异或 MTP 攻击
符号
⊕ 代表异或
C1 代表密文
M1 代表明文
性质
- 交换律
- 结合律 (a ⊕ b ) ⊕ c = a⊕ ( b ⊕ c)
- 任何数x x ⊕ x = 0 x ⊕ 0 = X
- 自反性 x ⊕ b ⊕ b = x ⊕ 0 = x
MTP 攻击
BUUCTF: [AFCTF2018]
25030206463d3d393131555f7f1d061d4052111a19544e2e5d54
0f020606150f203f307f5c0a7f24070747130e16545000035d54
1203075429152a7020365c167f390f1013170b1006481e13144e
0f4610170e1e2235787f7853372c0f065752111b15454e0e0901
081543000e1e6f3f3a3348533a270d064a02111a1b5f4e0a1855
0909075412132e247436425332281a1c561f04071d520f0b1158
4116111b101e2170203011113a69001b47520601155205021901
041006064612297020375453342c17545a01451811411a470e44
021311114a5b0335207f7c167f22001b44520c15544801125d40
06140611460c26243c7f5c167f3d015446010053005907145d44
0f05110d160f263f3a7f4210372c03111313090415481d49530f
设每一个字符为Ci,都是某个可以异或上明文 Mi 得到的.我们的目标是获取到这个key,已知明文是英文句子.
C
1
⨁
C
2
=
(
M
1
⨁
k
e
y
)
⨁
(
M
2
⨁
k
e
y
)
=
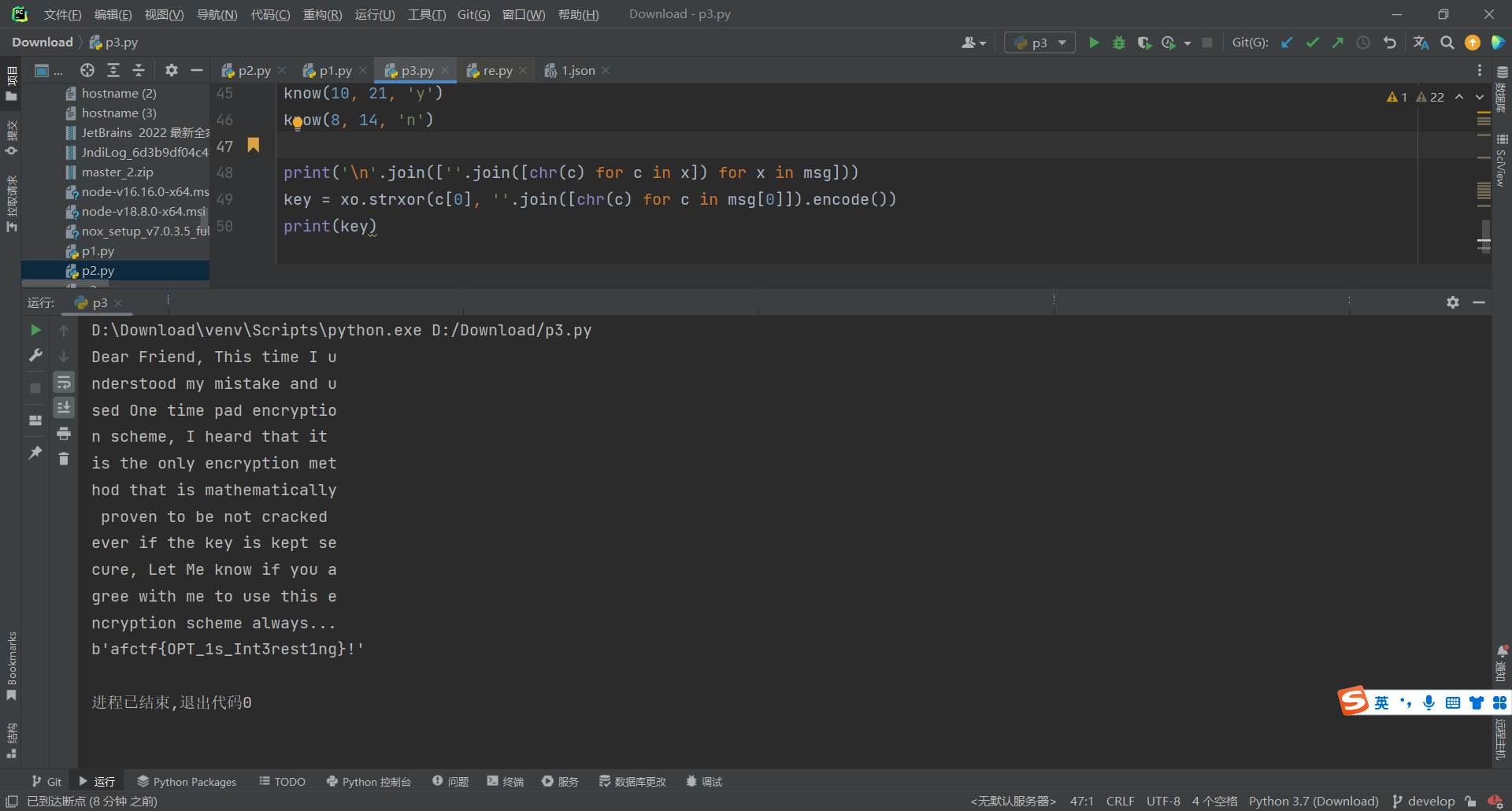
M
1
⨁
M
2
C_1 \bigoplus C_2 = (M_1 \bigoplus key) \bigoplus (M_2 \bigoplus key) = M_1 \bigoplus M_2
C1⨁C2=(M1⨁key)⨁(M2⨁key)=M1⨁M2
因此两个密文异或得到两个明文
我们使用C1异或上其他的密文
