selenium-XPATH以及CSS的便捷使用
这里是清安,我们见过元素定位,也讲过一篇,元素定位不到的文章,那么本章,我们就来详细说说,元素定位的那些利器。一起看看元素定位的另一些情况。
目录
css 和 xpath 定位各自优缺点?
xpath :是 XML 文档中查找结点的语法,换句话就是通过元素的路径来查找这个元素。他分绝对路径和相对路径,xpath 比较强大,所有元素它都能定位到,但是他定位相对比较慢,
css 选择器 :在性能上更优,运行速度更快,语法上更简洁。
Xpath能通过子元素搜索父元素, Css无法实现,Css只能从父级往下级搜索。
Xpath能按文本搜索元素,Css不能。
Css比Xpath更简单易读,执行速度更快
篇外话
如何定位一组元素?
以百度为例:
from selenium import webdriver
fox = webdriver.Firefox()
fox.get('https://baidu.com')
s = fox.find_elements_by_class_name('mnav')
for i in s:
print(i.get_attribute('href'))
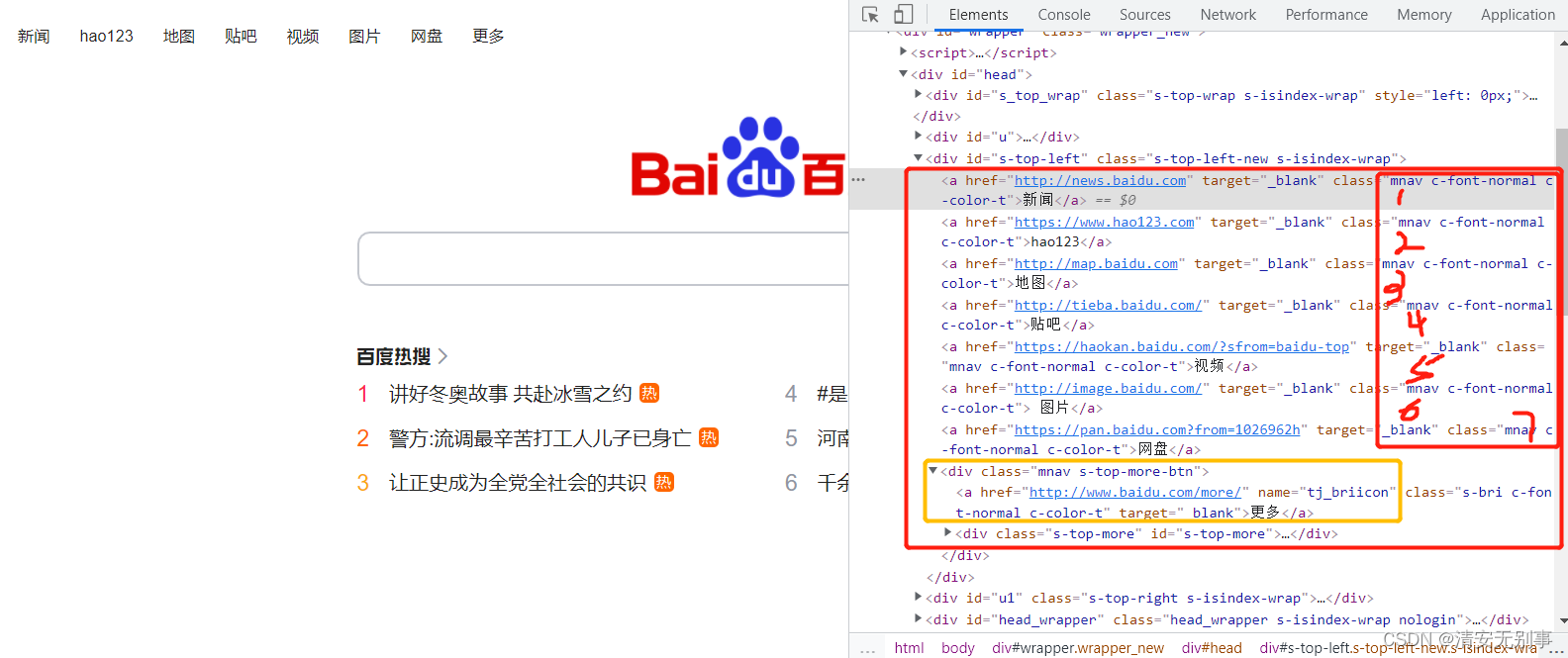
fox.quit()看图,我标注了数字,为什么要标注数字,跑了看结果就知道了。
http://news.baidu.com/
https://www.hao123.com/
http://map.baidu.com/
http://tieba.baidu.com/
https://haokan.baidu.com/?sfrom=baidu-top
http://image.baidu.com/
https://pan.baidu.com/?from=1026962h
