【记录爬虫实战过程】入门学习·详细过程·爬取天气信息并通过pyecharts进行可视化展示2
前言
主要内容:
爬取某城市天气信息,将一整年里每月份的各种天气出现次数以可视化形式展现出来
跟着b站教学视频做的
主要是提供自己初步学习爬虫的过程,为他人做个参考
准备:
用的vscode写的,没有特殊要求,如何安装库也有详细方法介绍
代码过程很详细,应该都能看懂,不需要大量知识储备。但是每个函数对应的详细讲解还是要靠自己了解,本文没有展开细讲
正文
这是文章的第一部分,讲了数据爬取和数据处理部分,并且以CSV形式进行了存储,接下来将数据进行可视化展示
第二部分:数据可视化
新建立了一个文件 data_show.py
1.导入要用的包
需要先导入pandas和pyecharts包,具体导入过程可以参考这篇文章在vscode环境里导入python库
#需要先导入pandas和pyecharts包
import pandas as pd #pandas主要用于数据分析
#可视化
from pyecharts import options as opts #导入配置项
from pyecharts.charts import Pie,Bar,Timeline #导入图形项
2.读取CSV数据
读取CSV数据存入df
视频里面用的是’gb18030’解码方式,但是我解码出来是乱码,后来试了一下’utf-8’解出来就可以了,这两种哪种可以就用哪种
还有一种解码是’gbk’,因为’gb18030’包含’gbk’,所以使用’gb18030’更好
#读取数据
#df=pd.read_csv('weather.csv',encoding='gb18030') # 可以使用'gb18030'或者‘utf-8’,哪个能跑出来结果就用哪个,其中gb18030范围比gbk大点
df=pd.read_csv('weather.csv',encoding='utf-8')
#测试
#print(df['日期'])
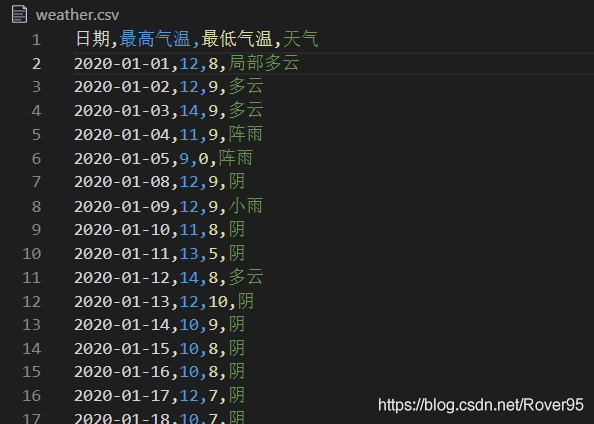
这是CSV文件最终呈现效果
(我在vscode里面装了一个Rainbow CSV插件,让CSV里面每列数据颜色不一样,方便查看)
3.处理数据
3.1. 日期数据
将string字符串类型的日期数据转换成datetime日期格式的数据
用了匿名函数lambda,比较简单,自行学习
df['日期']=df['日期'].apply(lambda x:pd.to_datetime(x))
3.2. 月份数据
因为要根据每个月的数据进行整合,所以用groupby() 函数分组,把数据存入df_agg
df['month']=df['日期'].dt.month #取出月份这个数据,方便后面进行统计
df_agg=df.groupby(['month','天气']).size()
但是这样的分组后索引是不连续的,不能得到每个天气的对应索引,只能得到每个月份的索引
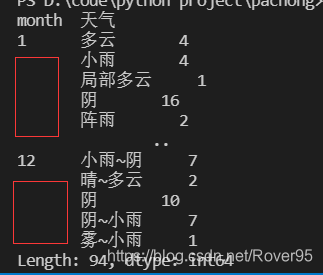
于是需要用reset_index()进行重新排序,得到连续的索引,代码如下
df['month']=df['日期'].dt.month #取出月份这个数据,方便后面进行统计
#print(df['month'])
#返回一个聚合对象,可以对结果进行分组和统计
#df_agg=df.groupby(['month','天气']).size()
#因为groupby后索引是不连续的,需要用reset_index()进行重新排序,得到连续的索引
df_agg=df.groupby(['month','天气']).size().reset_index()
#print(df_agg)
得到的结果:

3.3. 设置列名
设置df_agg列名为’month’,‘weather’,‘count’,这个时候再打印出来的结果就有了变化
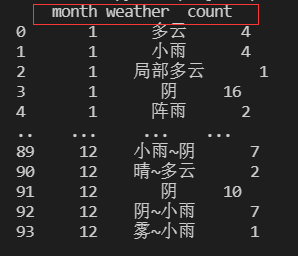
#设置df_agg列名
df_agg.columns=['month','weather','count']
print(df_agg)
3.4. 取出可视化要用的数据
要取出每个月份的’weather’,'count’两种数据,根据’count’的值进行排列,并且将最后得到的数据转变成列表
现在进行测试,以一月份为例
#ascending=False代表从大到小排列,若为true则代表从小到大排列
#末尾的斜杠代表换一行
data=df_agg[df_agg['month']==1][['weather','count']]\
.sort_values(by='count',ascending=False).values.tolist()
print(data)
#得到的数据
""" [['阴', 16], ['多云', 4], ['小雨', 4], ['阵雨', 2], ['局部多云', 1], ['零散阵雨', 1], ['雾', 1]] """
好,现在仿照这个代码来得到每个月的数据
data=(df_agg[df_agg['month']==month][['weather','count']]
.sort_values(by='count',ascending=True)
.values.tolist()
) #注意!是小括号!
