优化算法使用总结——0.618法、梯度下降、牛顿法、共轭梯度、外罚、内罚
实用优化算法总结
实用优化算法的种类繁多,并且各自使用的领域有所区别,为此,设计有多种优化算法,本文着重介绍其中几种,见目录。
本篇中涉及到的实验代码已上传至GitHub
最优化问题,可以分为两大部分“无约束最优化问题”和“约束最优化问题”。
目录
无约束最优化问题
黄金分割法
黄金分割法,也叫0.618(
τ
=
0.618
τ=0.618
τ=0.618)法,这个方法可所谓足够简单,同时它适用的范围也就相对有限,需要给定单峰目标函数,以及代求区间[
a
a
a0,
b
b
b0]
算法设计:
步骤1:给定
a
a
a0>0,
b
b
b0>0,i=0,ε>0,
τ
=
0.618
τ=0.618
τ=0.618
步骤2:若
b
b
bi-
a
a
ai<ε,则
α
α
α*=
b
i
+
a
i
2
\frac{b_i+a_i}{2}
2bi+ai,输出
α
α
α*,算法停止
步骤3:计算
α i r α^r_i αir= a a a i + + + τ τ τ( b b b i- a a a i ) ) )
步骤4:若 α i l α_i^l αil< α i r α_i^r αir,则 a a a i+1= a a a i, b b b i+1= α i r α^r_i αir ,否则 a a a i+1= α i l α^l_i αil, b b b i+1= b b b i ,转步骤2
通过上述算法步骤,容易得知当 τ τ τ时,从区间[ a a a 0, b b b 0]开始迭代,经过m次迭代后,区间长度为 τ τ τ m( b b b 0- a a a 0).
看流程图可能思路更清晰:
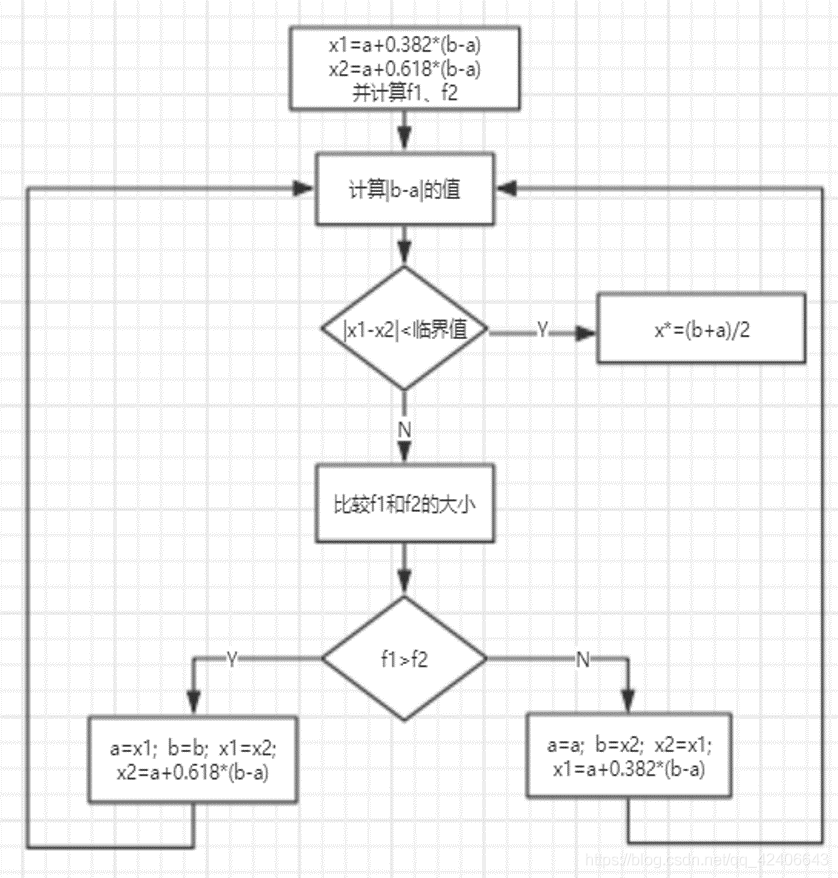
那我们可能会想,既然区间在每次迭代都会缩短,那如何使它每次缩短到不能再缩短就可以达到最快速度了,基于这种想法, τ τ τ可以取不同值,相较于0.618,事实上我们可以用斐波那契数列来替换每次的 τ τ τ
例题:
f
(
x
)
=
e
x
+
1
/
e
x
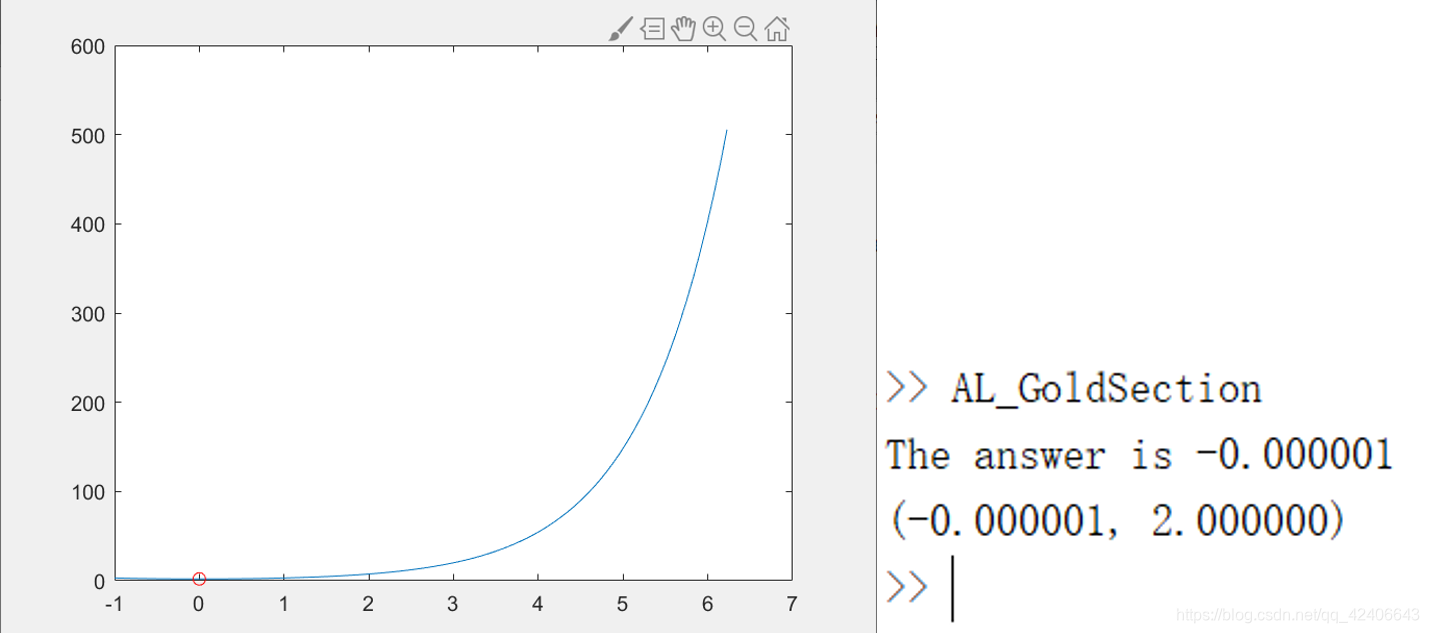
f(x)=e^x+1/e^x
f(x)=ex+1/ex 在[-1,2]区间内的极小值点、极小值,运行结果如下:
最速下降法
最速下降法,又叫梯度下降法,具有代码实现简单、原理简单的特点。
通过梯度概念的学习,我们都知道梯度代表的方向是函数递增最快的方向,所以负梯度方向就是函数递进最快的方向,由此,我们利用函数每次的负梯度方向作为搜索方向,利用上述的黄金分割法搜索目标函数在搜索方向上的极小值作为前进的步长,就可得到最速下降法,详情见下方算法设计。
