十分钟搞懂MySQL 如何实现四大隔离级别
脏读、不可重复读、幻读理解
1、脏读:脏读就是指当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务也访问这个数据,然后使用了这个数据。
例如:
张三的工资为5000,事务A中把他的工资改为8000,但事务A尚未提交。
与此同时, 事务B正在读取张三的工资,读取到张三的工资为8000。
随后, 事务A发生异常,而回滚了事务。张三的工资又回滚为5000。
最后, 事务B读取到的张三工资为8000的数据即为脏数据,事务B做了一次脏读。
2、不可重复读:是指在一个事务内,多次读同一数据。在这个事务还没有结束时,另外一个事务也访问该同一数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改,那么第一个事务两次读到的的数据可能是不一样的。这样就发生了在一个事务内两次读到的数据是不一样的,因此称为是不可重复读。
例如:
在事务A中,读取到张三的工资为5000,操作没有完成,事务还没提交。
与此同时, 事务B把张三的工资改为8000,并提交了事务。
随后, 在事务A中,再次读取张三的工资,此时工资变为8000。在一个事务中前后两次读取的结果并不致,导致了不可重复读。
3、幻读:是指当事务不是独立执行时发生的一种现象,例如第一个事务对一个表中的数据进行了修改,这种修改涉及到表中的全部数据行。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入一行新数据。那么,以后就会发生操作第一个事务的用户发现表中还有没有修改的数据行,就好象发生了幻觉一样。
例如:
目前工资为5000的员工有10人,事务A读取所有工资为5000的人数为10人。
此时, 事务B插入一条工资也为5000的记录。
这是,事务A再次读取工资为5000的员工,记录为11人。此时产生了幻读。
4、提醒
不可重复读的重点是修改:
同样的条件,你读取过的数据,再次读取出来发现值不一样了
幻读的重点在于新增或者删除:
同样的条件,第 1 次和第 2 次读出来的记录数不一样
5、第一类丢失更新
A事务撤销时,把已经提交的B事务的更新数据覆盖了。例如: 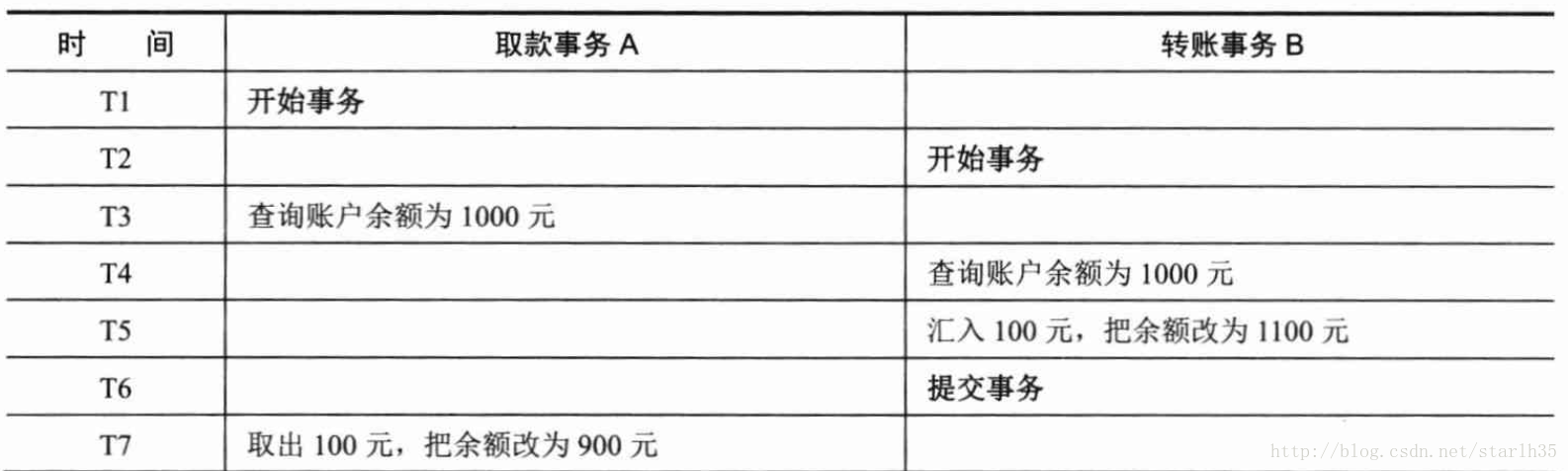
这时候取款事务A撤销事务,余额恢复为1000,这就丢失了更新。
6、第二类丢失更新
A事务覆盖B事务已经提交的数据,造成B事务所做的操作丢失 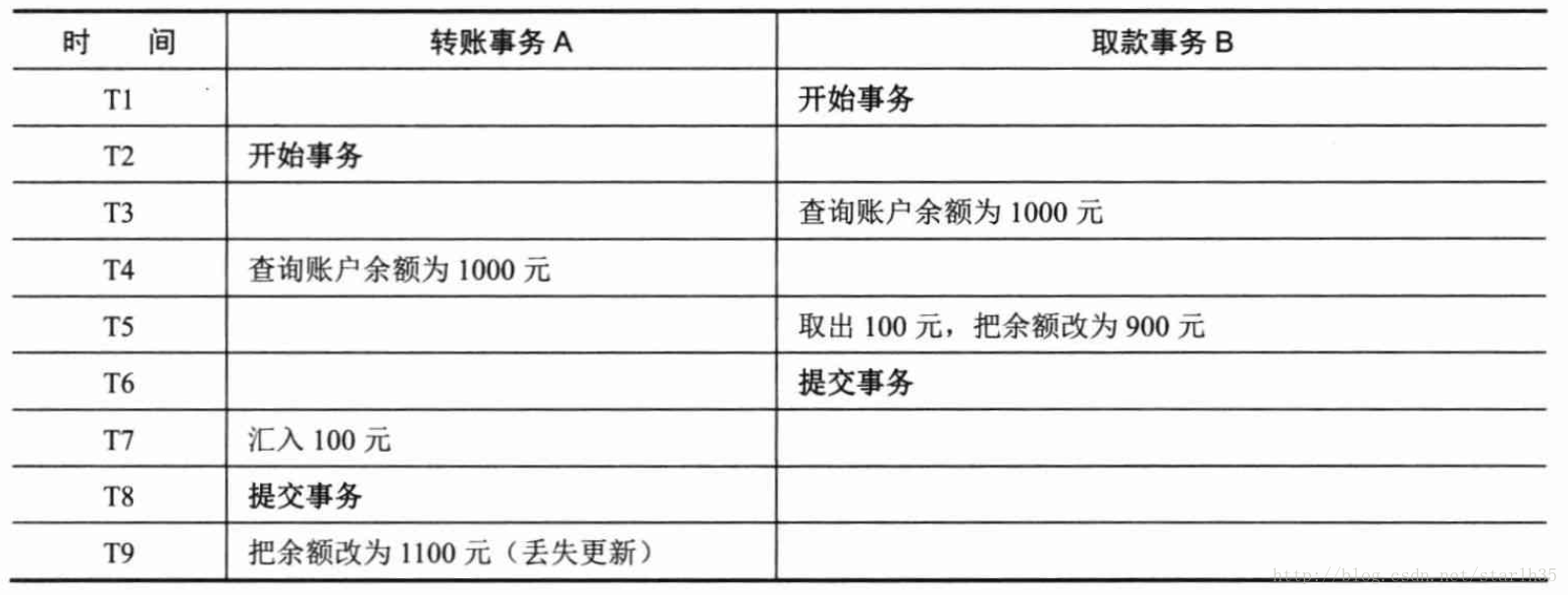
什么是MVCC?
MVCC的全称是“多版本并发控制”。这项技术使得InnoDB的事务隔离级别下执行一致性读操作有了保证,换言之,就是为了查询一些正在被另一个事务更新的行,并且可以看到它们被更新之前的值。这是一个可以用来增强并发性的强大的技术,因为这样的一来的话查询就不用等待另一个事务释放锁。这项技术在数据库领域并不是普遍使用的。一些其它的数据库产品,以及mysql其它的存储引擎并不支持它。
