一项关于使用非参数检验分析进化算法行为的研究:2005年中欧委员会实参数优化特别会议的案例研究
一项关于使用非参数检验分析进化算法行为的研究:2005年中欧委员会实参数优化特别会议的案例研究
Abstract
摘要近年来,在进化算法领域,实验分析越来越受到人们的关注。值得注意的是,目前已有大量的论文分析并提出了不同类型的问题,如算法实验比较的基础、算法比较中不同方法的提出、算法比较中使用不同统计技术的建议等。在这篇论文中,我们重点研究了统计技术在分析进化算法在优化问题上的行为方面的应用。利用进化算法的实编码优化模型,研究了统计分析结果的必要条件。本研究采用单问题分析和多问题分析两种方法进行。结果表明,当我们处理多个问题的结果时,参数统计分析是不合适的。在多问题分析中,我们建议使用非参数统计检验,因为它们比参数统计检验的限制性更小,而且它们可以在结果的小样本中使用CEC’2005用非参数测试程序优化实参数专题会议。
筹备工作:2005年中央委员会特别会议设置
在本节中,我们将简要介绍CEC2005特别会议中比较的算法、测试功能和实验的特点。
2.1进化算法
在本节中,我们列举了在CEC“2005年特别会议”上提出的11种算法。如需详细了解每一项的描述和参数,请参阅各自的贡献。算法如下:BLX。GL50 (García-Martínez and Lozano 2005)、BLX-MA (Molina et al. 2005)、CoEVO(波伊克2005年),德(伦克嫩等人2005年),DMS-L-PSO(梁和苏甘塔尔)2005), EDA (Yuan and Gallagher 2005), G-CMA-ES (Auger and Hansen 2005a)K-PCX(辛哈等人2005年),L-CMA-ES(奥格和汉森2005b),L-萨德(基尔和Suganthan 2005), SPC-PNX (Ballester et al. 2005)。
2.2 测试函数
在下面的文章中,我们介绍了为2005年IEEE进化大会上组织的实参数优化特别会议设计的一组测试函数


所有函数都被替换了,以确保它们的最优值永远不会在搜索空间的中心被找到。在两个函数。此外。在初始化范围内找不到optima,搜索域不受限制(最优不在初始化范围内)
2.3 实验的特点
这些实验是按照与竞赛相关的文件中的说明进行的。主要特点有:
- 对于每个测试函数,每个算法运行25次,并计算出总体中最优个体的平均误差。
- 我们将使用维数D = 10的研究,算法对适应度函数进行10万次评估在上述竞赛中,还进行了D30和D50尺寸的实验