这里提到的搜索方向、步长类似于神经网络中的概念,如步长类似于学习率
算法设计:
步骤1:给出
x
0
∈
R
n
x_0∈R^n
x0∈Rn
×
\times
×
R
n
R^n
Rn,k=0,ε>0
步骤2:若终止条件满足(
∣
∣
g
k
∣
∣
<
ε
||g_k||<ε
∣∣gk∣∣<ε),则迭代停止
步骤3:计算
d
k
=
−
g
k
d_k=-g_k
dk=−gk
步骤4:在
d
k
d_k
dk方向上利用一维精确线性搜索(如黄金分割法、多项式插值法)求步长
α
k
α_k
αk
步骤5:
x
k
+
1
=
x
k
+
α
k
d
k
,
k
=
k
+
1
x_{k+1}=x_k+α_kd_k,k=k+1
xk+1=xk+αkdk,k=k+1,转步骤2
缺点:会产生Zigzag现象,由于采用精确搜索、且搜索方向为负梯度方向,造成了该方法收敛速度不够快,效率不高的缺点。
例题:
m
i
n
(
x
1
2
+
2
x
2
2
)
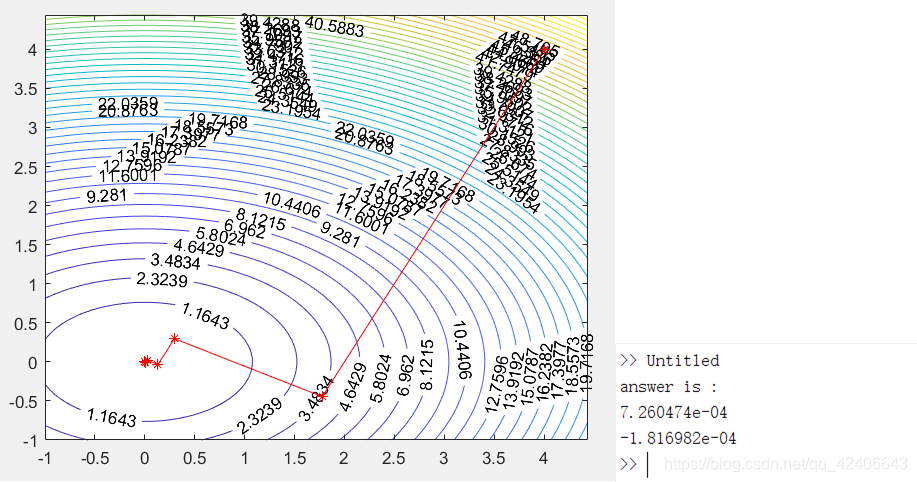
min(x_1^2+2x_2^2)
min(x12+2x22),初始点为
x
0
=
(
4
,
4
)
x_0=(4,4)
x0=(4,4),求最小值点。运行结果如下图:
牛顿法
这个方法是个大家庭,其中有基本牛顿法、阻尼牛顿法、拟牛顿法
相较于梯度下降法,梯度下降法只用到了一次导数,而牛顿法引入高阶导数,提高了算法效率。
利用泰勒展开式:
q
k
(
x
)
=
f
(
x
)
=
f
(
x
k
)
+
▽
f
T
(
x
−
x
k
)
+
1
2
(
x
−
x
k
)
T
G
k
(
x
−
x
k
)
q_k(x)=f(x)=f(x_k)+▽f^T(x-x_k)+\frac{ 1}{ 2}(x-x_k)^TG_k(x-x_k)
qk(x)=f(x)=f(xk)+▽fT(x−xk)+21(x−xk)TGk(x−xk)
当Gk正定时,
q
k
(
x
)
q_k(x)
qk(x)有唯一极小点,同时
G k ( x k + 1 − x k ) + ▽ f k = 0 G_k(x_{k+1}-x_k)+▽f_k=0 Gk(xk+1−xk)+▽fk=0
x k + 1 = x k + G k − 1 ▽ f k x_{k+1}=x_k+G^{-1}_k▽f_k xk+1=xk+Gk−1▽fk 【 递推式】