import binascii
import string
loca = string.ascii_lowercase + string.ascii_uppercase
def hextostr(hexstr):
hex = hexstr.encode("utf-8")
str_bin = binascii.unhexlify(hex)
return str_bin.decode("utf-8")
c1 = "25030206463d3d393131555f7f1d061d4052111a19544e2e5d"
c2 = '0f020606150f203f307f5c0a7f24070747130e16545000035d'
c3 = '1203075429152a7020365c167f390f1013170b1006481e1314'
c4 = '0f4610170e1e2235787f7853372c0f065752111b15454e0e09'
c5 = '081543000e1e6f3f3a3348533a270d064a02111a1b5f4e0a18'
c6 = '0909075412132e247436425332281a1c561f04071d520f0b11'
c7 = '4116111b101e2170203011113a69001b475206011552050219'
c8 = '041006064612297020375453342c17545a01451811411a470e'
c9 = '021311114a5b0335207f7c167f22001b44520c15544801125d'
c10 = '06140611460c26243c7f5c167f3d015446010053005907145d'
c11 = '0f05110d160f263f3a7f4210372c03111313090415481d49'
chiphers =[c1, c2, c3, c4, c5, c6, c7, c8, c9, c10, c11]
s2 = hextostr(c2)
sc1 = hextostr(c1)
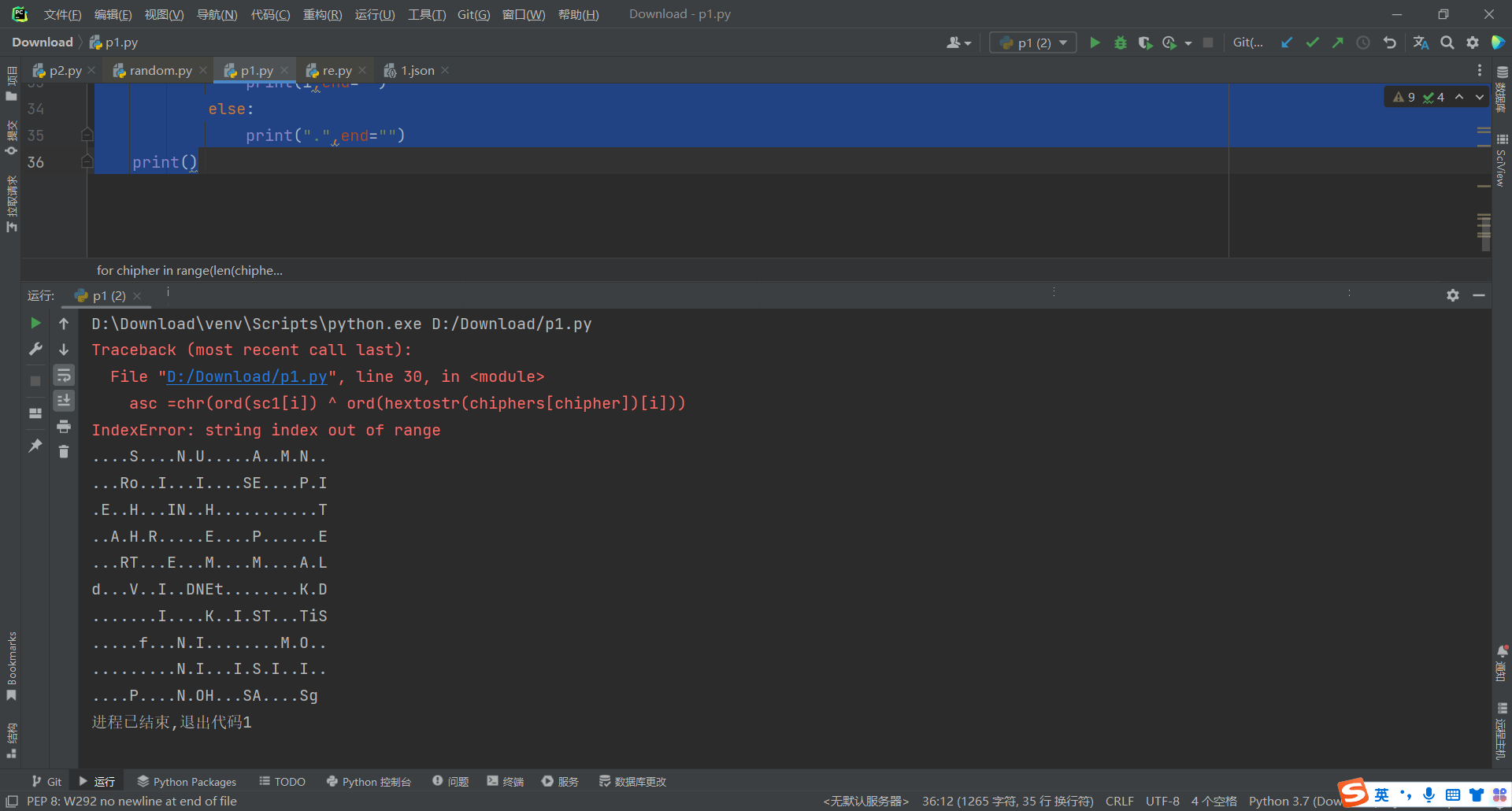
for chipher in range(len(chiphers)):
if chipher == 0:
continue