- 每次运行都在获得的错误小于10-8时停止。或者达到最大次数的计算。
3 .研究参数试验安全使用所需条件
在本节中,我们将描述和分析安全使用参数测试必须满足的条件(第3.1节)。为此,我们收集了考虑维数D= 10的25个函数中,采用BLX-MA和BLX-GL50算法得到的全部结果。有了它们,我们将首先在单个问题分析(见3.2节)中,对每个函数的结果的完整样本分析所指示的条件。最后。我们将考虑每个函数的平均结果,以合成两种算法的每个结果样本。有了这两个样本,我们将再次检查在多问题方案中安全使用参数测试所需的条件(见第3.3节)。
3.1参数试验安全使用的条件。
在Sheskin(2003年)中,参数检验和非参数检验之间的区别是基于将要分析的数据所代表的测量水平。这样,参数化测试使用由实值组成的数据。后者并不意味着当我们总是处理这种类型的数据时,我们应该使用参数测试。对于参数检验的安全使用,还有其他一些初始假设。不满足这些条件可能会使统计分析失去可信性。为了使用参数测试,必须检查以下条件(Sheskin 2003;Zar 1999):
- 独立性:在统计学中,当一个事件的发生不改变另一个事件发生的概率时,两个事件是独立的。
- 正态性:当观察的行为符合正态分布或高斯分布,其平均值为u,方差为o时,观察就是正态的。对一个样本进行正态性检验可以表明观察数据中是否存在这种情况。我们将使用三种常态测试:
- Shapiro-WilkKolmogorov-Smirnov:将观测数据的累积分布与高斯分布的预期累积分布进行比较,得到基于两者差异的p值
- Shapiro-Wilk:它分析观察到的数据,计算对称程度和峰度(曲线的形状),然后计算与高斯分布的差异,从这些差异的平方和得到p值。
- D’agostino - pearson:它首先计算偏度和峰度,以量化分布在不对称和形状方面与高斯分布的距离。然后计算这些值与高斯分布的期望值之间的距离。并从这些差异的总和中计算出一个p值。
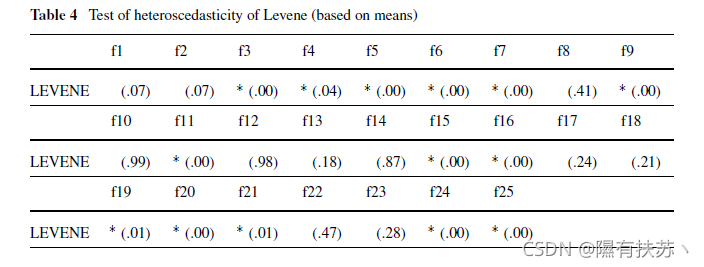
- 异方差性:这一性质表明存在违背方差相等假设的情况。Levene检验用于检验k个样本是否存在方差齐性(方差齐性)。当观测数据不满足正态性条件时,该检验结果比Bartlett检验更可靠。检查相同的属性。
在我们的例子中,很明显事件的独立性,因为它们是随机生成初始种子的算法的独立运行。下面我们将使用Kolmogorov-Smirnov进行正态性分析。ShapiroWilk和D’agostino - pearson检验对单问题和多问题分析,并用Levene检验进行异方差分析。