通过上述的分析,可以得到牛顿法的递推式 x k + 1 = x k + G k − 1 ▽ f k x_{k+1}=x_k+G^{-1}_k▽f_k xk+1=xk+Gk−1▽fk,令 d k = − G k − 1 ▽ f k d_k=-G^{-1}_k▽f_k dk=−Gk−1▽fk( ▽ f k ▽f_k ▽fk即 g k g_k gk)
基本牛顿法
算法设计:
步骤1:给出
x
0
∈
R
n
x_0∈R^n
x0∈Rn
×
\times
×
R
n
R^n
Rn,k=0,ε>0
步骤2:若终止条件满足(
∣
∣
g
k
∣
∣
<
ε
||g_k||<ε
∣∣gk∣∣<ε),则迭代停止
步骤3:计算
d
k
d_k
dk
步骤4:计算
x
k
+
1
=
x
k
+
d
k
,
k
=
k
+
1
x_{k+1}=x_k+d_k,k=k+1
xk+1=xk+dk,k=k+1,转步骤2
特点:
1.当初始点选取位置靠近最优解位置时,算法可以达到二次收敛
2.对于正定二次函数,牛顿法可以一次迭代求出最优解
3.对多数问题并非全局收敛,收敛至鞍点、极大点的概率不小
4.计算量相对于梯度下降法增大,且计算机计算逆矩阵较为耗时
例题1:
x
1
2
+
4
x
2
2
+
9
x
3
2
−
2
x
1
+
18
x
2
x_1^2+4x_2^2+9x_3^2-2x_1+18x_2
x12+4x22+9x32−2x1+18x2 的极小点,求解结果如下:
初始点取得是
x
0
=
(
1
,
1
,
1
)
x_0=(1,1,1)
x0=(1,1,1)
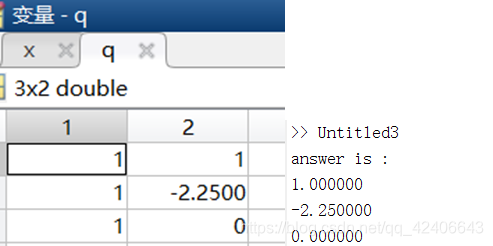
通过结果可以得知,对于正定二次函数,基本牛顿法经过一次迭代即可求解。
例题2:利用Newton法求解
m
i
n
(
x
1
−
1
)
2
+
2
x
2
2
min (x_1-1)^2+2x_2^2
min(x1−1)2+2x22的极小点,
x
0
=
(
0
,
1
)
T
x_0=(0,1)^T
x0=(0,1)T,求解结果如下图:
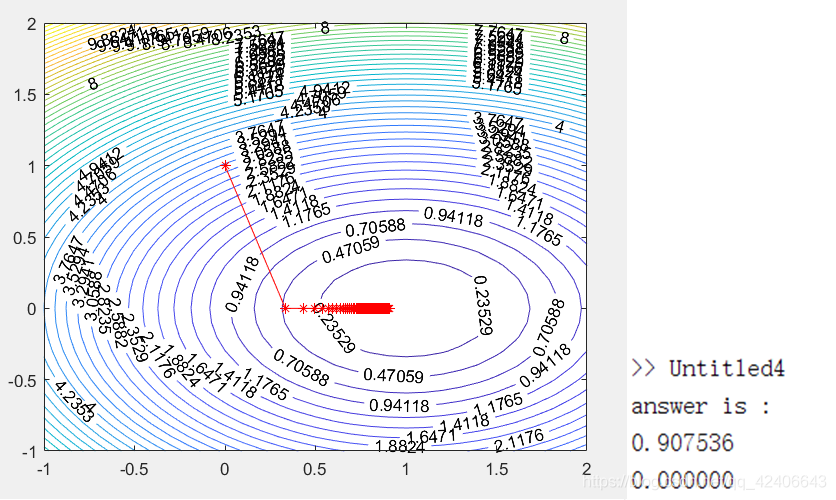
借助图像可以看出来,基本牛顿法对于非二次函数问题,求解较为低效。
阻尼牛顿法
算法设计:
步骤1:给出
x
0
∈
R
n
x_0∈R^n
x0∈Rn
×
\times
×
R
n
R^n
Rn,k=0,ε>0
步骤2:若终止条件满足(
∣
∣
g
k
∣
∣
<
ε
||g_k||<ε
∣∣gk∣∣<ε),则迭代停止
步骤3:计算
d
k
d_k
dk,在
d
k
d_k
dk方向上利用一维精确线性搜索(如黄金分割法、多项式插值法)求步长
α
k
α_k
αk
步骤4:计算