for i in range(len(sc1)):
asc =chr(ord(sc1[i]) ^ ord(hextostr(chiphers[chipher])[i]))
for i in asc:
if i in loca:
print(i,end="")
else:
print(".",end="")
print()
我们可以得到一个重要的规律 小写字母⊕ 空格 得到的是大写字母;大写字母 ⊕ 空格会得到小写字母 x ⊕ y 得到一个英文字母,那么 x y 中的的某一个有很大的概率是空格 那么来看 C1 ⊕ 其他密文 也就是M1 ⊕ 其他明文的表,如果第 col列存在大量英文字母,我们可以猜测 M1 [col] 是一个空格 知道M1 的col位是空格有什么用呢
M
i
[
c
o
l
]
=
M
1
[
c
o
l
]
⨁
M
i
[
c
o
l
]
=
M
1
[
c
o
l
]
⨁
M
i
[
c
o
l
]
⨁
0
x
20
M_i[col] = M_1[col] \bigoplus M_i[col] = M_1[col] \bigoplus M_i[col] \bigoplus 0x20
Mi[col]=M1[col]⨁Mi[col]=M1[col]⨁Mi[col]⨁0x20
攻击过程 对于每一条密文C1,拿去异或其他所有的密文,然后去数每一列上面有多少个英文字符,作为 Mi在这一位上面是空格的标准
import Crypto.Util.strxor as xo
import libnum, codecs, numpy as np
def isChr(x):
if ord('a') <= x and x <= ord('z'): return True
if ord('A') <= x and x <= ord('Z'): return True
return False
def infer(index, pos):
if msg[index, pos] != 0:
return
msg[index, pos] = ord(' ')
for x in range(len(c)):
if x != index:
msg[x][pos] = xo.strxor(c[x], c[index])[pos] ^ ord(' ')
dat = []
def getSpace():
for index, x in enumerate(c):
