基于TensorFlow的卷积神经网络的岩石图像分类识别(简易实践案例)
题目简述
今有砾岩(Conglomerate)、安山岩(Andesite)、石灰岩(Limestone)、石英岩(Quartzite)和花岗岩(Granite)5种岩石图片,每张图片的大小不一。试建立卷积神经模型,利用训练数据集进行训练,并对测试集进行分类识别。
 数据集百度云盘下载 https://pan.baidu.com/s/1Ok20EhvV9F0-JMyONrsnFA 解压码:t35r.
数据集百度云盘下载 https://pan.baidu.com/s/1Ok20EhvV9F0-JMyONrsnFA 解压码:t35r.
个人项目运行环境
- PyCharm 2017.1
- Python 3.8.6
- numpy 1.19.5
- TensorFlow 2.5.0
- scikit-learn 0.24.2
导入模块
import os
import numpy as np
from PIL import Image
from tensorflow.keras import layers,models
from sklearn.model_selection import train_test_split
数据处理
这里我们构造卷积神经网络模型所需要的输入数据和输出数据,其中输入数据为所有彩图数据。我所展示的样例共有300张图片,统一取图像中心点100×100像素,共有R、G、B三个通道,并对每个通道像素值归一化,彩色图片有3个通道(也可以使用OpenCV的函数查看自己使用图片的通道数),故所有彩图数据可以用一个四维数组来存储,其形态为 (300,100,100,3)。记为X。输出数据为岩石类型,依次为砾岩、安山岩、石灰岩、石英岩和花岗岩(不确定顺序,我也不能分清具体岩石是哪个类,按照图片的类别来分不同岩石),类型编号为0、1、2、3、4,记为Y。代码如下:
# 数据处理
def DataDispose(X,Y,ImgList):
for i in range(len(ImgList)):
# 读取第一张图片,img有R、G、B(三色)三个通道
img = Image.open(ImgPath + "\\" +ImgList[i])
# 分离R、G、B通道
sep = img.split()
# R 通道
R = np.array(sep[0])
# 注意中心点
row_1 = int(R.shape[0]/2) - 50
row_2 = int(R.shape[0]/2) + 50
con_1 = int(R.shape[1]/2) - 50
con_2 = int(R.shape[1]/2) + 50
R = R[row_1:row_2,con_1:con_2]
# G 通道
G = np.array(sep[1])
G = G[row_1:row_2,con_1:con_2]
# B 通道
B = np.array(sep[2])
B = B[row_1:row_2,con_1:con_2]
# 获取R、G、B通道即可,并归一化
X[i,:,:,0] = R/255
X[i,:,:,1] = G/255
X[i,:,:,2] = B/255
# 构造输出数据,岩石类别编号
S = ImgList[i]
I = S.find('_',0,len(S))
if int(S[:I]) == 1:
Y[i] = 0
elif int(S[:I]) == 2:
Y[i] = 1
elif int(S[:I]) == 3:
Y[i] = 2
elif int(S[:I]) == 4:
Y[i] = 3
else:
Y[i] = 4
# 对输入数据X和输出数据Y,按训练及80%,测试20%随机划分
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=4)
模型实现
模型实现,我们采用TensorFlow2之中的Keras模块下的堆叠模型,构建多层卷积神经网络识别模型,不同的是输入形态的设计。我们可以直接在第一个卷积网络设置其输入形态,他为3个通道的彩色图片数据,代码如下:
# 模型建立
def BuildModel(x_train, x_test, y_train, y_test,TrainingTimes):
model = models.Sequential()
# 第一个卷积层,卷积神经元个数为32,卷积核大小为3×,默认可省略
model.add(layers.Conv2D(32, (3, 3), strides=(1, 1), activation='relu', input_shape=(100, 100, 3)))
# 第一个池化层,2×2池化,步长为2,默认可缺省
model.add(layers.MaxPooling2D((2, 2), strides=2))
# 第二个卷积层和池化层
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
# 第三个卷积层和池化层
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
# 第四个卷积层
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
# 展平
model.add(layers.Flatten())
# 全连接层
model.add(layers.Dense(64, activation='relu'))
# 输出层
model.add(layers.Dense(5, activation='softmax'))
# 模型优化器、损失函数和评估方法,采用adam优化器、分类交叉熵函数和预测准确率
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 我们设定对训练集的迭代训练次数
model.fit(x_train, y_train, epochs=TrainingTimes)
model.evaluate(x_test, y_test, verbose=2)
# 获得预测结果概率矩阵
yy = model.predict(x_test)