3.2关于单问题分析所需条件的研究
对每个函数运行25次BLX-GL50和BLX-MA算法得到的结果样本,我们可以应用统计检验来确定它们是否检验了正态性和同方差特性。我们以前已经看到,在这类实验中,独立性条件很容易满足。进行统计分析的运行次数可能较低,但这是中央委员会2005年特别会议的要求本节中使用的所有测试将获得相关的p值,它表示样本结果相对于正态形状的不同程度。因此,低p值表示非正态分布。在本研究中,我们将考虑显著性水平a =0.05,因此p值大于a表示满足正态性条件。所有的计算都通过SPSS统计软件包进行。表1显示了结果,符号“*”表示不满足正规性,括号中是p值。表2显示了应用测试的结果:
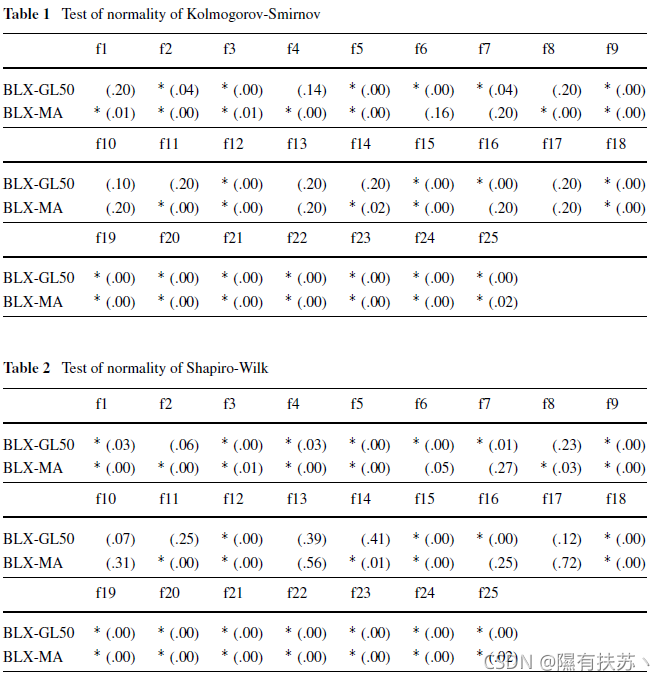
表3为D’agostino - pearson检验结果。
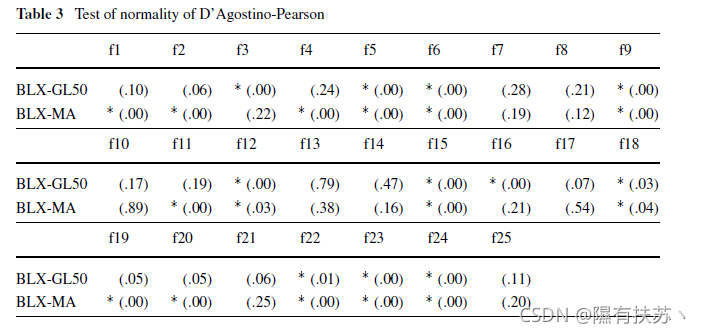
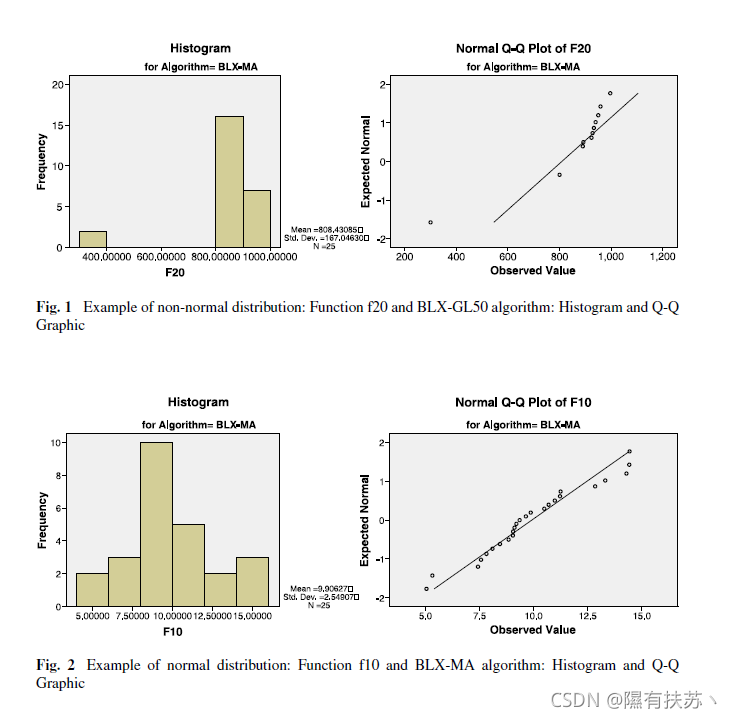
除了这个一般的研究之外,我们还展示了三种情况下的样本分布,目的是说明正态检验获得不同结果的有代表性的情况。
从图1到图3,显示了直方图和Q-Q图的不同图形表示示例。直方图通过条形图来表示一个统计变量,因此每个条形图的面积与所表示值的频率成正比。Q-Q图表示观察到的四分位数和正态分布的四分位数之间的冲突。
在图1中,我们可以观察到一个异常性质清晰呈现的一般情况。相反,图2是一个正态分布的样本的说明,采用的三个正态检验验证了这一事实。最后,图3显示了一个特殊情况,结果的样本和正态分布之间的相似性,并不是由所有的正态性来证实的。
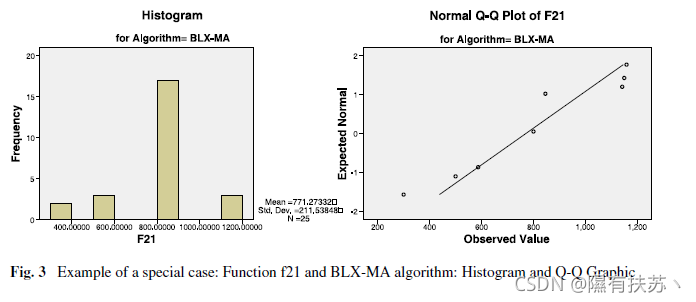
在这种情况下,一个正态性测试可能比另一个更好,这取决于数据类型、领带数量或收集的结果数量。因为这个事实。我们使用了三个众所周知的正态检验来研究正态条件。
根据问题选择最合适的正态检验超出了本文的范围。对研究同方差性属性,表4显示了通过应用列文的测试,结果,象征“表明分布的方差不同的算法的某些功能异同(我们reiect零hvpothesis在显著性水平= 0.05)显然,在这两种情况下,正态性和同方差条件的不满足是完美的。在大多数的功能。正态性条件在单问题分析中不能得到验证。同方差性也取决于所研究的算法的数目。因为它检验了所有总体样本方差之间的关系。
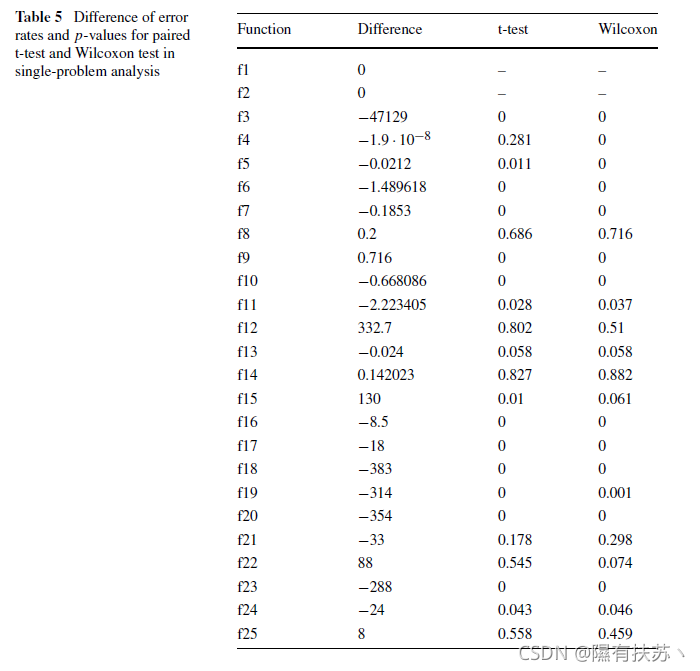