x
k
+
1
=
x
k
+
α
k
d
k
,
k
=
k
+
1
x_{k+1}=x_k+α_kd_k,k=k+1
xk+1=xk+αkdk,k=k+1,转步骤2
相较于基牛顿法,阻尼牛顿法在其基础上,使用了线性搜索,克服了基本牛顿法的3、4缺点
LM方法:克服 G − 1 G^{-1} G−1奇异、非正定的问题
由于上述的基本牛顿法、阻尼牛顿法,均使用到了 G − 1 G^{-1} G−1,且要求 G G G为正定矩阵,但现实情况不可能总符合要求。
当 g k T d k < 0 g^T_kd_k<0 gkTdk<0,即 − g k T G k − 1 g k < 0 -g^T_kG^{-1}_kg_k<0 −gkTGk−1gk<0,则 d k d_k dk为下降方向
当 G G G非正定时,我们知道特征值( λ i , i ∈ N λ_i,i∈N λi,i∈N)非全部大于0,此时我们需要对矩阵 G G G进行改造:( I I I为单位矩阵, v k > 0 v_k>0 vk>0)
此时矩阵 ( G k + v k I ) (G_k+v_kI) (Gk+vkI)的特征值为 λ i + v k , i ∈ N λ_i+v_k,i∈N λi+vk,i∈N,若是所有特征值均大于0,则 v k v_k vk取合适值即可。
拟牛顿法
也是本人最为喜欢的一种优化算法,方法思想,引入矩阵
H
k
H_k
Hk逼近
G
k
−
1
G_k^{-1}
Gk−1,而并非直接计算
G
k
−
1
G_k^{-1}
Gk−1。
算法设计:
步骤1:给出
x
0
∈
R
n
x_0∈R^n
x0∈Rn
×
\times
×
R
n
R^n
Rn,对称正定矩阵
H
0
∈
R
n
H_0∈R^n
H0∈Rn
×
\times
×
R
n
R^n
Rn,
k
=
0
,
ε
>
0
k=0,ε>0
k=0,ε>0
步骤2:若终止条件满足(
∣
∣
g
k
∣
∣
<
ε
||g_k||<ε
∣∣gk∣∣<ε),则迭代停止
步骤3:计算
d
k
=
−
H
k
g
k
d_k=-H_kg_k
dk=−Hkgk,在
d
k
d_k
dk方向上线性搜索求步长
α
k
α_k
αk,计算
x
k
+
1
=
x
k
+
α
k
d
k
x_{k+1}=x_k+α_kd_k
xk+1=xk+αkdk
步骤4:更新
H
k
H_k
Hk得
H
k
+
1
H_{k+1}
Hk+1,使得
H
k
+
1
H_{k+1}
Hk+1满足A式,
k
=
k
+
1
k=k+1
k=k+1,转步骤2
A式:
- 秩一矫正:
H
k
+
1
=
H
k
+
β
u
u
T