res = [xo.strxor(x, y) for y in c if x!=y]
f = lambda pos: len(list(filter(isChr, [s[pos] for s in res])))
cnt = [f(pos) for pos in range(len(x))]
for pos in range(len(x)):
dat.append((f(pos), index, pos))
c = [codecs.decode(x.strip().encode(), 'hex') for x in open('Problem.txt', 'r').readlines()]
msg = np.zeros([len(c), len(c[0])], dtype=int)
getSpace()
dat = sorted(dat)[::-1]
for w, index, pos in dat:
infer(index, pos)
print('\n'.join([''.join([chr(c) for c in x]) for x in msg]))
脚本太复杂了 看不太懂
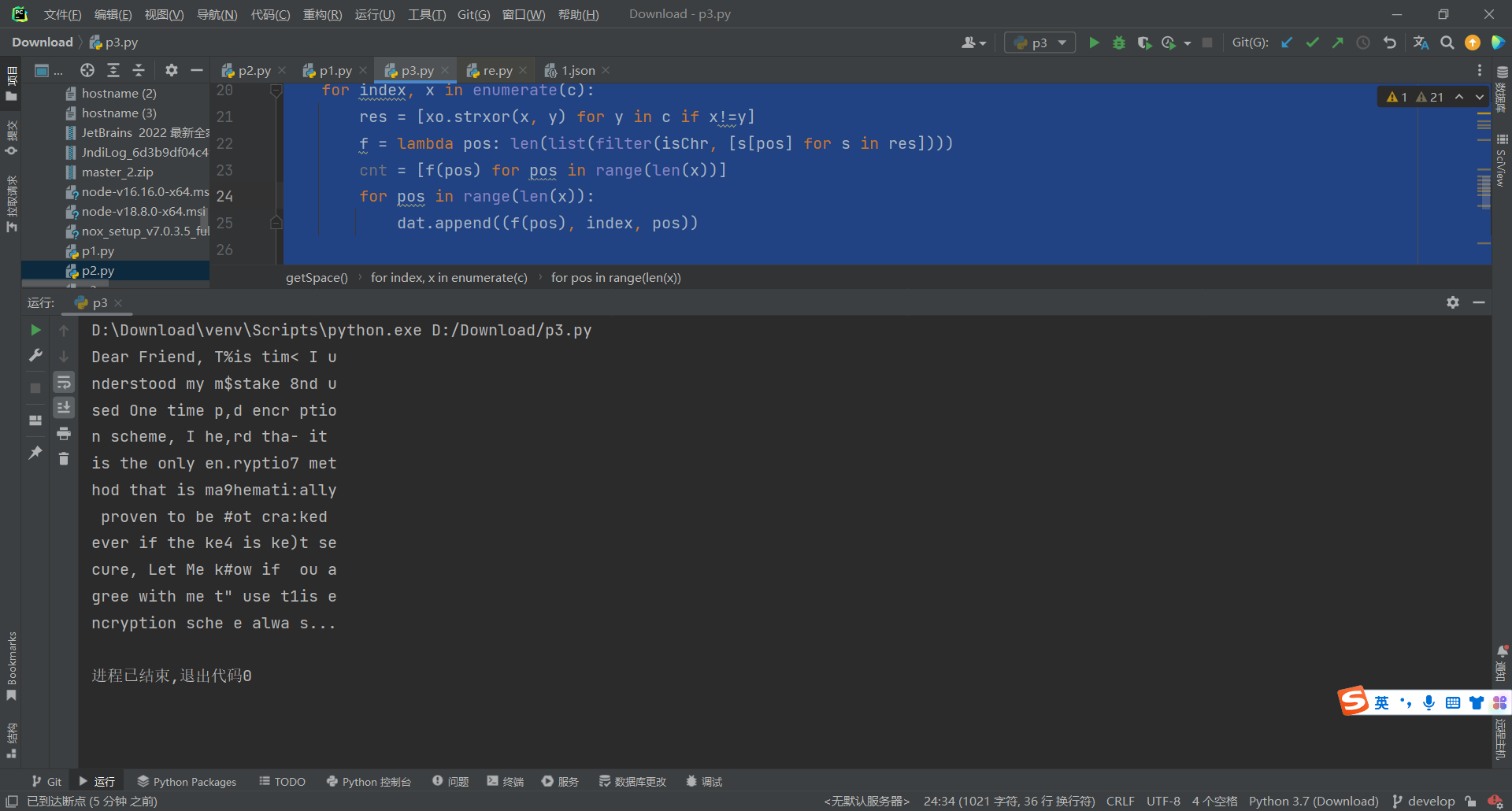
这里需要修正一下 将k#now 修复成know 把 alwa s 修复成 always
def know(index, pos, ch):
msg[index, pos] = ord(ch)
for x in range(len(c)):
if x != index:
msg[x][pos] = xo.strxor(c[x], c[index])[pos] ^ ord(ch)
know(10, 21, 'y')
know(8, 14, 'n')
print('\n'.join([''.join([chr(c) for c in x]) for x in msg]))
import Crypto.Util.strxor as xo
import libnum, codecs, numpy as np
def isChr(x):
if ord('a') <= x and x <= ord('z'): return True
if ord('A') <= x and x <= ord('Z'): return True
return False
def infer(index, pos):
if msg[index, pos] != 0:
return
msg[index, pos] = ord(' ')
for x in range(len(c)):
if x != index:
msg[x][pos] = xo.strxor(c[x], c[index])[pos] ^ ord(' ')
def know(index, pos, ch):
msg[index, pos] = ord(ch)
for x in range(len(c)):
if x != index:
msg[x][pos] = xo.strxor(c[x], c[index])[pos] ^ ord(ch)
dat = []
def getSpace():
for index, x in enumerate(c):
res = [xo.strxor(x, y) for y in c if x!=y]
f = lambda pos: len(list(filter(isChr, [s[pos] for s in res])))
cnt = [f(pos) for pos in range(len(x))]
for pos in range(len(x)):
dat.append((f(pos), index, pos))
c = [codecs.decode(x.strip().encode(), 'hex') for x in open('Problem.txt', 'r').readlines()]
msg = np.zeros([len(c), len(c[0])], dtype=int)
getSpace()
dat = sorted(dat)[::-1]
for w, index, pos in dat:
infer(index, pos)
know(10, 21, 'y')
know(8, 14, 'n')
print('\n'.join([''.join([chr(c) for c in x]) for x in msg]))
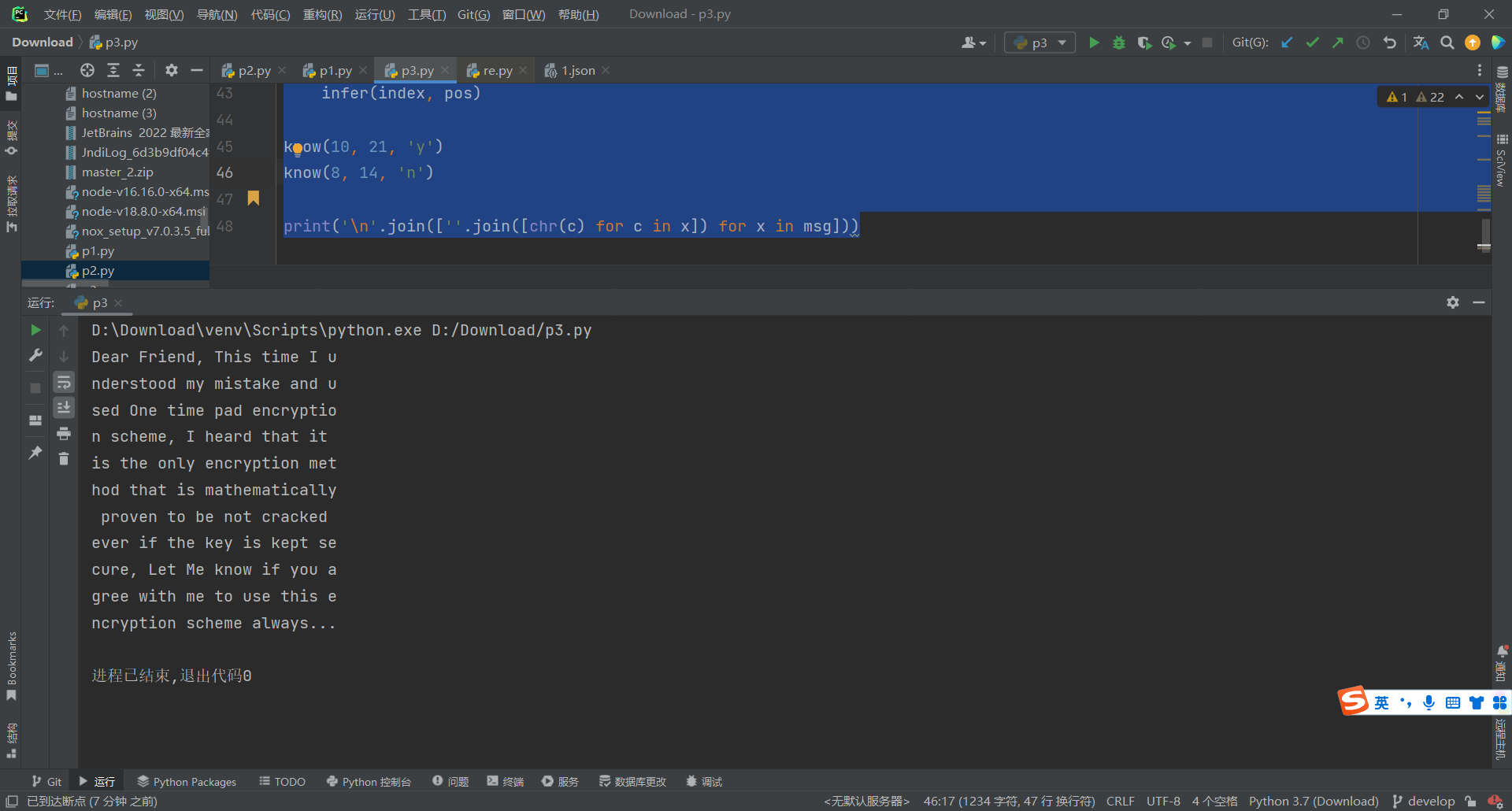
接着需要C1 ⊕ M1 = key
import Crypto.Util.strxor as xo
import libnum, codecs, numpy as np
def isChr(x):
if ord('a') <= x and x <= ord('z'): return True