即使在这种情况下,我们只分析了两种算法的结果。在许多情况下,这一条件也没有得到满足。研究人员可能认为,这些条件的不满足不是获得充分结果的关键。通过使用相同的结果样本。我们将展示一个例子,其中一些结果提供了一个参数检验,配对t检验。与通过非参数检验得到的结果不一致。Wilcoxon的测试。表 5给出了每个函数中平均错误率之间的差异。算法BLX-GL50和BLX-MA(若为负,则最佳算法为BLX-GL50), p值通过配对t检验和Wilcoxon检验得到可以看出,配对t检验得到的p值与Wilcoxon检验得到的p值非常相似。然而,在三种情况下,它们是完全不同的。我们列举:
- 在函数f4。Wilcoxon检验认为两种算法的行为是不同的,而配对t检验则没有。这个例子非常适合一个不实用的例子。错误率的差异小于10-7,在实际意义上没有显著影响。
- 在函数f15中,情况与前一个相反。配对t检验得出显著差异有利于BLX-MA。这个结果可靠吗?由于f15的结果没有验证正态性条件(见表1、2、3),因此Wilcoxon检验的结果在理论上更可靠。
- 最后,在函数f22中,尽管Wilcoxon检验得到的p值大于显著性水平a =0.05,但两者的p值仍然非常不同。
在25个函数中,有3个在配对t检验和Wilcoxon检验的应用上存在可观察的差异。此外,在这三个函数中。安全使用参数统计的必要条件没有得到验证。原则上,我们可以建议在单问题分析中使用Wilcoxon的非参数检验。这是一种替代方法,但还有其他方法可以确保获得的结果对参数统计分析有效。
在单问题分析中,获得新的结果并不难。我们只需要再次运行算法来获得更大的样本结果。中心极限定理证实了许多同分布随机变量的和趋于正态分布。然而。执行的运行次数不能非常高,因为任何统计测试都有负影响大小。如果结果的样本太大,统计检验可以将不显著的差异检测为显著。为了控制规模效应,我们可以使用科恩指数d’:
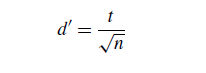
其中t为t检验统计量,n为收集的结果个数。如果d’接近0.5,那么差异是显著的。d '值低于0.25表示微不足道的差异,统计分析可能不会考虑转换获得正态分布的应用,如日志arithm,平方根,互惠和权力转换(帕特尔和阅读1982)在某些情况下,跳过异常值,但是使用这种技术必须非常小心。这些方案可以解决正态性条件,但同方差条件可能导致求解困难。一些参数检验,如方差分析,受到同方差条件的很大影响。
3.3多问题分析所需条件的研究
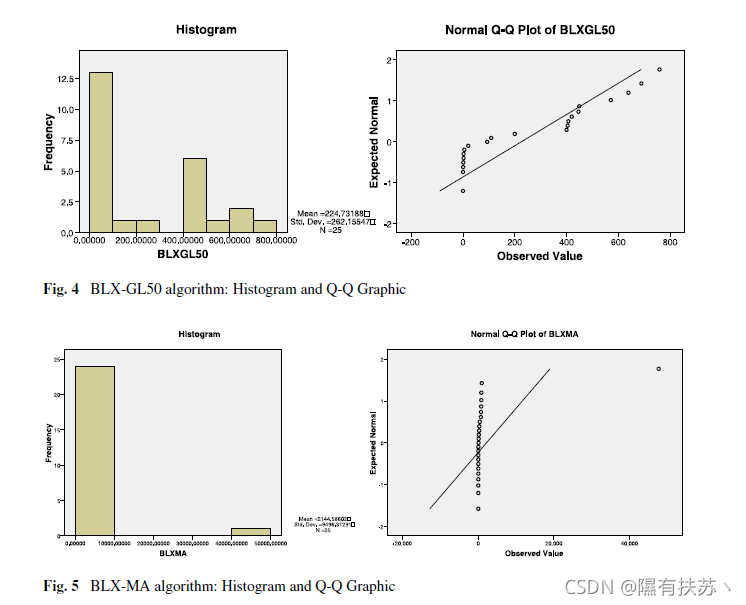