在MySQL的众多存储引擎中,只有InnoDB支持事务,所有这里说的事务隔离级别指的是InnoDB下的事务隔离级别。
读未提交:一个事务可以读取到另一个事务未提交的修改。这会带来脏读、幻读、不可重复读问题。(基本没用)
读已提交:一个事务只能读取另一个事务已经提交的修改。其避免了脏读,但仍然存在不可重复读和幻读问题。
可重复读:同一个事务中多次读取相同的数据返回的结果是一样的。其避免了脏读和不可重复读问题,但幻读依然存在。
串行化:事务串行执行。避免了以上所有问题。
以上是SQL-92标准中定义的四种隔离级别。在MySQL中,默认的隔离级别是REPEATABLE-READ(可重复读),并且解决了幻读问题。简单的来说,mysql的默认隔离级别解决了脏读、不可重复读问题。
不可重复读重点在于update和delete,而幻读的重点在于insert。
在Mysql中MVCC是在Innodb存储引擎中得到支持的,Innodb为每行记录都实现了三个隐藏字段:
6字节的事务ID(DB_TRX_ID )
7字节的回滚指针(DB_ROLL_PTR)
隐藏的ID(DB_ROW_ID)
6字节的事物ID用来标识该行所述的事务,7字节的回滚指针需要了解下Innodb的事务模型。
事务ID
事务ID是一个递增的整数,唯一的标识一个事务。ID的大小可以用来表示事务的串行化顺序,用于事务可见性的判断。
多版本存储
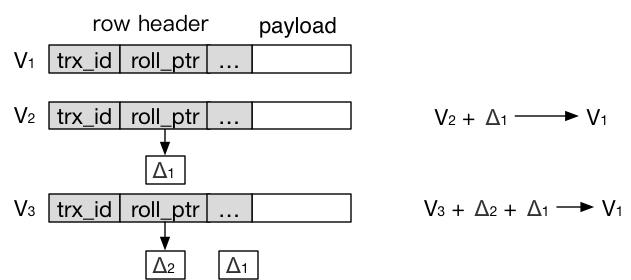
MySQL InnoDB实现了多版本并发控制(MVCC),在多版本存储上,MySQL采用从新到旧(Newest To Oldest)的版本链。B+Tree叶结点上,始终存储的是最新的数据(可能是还未提交的数据)。而旧版本数据,通过UNDO记录(做DELTA)存储在回滚段(Rollback Segment)里。每一条记录都会维护一个ROW HEADER元信息,存储有创建这条记录的事务ID,一个指向UNDO记录的指针。通过最新记录和UNDO信息,可以还原出旧版本的记录。
如下图, V1被一个事务更新为V2,V2被另一个事务更新为V3,Δ1存储V1到V2的更新,Δ2存储V2到V3的更新。此时,如果一个事条定位到B+Tree叶子节点的记录V3,则通过V3+Δ2可以还原出V2,通过V3+Δ2+Δ1可以还原出V1。
ReadView (或者可以称之为Snapshot)
ReadView是某一个时间点,事务执行状态的一个快照,可以用来判断事务的可见性。ReadView的基本结构如下:
ReadView {
creator_trx_id
low_limit_id
up_limit_id
ids
...
