行校验,即查询Elasticsearch集群每个索引中所有类目下的数据量,和Spark从仓库中获取到的数据量进行校验,校验过程中会出现以下两种情况:
一是Elasticsearch与仓库中统计到的数据量一致,那么当前类目数据验证通过;
二是Elasticsearch中统计到的数据量要小于仓库中统计到的数据量,这时对当前类目的数据进行重复导入,数据导入完成后,再进行数据验证;
采取分维度的方式进行数据校验,能便于发现数据导入中的出现问题、及时高效的完成数据导入和校验;在整体数据校验通过后,Spark任务会将当前的时间版本回传给数据检索平台,告知Elasticsearch中的最新数据已可用,然后对前天的历史数据进行清理,降低整体的存储资源占用。
该方案同样适用于快照数据、二次选品等数据的导入,仅是数据清理策略上不同。
二、技术方案实施流程
具体流程如下:
三、测试结论
目前全量商品特征数据超过10亿,共490个标签,每天离线导入ClickHouse用时40min(40个分片),相较之前直写分布式表的方式,导入耗时平均降低80%;每天离线导入Elasticsearch用时2小时(单集群,可横向扩充),相较单索引写入的方式(偶尔会写不进去),导入耗时平均降低60%;在支持简单筛选和上下钻、top、窗口查询、多维度排序、关联聚合等复杂查询的同时,线上检索平台qps最高能达到300左右,tp99在毫秒级别;相较普通做法,本方案的方法将存储资源降低了60%-70%。
未来展望
该技术方案自项目上线以来,支撑了多场景、多业务方、多样化的选品流程,为整个选品的规则化、线上化、智能化提供了数据和索引的底层能力,虽然该方案满足了目前多方业务的切实需求,但是仍然存在很多优化点、扩展点待改进,具体如下:
一、双引擎的设计,虽然使目前这一套复杂的选品平台能够在巨量级数据(10亿实体、600+标签)上兼顾了快速筛选和复杂计算的能力,但是也会导致一个比较致命的问题,那就是双引擎数据一致性的问题,目前采取的方式是采取同一套默认值,数据更新后进行校验,但是每天校验的时间一定程度上影响了整体的数据更新时效,因此,这一块是后续需要去优化的一个比较重要的点。
二、目前整套系统600+标签,99%都是离线标签,实时标签仅有个位数,但是一个好的选品平台,肯定需要大量实时标签的加持;实时标签的写入、更新、索引建立,和离线标签比较起来有很大的不同,对上述所提到的数据一致性也会带来比较大的挑战,甚至是影响整个数据索引底层的架构设计。