None得出的结果是这样的。为什么会有一个None值呢,看到了我标注的黄色框了吗,元素也是mnav开头的,这里是模糊匹配,所以黄色框中的div也输出了,它又没有href,所以为None。
.get_attribute('href')获取元素的给定属性或属性,它将返回具有相同名称的属性的值,我需要获取href属性对应的值,所以说,输出了一个个链接。
如何定位父子/兄弟/相邻节点的定位元素?
这里做了解就好
父->子
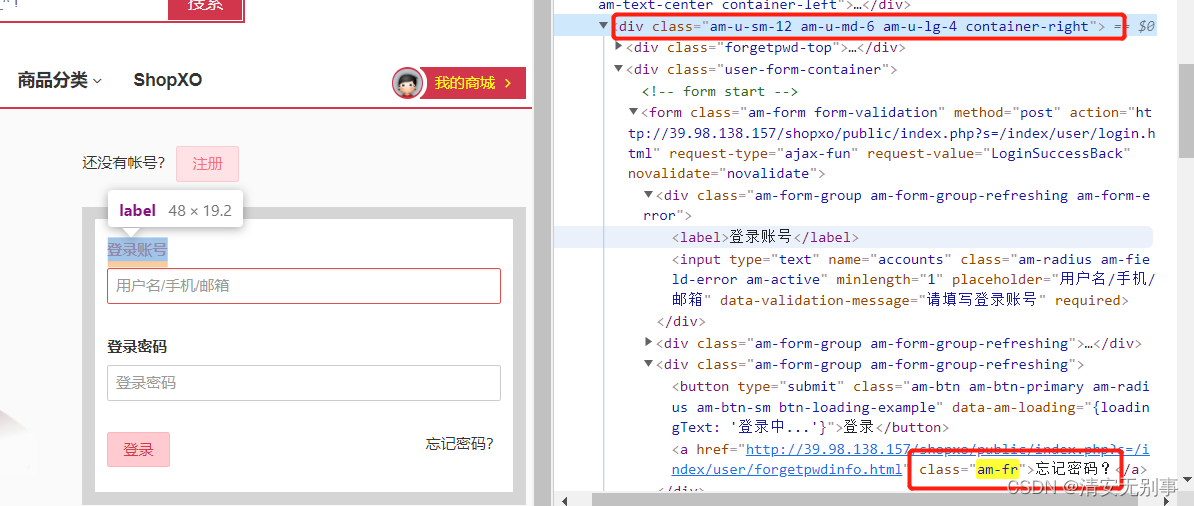
串联查找,这一项可以理解为父级元素的基础上直接查找所需的子元素。当元素定位不到的时候可以尝试此方法,不过比较的笨拙,但是实在。
from selenium import webdriver
fox = webdriver.Firefox()
fox.get('http://39.98.138.157/shopxo/public/index.php?s=/index/user/logininfo.html')
ele = fox.find_element_by_class_name('am-u-sm-12.am-u-md-6.am-u-lg-4.container-right').find_element_by_link_text('忘记密码?').text
print(ele)
fox.quit()
子->父
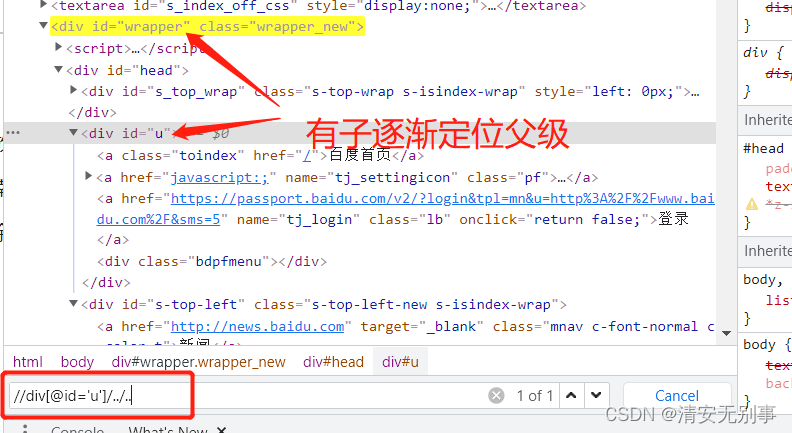
find_element_by_xpath(‘//div[@id=’u’]/../..’) 这里就是子元素先定位到父元素再定位到父元素的父元素
如何二次定位元素?
这里的二次定位其实就是串联查找,所以,这里看上面的父级>子元素的查找即可
如何去定位页面上动态加载动态变化的元素?
这里介绍三种方法,解决你对定位的困扰。