3.5. 将数据可视化
3.5.1 设置时间间隔
""" 画图 """
#时间序列
timeline=Timeline()
#播放设置:设置时间间隔:1s=1000ms
timeline.add_schema(play_interval=1000) #设置时间间隔是以毫秒ms为单位
3.5.2 画图
for month in df_agg['month'].unique():
data=(df_agg[df_agg['month']==month][['weather','count']]
.sort_values(by='count',ascending=True)
.values.tolist()
) #注意!是小括号!
#绘制柱状图
bar=Bar()
# x轴数据:天气名称
bar.add_xaxis([x[0] for x in data]) #列表推导式
# y轴数据:出现次数
#第一个参数为图例,此处不需要但又不能为空,所以用空格代替
bar.add_yaxis('',[x[1] for x in data])
#让柱状图横着放
bar.reversal_axis()
#将出现的次数放在柱状图右边
bar.set_series_opts(label_opts=opts.LabelOpts(position='right'))
#设置下图表的名称
bar.set_global_opts(title_opts=opts.TitleOpts(title='重庆2020年每月天气变化'))
#将设置好的bar对象设置到时间轮播图当中,并且标签选择月份 格式:'月份'+'月':12月..
timeline.add(bar,f'{month}月')
3.5.3 保存为html文件
#将设置好的图表保存为html文件
timeline.render('weather.html')
在vscode里面下载一个open in browser插件,再右键点击html文件,选择在默认浏览器还是其他浏览器打开,就可以运行了
效果是一个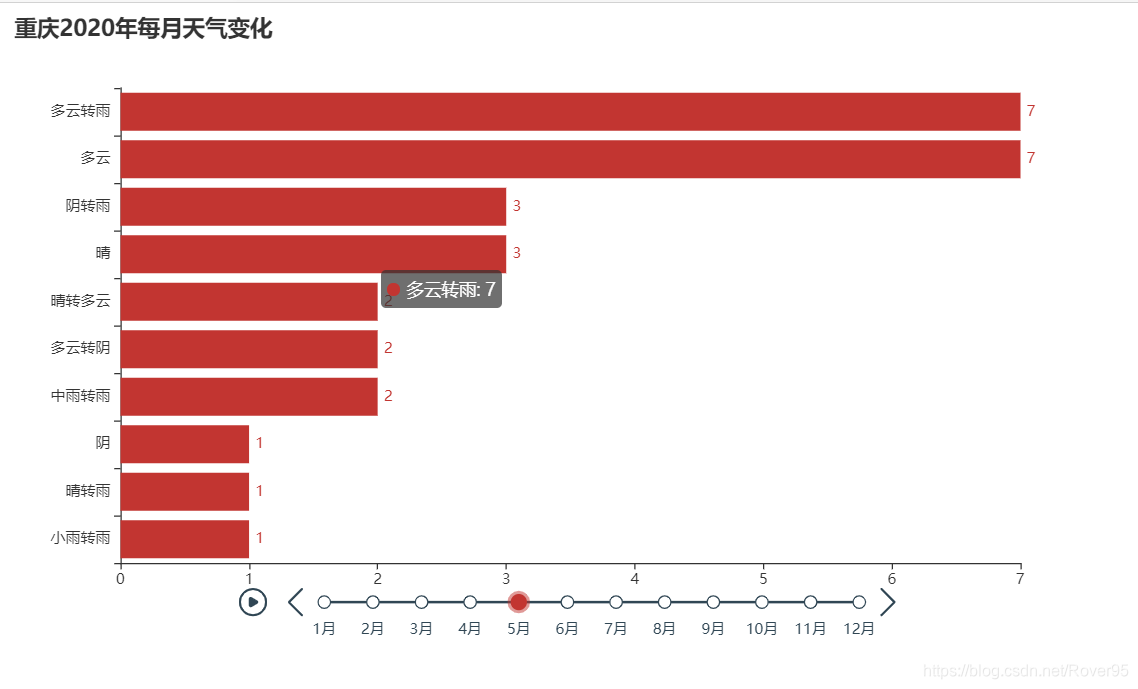
完整代码
最后,以下是所有代码
#需要先导入pandas和pyecharts包
import pandas as pd #pandas主要用于数据分析
#可视化
from pyecharts import options as opts #导入配置项
from pyecharts.charts import Pie,Bar,Timeline #导入图形项
#读取数据
#df=pd.read_csv('weather.csv',encoding='gb18030') # 可以使用'gb18030'或者‘utf-8’,哪个能跑出来结果就用哪个,其中gb18030范围比gbk大点
df=pd.read_csv('weather.csv',encoding='utf-8')
#print(df['日期']) #测试
#将字符串类型的日期数据转换成日期格式的数据
#使用匿名函数lambda
df['日期']=df['日期'].apply(lambda x:pd.to_datetime(x))
#测试数据类型变成了datetime
#print(df['日期'])
df['month']=df['日期'].dt.month #取出月份这个数据,方便后面进行统计
#print(df['month'])
#返回一个聚合对象,可以对结果进行分组和统计
# df_agg=df.groupby(['month','天气']).size()
#因为groupby后索引是不连续的,需要用reset_index()进行重新排序,得到连续的索引