H_{k+1}=H_k+βuu^T
Hk+1=Hk+βuuT (
u
,
β
∈
R
n
u,β∈R^n
u,β∈Rn
×
\times
×
R
n
R^n
Rn)
H k + 1 S R 1 = H k + ( s k − H k y k ) ( s k − H k ) T ( s k − H k y k ) T y k H_{k+1}^{SR1}=H_k+\frac{(s_k-H_ky_k)(s_k-H_k)^T}{ (s_k-H_ky_k)^Ty_k} Hk+1SR1=Hk+(sk−Hkyk)Tyk(sk−Hkyk)(sk−Hk)T
实现简单,但此方法不能满足正定继承性 - DFP公式:
H k + 1 D F P = H k + s k s k T s k T y k − H k y k y k T H k y k T H k y k H_{k+1}^{DFP}=H_k+\frac{s_ks_k^T}{s_k^Ty_k}-\frac{H_ky_ky_k^TH_k}{y_k^TH_ky_k} Hk+1DFP=Hk+skTykskskT−ykTHkykHkykykTHk
满足正定继承性,即 H 0 H_0 H0为正定则 H k H_k Hk为正定 - BFGS公式:(被誉为最好用的算法)
H k + 1 B F G S = H k + ( 1 + y k T H k y k y k T s k ) s k s k T y k T s k − ( s k y k T H k + H k y k s k T y k T s k ) H_{k+1}^{BFGS}=H_k+(1+\frac{y_k^TH_ky_k}{y_k^Ts_k})\frac{s_ks_k^T}{y_k^Ts_k}-(\frac{s_ky_k^TH_k+H_ky_ks_k^T}{y_k^Ts_k}) Hk+1BFGS=Hk+(1+ykTskykTHkyk)ykTskskskT−(ykTskskykTHk+HkykskT)
特点:
1.克服了牛顿法计算量大的问题
2.避免了矩阵非正定的问题
3.效率高,收敛快,具有二次终止性
例题:利用DFP拟牛顿法求解
m
i
n
(
x
1
2
+
x
2
2
−
x
1
x
2
+
2
x
1
−
4
x
2
)
min(x_1^2+x_2^2-x_1x_2+2x_1-4x_2)
min(x12+x22−x1x2+2x1−4x2)的最优解,运行结果如下图
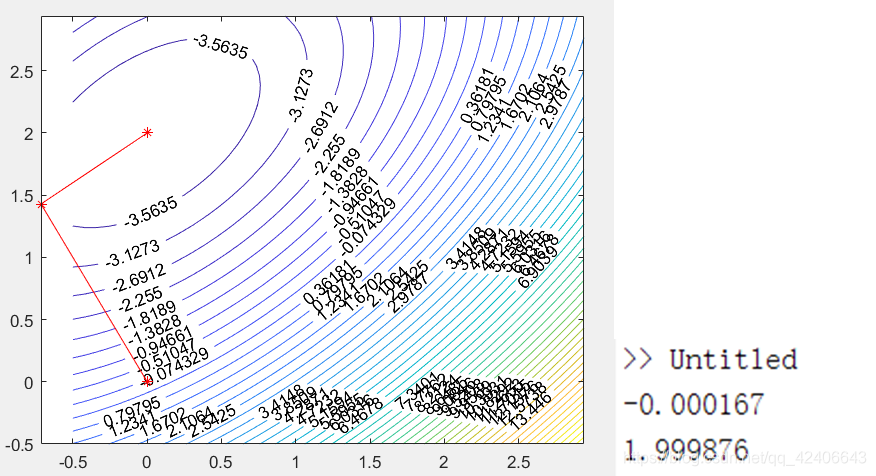
好用!
共轭方向法
由于对于二次函数,形如
f
(
x
)
=
1
2
x
T
G
x
+
b