}creator_trx_id 创建这个ReadView的事务ID
low_limit_id 所有事务ID大于或等于low_limit_id对当前事务都不可见
up_limit_id 所有事务ID严格小于up_limit_id的事务对当前事务可见
ids 未提交的事务ID列表
可见性的判断
事务通过用当前事务(或语句,取决于隔离级别)的RaadView来判断一个事务id的操作是否对当前事务可见。判断可见性的伪代码如下:
IsVisible(trx_id)
if (trx_id == creator_trx_id) // 当前事务
return true;
else if (trx_id < up_limit_id) // ReadView创建时, 事务已提交
return true;
else if (trx_id >= low_limit_id) // ReadView创建时,事务还未被创建
return false;
else if (trx_id is in m_ids) // ReadView创建时,事务正在执行,但未提交
return false
else // ReadView创建时, 事务已提交
return true;不同隔离级别的实现
可串行化(Serializable)
在可串行化级别上,MySQL执行S2PL并发控制协议, 一阶段申请,一阶段释放。读写都要加锁。
可重复读(Repeatable Read)
可重复读是MySQL默认的隔离级别,理论上说应该称作快照(Snapshot)隔离级别。读不加锁,只有写才加锁,读写互不阻塞,并发度相对于可串行化级别要高,但会有Write Skew异常。
事务在开始时创建一个ReadView,当读一条记录时,会遍历版本链表,通过当前事务的ReadView判断可见性,找到第一个对当前事务可见的版本,读这个版本。
对于写操作,包括Locking Read(SELECT ... FOR UPDATE), UPDATE, DELETE,需要加写锁。根据谓词条件上索引使用情形,锁定有不同的方式:
1)有索引:
对于索引上有唯一约束且为等值条件的情形,不用GAP LOCK,只锁定索引记录。对于其它情形,使用GAP LOCK,相当于谓词锁。
2)没有索引:
由于MySQL没有实现通用的谓词锁,这时就相当于锁全表。
需要特殊说明的是,MySQL在可重复读级别对于更新冲突的处理有点特殊。MySQL支持Write Committed,可以更新在事务执行期间提交的记录。这点和PostgreSQL不同,PostgreSQL发生更新冲突要回滚。MySQL这个设计,减小了回滚率,但导致在可重复读级别下,并发的写入可能会发生异常。比如下面的例子,两个并行的事务执行后,发生了更新丢失异常(从上到下表示执行顺序,SQL仅用于说明这个问题,无实际意义,改写SQL可以规避这个问题)
Transaction T1 | Transaction T2
start transaction; |
select v into @x from t where k = 1; | start transaction;
| select v into @x from t where k = 1;
| update t set v = @x*10 where k = 1;
| commit;
update t set v = @x*10 where k = 1; |
commit; |T1,T2执行前:
mysql> select * from t;
+---+------+
| k | v |
+---+------+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
+---+------+ T1,T2执行后:
mysql> select * from t;
+---+------+
| k | v |
+---+------+
| 1 | 10 |
| 2 | 2 |
| 3 | 3 |
+---+------+读已提交(Read Committed)
MySQL的读已提交实际是语句级别快照。
与可重复读级别主要有两点不同:
1)获得ReadView的时机。每个语句开始执行时,获得ReadView,可见性判断是基于语句级别的ReadView。读的策略与可重复读类似。
2)写锁的使用方式。这里不需要GAP LOCK,只使用记录锁。并且事务只持有被UPDATE/DELETE记录的写锁(可重复读需要保留全部写锁直到事务结束,而读已提交只保留真正更改的)。
读未提交(Read Uncommitted)
读最新的数据,不管这条记录是不是已提交。不会遍历版本链,少了查找可见的版本的步骤。这样可能会导致脏读。
对写仍需要锁定,策略和读已提交类似,避免脏写。