# 获得最终预测结果,取概率最大的类标签
y1 = np.argmax(yy, axis=1)
# 预测结果与实际结果相减
r = y1 - y_test
# 计算预测准确率
rv = len(r[r == 0]) / len(r)
print("预测准确率:", rv)
结果分析
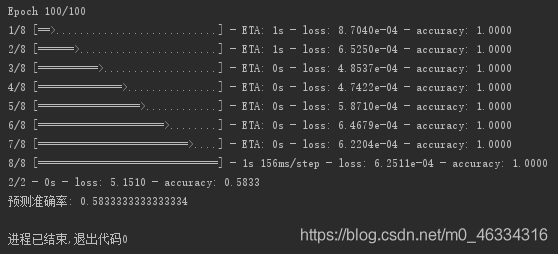 这是迭代测试100次的结果,测试数据集的准确率达到了0.58334。与使用模型的predict函数对测试数据集进行预测,其预测结果一致。
这是迭代测试100次的结果,测试数据集的准确率达到了0.58334。与使用模型的predict函数对测试数据集进行预测,其预测结果一致。
利用卷积神经网络识别模型,准确度要比特征值未乘系数的支持向量机模型要高得多。
完整代码
Python3完整代码
"""
-------------------------------------------------
作者:W.Lionel.Esaka
日期:2021-06-10
开发工具:PyCharm
基于TensorFlow2的岩石图片分类识别
-------------------------------------------------
"""
import os
import numpy as np
from PIL import Image
from tensorflow.keras import layers,models
from sklearn.model_selection import train_test_split
# 自定义模型训练次数
TrainingTimes = 10
# 训练集文件路径
ImgPath = "D:\\Self\\Python\\BigData\\data\\Rock"
# 文件夹所有图片文件名
ImgList = os.listdir(ImgPath)
# 定义输入数据
X = np.zeros((len(ImgList), 100, 100, 3))
# 定义输出数据
Y = np.zeros(len(ImgList))
for i in range(len(ImgList)):
# 读取第一张图片,img有R、G、B(三色)三个通道
img = Image.open(ImgPath + "\\" + ImgList[i])
# 分离R、G、B通道
sep = img.split()
# R 通道
R = np.array(sep[0])
# 注意中心点
row_1 = int(R.shape[0] / 2) - 50
row_2 = int(R.shape[0] / 2) + 50
con_1 = int(R.shape[1] / 2) - 50
con_2 = int(R.shape[1] / 2) + 50
R = R[row_1:row_2, con_1:con_2]
# G 通道
G = np.array(sep[1])
G = G[row_1:row_2, con_1:con_2]
# B 通道
B = np.array(sep[2])
B = B[row_1:row_2, con_1:con_2]
# 获取R、G、B通道即可,并归一化
X[i, :, :, 0] = R / 255
X[i, :, :, 1] = G / 255
X[i, :, :, 2] = B / 255
# 构造输出数据,岩石类别编号
S = ImgList[i]
I = S.find('_', 0, len(S))
if int(S[:I]) == 1:
Y[i] = 0
elif int(S[:I]) == 2:
Y[i] = 1
elif int(S[:I]) == 3:
Y[i] = 2
elif int(S[:I]) == 4:
Y[i] = 3
else:
Y[i] = 4
# 对输入数据X和输出数据Y,按训练及80%,测试20%随机划分
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=4)
model = models.Sequential()
# 第一个卷积层,卷积神经元个数为32,卷积核大小为3×,默认可省略
model.add(layers.Conv2D(32, (3, 3), strides=(1, 1), activation='relu', input_shape=(100, 100, 3)))
# 第一个池化层,2×2池化,步长为2,默认可缺省
model.add(layers.MaxPooling2D((2, 2), strides=2))
# 第二个卷积层和池化层
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
# 第三个卷积层和池化层
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
# 第四个卷积层
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
# 展平
model.add(layers.Flatten())
# 全连接层
model.add(layers.Dense(64, activation='relu'))
# 输出层
model.add(layers.Dense(5, activation='softmax'))
# 模型优化器、损失函数和评估方法,采用adam优化器、分类交叉熵函数和预测准确率
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 我们设定对训练集的迭代训练次数
model.fit(x_train, y_train, epochs=TrainingTimes)
model.evaluate(x_test, y_test, verbose=2)
# 获得预测结果概率矩阵
yy = model.predict(x_test)
# 获得最终预测结果,取概率最大的类标签
y1 = np.argmax(yy, axis=1)
# 预测结果与实际结果相减
r = y1 - y_test
# 计算预测准确率
rv = len(r[r == 0]) / len(r)
print("预测准确率:", rv)