if ord('A') <= x and x <= ord('Z'): return True
return False
def infer(index, pos):
if msg[index, pos] != 0:
return
msg[index, pos] = ord(' ')
for x in range(len(c)):
if x != index:
msg[x][pos] = xo.strxor(c[x], c[index])[pos] ^ ord(' ')
def know(index, pos, ch):
msg[index, pos] = ord(ch)
for x in range(len(c)):
if x != index:
msg[x][pos] = xo.strxor(c[x], c[index])[pos] ^ ord(ch)
dat = []
def getSpace():
for index, x in enumerate(c):
res = [xo.strxor(x, y) for y in c if x!=y]
f = lambda pos: len(list(filter(isChr, [s[pos] for s in res])))
cnt = [f(pos) for pos in range(len(x))]
for pos in range(len(x)):
dat.append((f(pos), index, pos))
c = [codecs.decode(x.strip().encode(), 'hex') for x in open('Problem.txt', 'r').readlines()]
msg = np.zeros([len(c), len(c[0])], dtype=int)
getSpace()
dat = sorted(dat)[::-1]
for w, index, pos in dat:
infer(index, pos)
know(10, 21, 'y')
know(8, 14, 'n')
print('\n'.join([''.join([chr(c) for c in x]) for x in msg]))
key = xo.strxor(c[0], ''.join([chr(c) for c in msg[0]]).encode())
print(key)