T
x
+
C
f(x)=\frac{1}{2}x^T Gx+b^Tx+C
f(x)=21xTGx+bTx+C,当
G
G
G正定时, Newton只需要迭代一次即可找到最优解,而梯度下降法需要无数次。但同时Newton法每迭代一步计算量较大,反而最速下降法计算量十分小,故一种折中的算法:共轭方向法
引入:
如二维二次函数要在两次迭代内最小计算量求出最优解:
| 迭代点 | 搜索方向 | 最优步长 |
|---|---|---|
| x 0 x_0 x0 | d 0 d_0 d0 | a 0 a_0 a0 |
| x 1 x_1 x1 | d 1 d_1 d1 | a 1 a_1 a1 |
| x ∗ = x 2 x^*=x_2 x∗=x2 | ||
| ▽ f ( x 2 ) = G x 2 + b = G ( x 1 + a 1 d 1 ) + b = ( G x 1 + b ) + a 1 G d 1 = 0 ▽f(x_2)=Gx_2+b=G(x_1+a_1d_1)+b=(Gx_1+b)+a_1 Gd_1=0 ▽f(x2)=Gx2+b=G(x1+a1d1)+b=(Gx1+b)+a1Gd1=0 | ||
| 又因为精确搜索 ▽ f ( x k + 1 ) T d k = 0 ▽f(x_{k+1})^Td_k=0 ▽f(xk+1)Tdk=0 | ||
| 得 ( G x 1 + b ) T d 0 = 0 (Gx_1+b)^Td_0=0 (Gx1+b)Td0=0 | ||
| 得 0 = d 0 T ( ( G x 1 + b ) + a 1 G d 1 ) = a 1 d 0 T G d 1 0=d_0^T((Gx_1+b)+a_1Gd_1)=a_1d_0^T Gd_1 0=d0T((Gx1+b)+a1Gd1)=a1d0TGd1 | ||
| 则满足 d 0 T G d 1 = 0 d_0^T Gd_1=0 d0TGd1=0,即两次迭代中搜索方向为共轭方向 |
设 G G G为n阶正定矩阵, d 1 , d 2 , d 3 . . . . . . d k d_1,d_2,d_3......d_k d1,d2,d3......dk为n维向量,如果 d i T G d j = 0 d_i^TGd_j=0 diTGdj=0( i ≠ j i≠j i=j, i , j = 1 , 2 , 3...... k i,j=1,2,3......k i,j=1,2,3......k),则称 d 1 , d 2 , d 3 . . . . . . d k d_1,d_2,d_3......d_k d1,d2,d3......dk向量组关于 G G G共轭。