contains(a, b) 如果 a 中含有字符串 b,则返回 true,否则返回 false(包含什么)
starts-with(a, b) 如果 a 是以字符串 b 开头,返回 true,否则返回 false(以什么开始)
ends-with(a, b) 如果 a 是以字符串 b 结尾,返回 true,否则返回 false(以什么结束)
driver.find_element_by_xpath ("//div[contains(@id, 'accounts')]")
driver.find_element_by_xpath ("//div[starts-with(@id, 'accounts')]")
driver.find_element_by_xpath ("//div[ends-with(@id, 'accounts')]") # 在2.0版本可以这里就不一一举例了。我们直接看正文。
正文
xpath实用的元素定位方法
# / 从当前节点选取直接子节点
# // 从当前节点选取子孙节点
# .选取当前节点
# …选取当前节点的父节点
# @选取属性
# *代表所有
import time
from selenium import webdriver
fox = webdriver.Firefox()
fox.get('http://shop.aircheng.com/')
# 账号:nswe 密码:111111
"""匹配文本为登录的元素"""
fox.find_element_by_xpath("//*[text()='登录']").click()
time.sleep(3)
# *为匹配任何元素节点,选取name=''的属性 <元素 属性='值'>内容</元素>
# fox.find_element_by_xpath("//*[@name='login_info']").send_keys('nswe')
"""选取所有 input 元素,且这些元素拥有值为 alt 的 填写用户名或邮箱 属性。"""