df_agg=df.groupby(['month','天气']).size().reset_index()
# print(df_agg)
#设置df_agg列名
df_agg.columns=['month','weather','count']
# print(df_agg)
#取出可视化要用的数据
#末尾的斜杠代表换一行
#取出每个月份的'weather','count'两种数据,根据'count'的值进行排列
#ascending=False代表从大到小排列,若为true则代表从小到大排列
#将最后得到的数据转变成列表
# 测试,以一月份为例
# data=df_agg[df_agg['month']==1][['weather','count']]\
# .sort_values(by='count',ascending=False).values.tolist()
# print(data)
""" [['阴', 16], ['多云', 4], ['小雨', 4], ['阵雨', 2], ['局部多云', 1], ['零散阵雨', 1], ['雾', 1]] """
""" 画图 """
#时间序列
timeline=Timeline()
#播放设置:设置时间间隔:1s=1000ms
timeline.add_schema(play_interval=1000) #设置时间间隔是以毫秒ms为单位
for month in df_agg['month'].unique():
data=(df_agg[df_agg['month']==month][['weather','count']]
.sort_values(by='count',ascending=True)
.values.tolist()
) #注意!是小括号!
#绘制柱状图
bar=Bar()
# x轴数据:天气名称
bar.add_xaxis([x[0] for x in data]) #列表推导式
# y轴数据:出现次数
#第一个参数为图例,此处不需要但又不能为空,所以用空格代替
bar.add_yaxis('',[x[1] for x in data])
#让柱状图横着放
bar.reversal_axis()
#将出现的次数放在柱状图右边
bar.set_series_opts(label_opts=opts.LabelOpts(position='right'))
#设置下图表的名称
bar.set_global_opts(title_opts=opts.TitleOpts(title='重庆2020年每月天气变化'))
#将设置好的bar对象设置到时间轮播图当中,并且标签选择月份 格式:'月份'+'月':12月..
timeline.add(bar,f'{month}月')
#将设置好的图表保存为html文件
timeline.render('weather.html')
遇到的问题
1.报错urllib.error.URLError:urlopen error [WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败
可能原因:断网了,或者导入库时出错 from urllib.request import urlopen
2.一些解码问题,各种解码形式我也没太明白,反正我把我遇到的都记录下来了,一种不行就换另一种就好
3.刚接触xpath,不太熟悉,之前推荐过的b站链接学习xpath我觉得对于简单了解够用了,差不多十分钟就看懂了
其他的问题记不太清楚了,想起来再完善吧