共轭梯度法
由于共轭方向法需要在计算前提供一组完整的共轭方向,这显然无法达到自动化算法的目的,故我们想要算法在迭代过程中自动计算下一次迭代的共轭方向,引入共轭梯度法
算法设计:
步骤1:
x
0
∈
R
n
,
k
=
0
x_0∈R^n,k=0
x0∈Rn,k=0
步骤2:若
∣
∣
g
k
∣
∣
≦
ε
||g_k||≦ε
∣∣gk∣∣≦ε,停止迭代
步骤3:若
k
=
0
,则
β
−
1
=
0
,否则计算
β
k
−
1
,令
d
k
=
−
g
k
+
β
k
−
1
d
k
−
1
k=0,则β_{-1}=0,否则计算β_{k-1},令d_k=-g_k+β_{k-1}d_{k-1}
k=0,则β−1=0,否则计算βk−1,令dk=−gk+βk−1dk−1
步骤4:一维精确搜索得步长
α
k
α_k
αk
步骤5:
x
k
+
1
=
x
k
+
α
k
d
k
,
k
+
+
,转步骤
2
x_{k+1}=x_k+α_kd_k,k++,转步骤2
xk+1=xk+αkdk,k++,转步骤2
注:
① d 0 = − g 0 d_0=-g_0 d0=−g0
② d k = − g k + β k − 1 d k − 1 ,由 d k T G d k − 1 = 0 得 β k − 1 = g k T G d k − 1 d k − 1 T G d k − 1 d_k=-g_k+β_{k-1}d_{k-1},由d_k^TGd_{k-1}=0得β_{k-1}=\frac {g_k^T Gd_{k-1}}{d_{k-1}^T Gd_{k-1}} dk=−gk+βk−1dk−1,由dkTGdk−1=0得βk−1=dk−1TGdk−1gkTGdk−1
若采用非精确搜索,则FR、PRP可能产生上升的方向,导致效果不好。
共轭梯度法和共轭方向法均满足有限终止性
同时
β
k
−
1
β_{k-1}
βk−1还有其他形式:
FR共轭梯度法:
β
k
−
1
=
g
k
T
g
k
g
k
−
1
T
g
k
−
1
β_{k-1}=\frac{g_k^Tg_k}{g_{k-1}^Tg_{k-1}}
βk−1=gk−1Tgk−1gkTgk
PRP共轭梯度法:
β
k
−
1
=
g
k
T
(
g
k
−
g
k
−
1
)
g
k
−
1
T
g
k
−
1
β_{k-1}=\frac{g_k^T(g_k-g_{k-1})}{g_{k-1}^Tg_{k-1}}
βk−1=gk−1Tgk−1gkT(gk−gk−1)
重开始的共轭梯度法:即每迭代n次,就重新将搜索方向设为负梯度方向
约束最优化问题
一般约束优化问题
等下次更新吧