fox.find_element_by_xpath('//input[@alt="填写用户名或邮箱"]').send_keys('nswe')
"""选取所有 input 元素,且这些元素拥有值为 type 的 password 属性。"""
fox.find_element_by_xpath('//input[@type="password"]').send_keys('111111')
# 使用任意属性值匹配元素
fox.find_element_by_xpath("//input[@*='remember']").click()
# 点击登录。使用部分属性值定位,以某字符串开头,可以接and、or多属性定位
fox.find_element_by_xpath("//input[starts-with(@class,'input') and @value='登录']").click()上述实例中,我已经列出了实用的xpath定位写法:
//*[text()='登录'] :匹配任何节点text,也就是文本值为登录的属性值
//*[@name='login_info'] : 匹配任何节点,属性name等于login_info的值
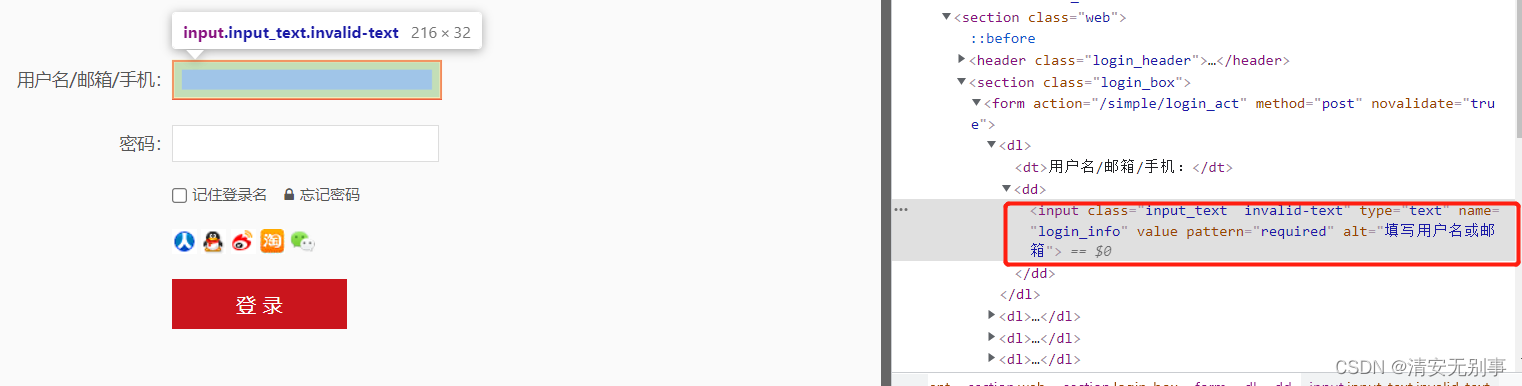
//input[@alt="填写用户名或邮箱"] :通俗一点理解就是寻找input标签中alt属性为填写用户名货邮箱的值。此处还是很方便的,只要有属性,且唯一,就能定位到。
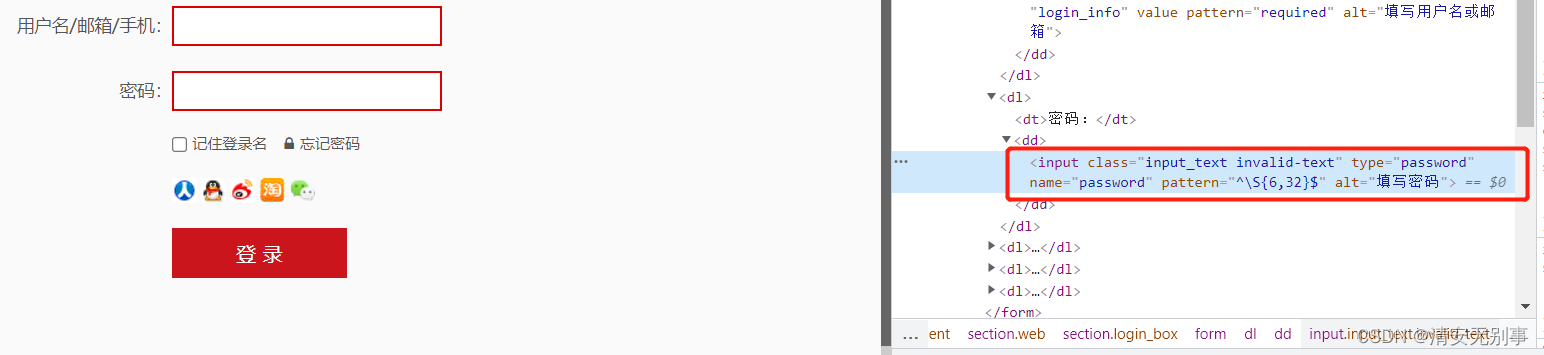
//input[@type="password"]同上述所说一致。
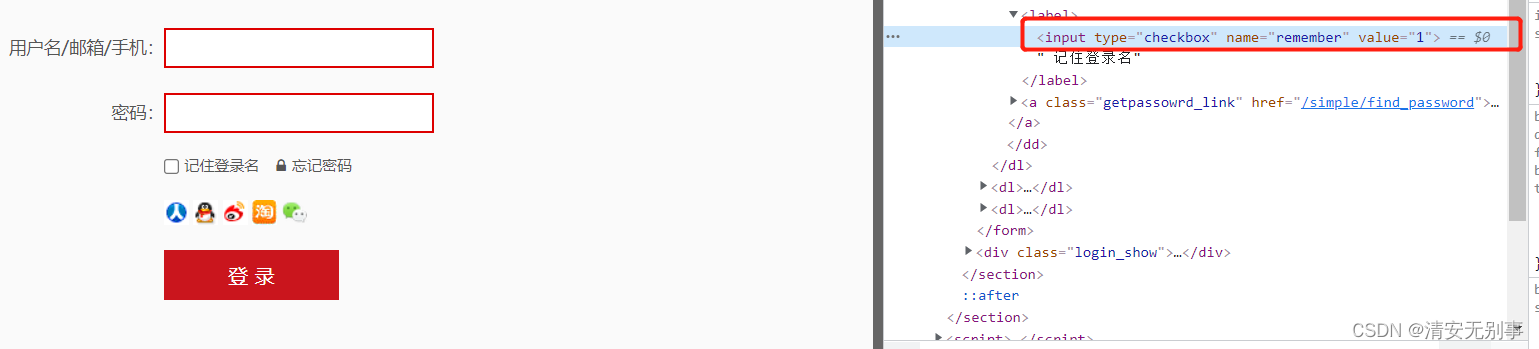
//input[@*='remember'] :这个就是值匹配值为remember的属性。此方法如果页面也远较多的且类型的情况下还是不能够非常准确的定位到的
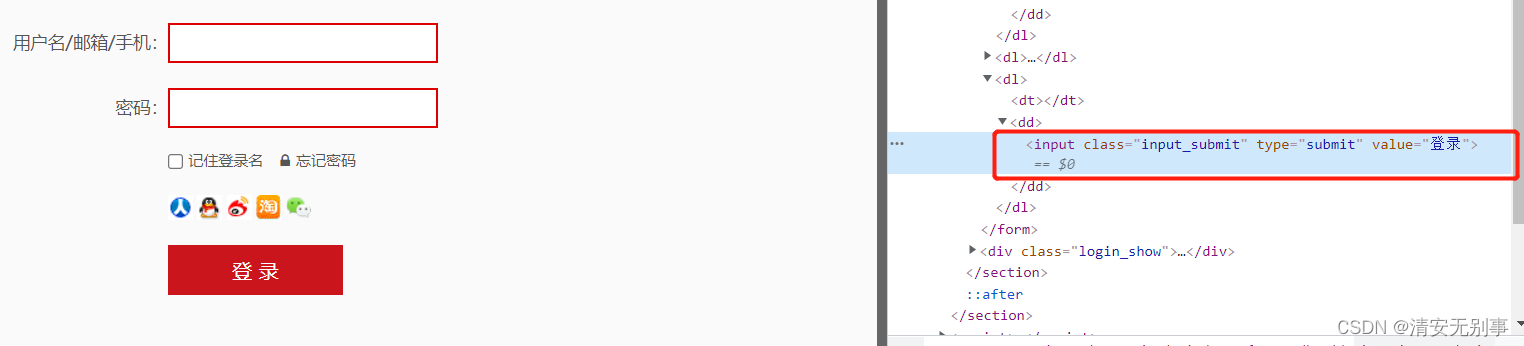
//input[starts-with(@class,'input') and @value='登录'] :一个登录按钮我为什么要写这么复杂呢,明明可以直接用class属性跟其他的一些属性。这里结合了starts-with(上面有讲),你也可以用其他的一些属性进行联合定位,这种情况在页面元素多,且耦合程度高的情况下还是比较适用的。
CSS实用的元素定位方法
import time
from selenium import webdriver
fox = webdriver.Firefox()
fox.get('http://shop.aircheng.com/')
# 账号:nswe 密码:111111
"""匹配文本为登录的元素"""
fox.find_element_by_xpath("//*[text()='登录']").click()
time.sleep(3)
# input#kw根据标签定位到id=kw
# fox.find_element_by_css_selector("input#kw")
# css 通过指定元素中属性值来定位元素 也可以div>form>input[name='action']
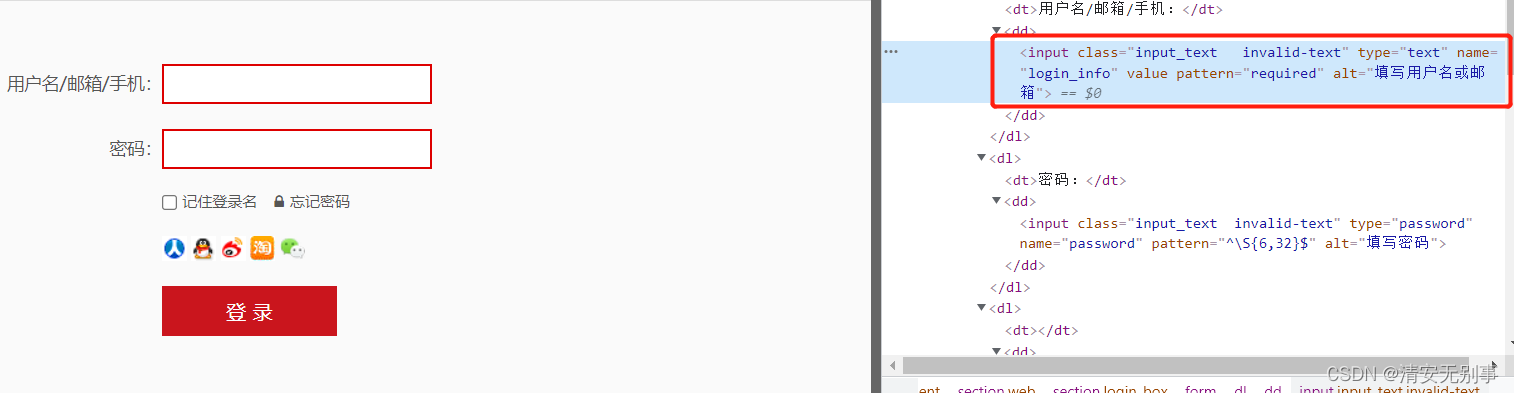
fox.find_element_by_css_selector("input[name='login_info']").send_keys('nswe')
# css 通过指定元素中属性值进行多属性定位元素
fox.find_element_by_css_selector("input[name='login_info'][type='text']").send_keys('nswe')仔细看看其实还是有一些类似的地方的。
总结
那么再来看看所整理的表格,受用。
| 定位 | xpath | css | 比较 |
| 所有元素 | //* | * | 选取所有元素 |
| 所有div | //div | div | 选取所有div节点 |
| id | //div[@id=‘it’] | div#it | 选取id值为’it’的元素 |
| class | //div[@class=‘cs’] | div.cs | 选取class值为’cs’的元素 |
| 单属性 | //div[@title=‘ti’] | div[title=ti] | 选取title属性值为’ti’的元素 |
| 多属性 | //div[@title=‘ti’][@name=‘na’] | div[title=ti][name=na] | 选取title属性值为’ti’,且name属性值为’na’的元素 |
| 函数 | //a[contains(@href,‘hello’)];a//[starts-with(@href,‘py’)] | a[href~=hello];a[href^=py] | href值包含’hello’的a元素;href值以’py’开头的a元素 |
| 后代元素 | //div[@id=‘it’]//h1 | div#it h1 | 选取id值为’it’的div元素的所有后代h1元素 |
| 索引 | //li[3] | li:nth(3) | 选取第三个li元素 |
温馨提示,别被表格中的div所限制,大胆发挥,多多实践。