当处理一个多问题分析时,使用的数据是从各个算法的运行中获得的结果的集合。在这个聚合中,必须只有一个表示问题或函数的结果。这个结果可以通过对所有运行的结果进行平均或类似的方法得到。但是接下来的过程对于每个函数必须是相同的:例如。在本文中,我们在每个函数中使用了算法25次运行的平均值。对于每个算法来说,要分析的结果样本的大小等于问题的数量。通过这种方式,多问题分析允许我们在一组问题上同时比较两个或多个算法。我们可以使用发表在CEC“2005特别会议”上的结果进行多问题分析。确实。我们将遵循与前一小节相同的程序。我们将分析通过平均每个函数的错误率所获得的样本结果的参数检验的安全使用所需条件。表6显示了用BLX-GL50和BLX-MA获得的样本结果的正态性检验的p值。图4和图5是这类样本的直方图和Q-Q图。
显然,正态性条件是不满足的,因为结果的样本是由25个不同问题的25个平均错误率计算组成的。我们通过两两统计检验比较了两种算法的行为:
- 通过配对t检验得到的p值为p = 0.318。配对t检验不考虑算法之间存在性能差异Wilcoxon检验得到的p值为p = 0.089。
- Wilcoxont检验不考虑算法之间性能差异的存在。但它大大降低了检测差异的最小显著性水平。如果考虑显著性水平为0.10,则Wilcoxon检验证实BLX-GL50优于BLX-MA。

这两种算法的平均结果表明了这种行为,BLX-GL50通常比BLX-MA表现得更好(见附录B中的表13),但配对t检验不能理解这一事实。在多问题分析中,除非增加新的功能/问题,否则不可能扩大结果的样本。应用转换或跳过异常值也不能使用,因为我们将更改某些问题的结果,而不是其他问题的结果。
这些事实可以引导我们使用非参数统计来分析多问题的结果。非参数统计不需要与要分析的数据样本相关的预先假设,在本节所示的示例中,我们已经看到它们可以获得可靠的结果。
4一个案例研究:使用非参数统计比较CEC’2005实参数优化专题会议的结果
在本节中,我们研究了在CEC’2005实参数优化专题会议上获得的结果,作为使用非参数检验的案例研究。正如我们所提到的,我们将关注维度D=10。
我们将根据Hansen(2005)给出的关于函数难度的建议,将函数集划分为两个子组。
- 第一组由单峰函数(从fl到f5)和多峰函数(从f6到f14)组成,在CEC’2005竞赛中,所有参赛者的算法通常都达到最优。其中,参与者算法至少运行一次达到最优。
- 第二组包含剩下的函数,从函数f15到f25。Io的这些功能,没有参与者的算法都达到了最优。
进行这种划分的目的是显示考虑到不同数量的功能的统计分析的差异。这是影响研究的一个重要因素。它还允许我们比较算法在处理最复杂函数时的行为。事实上,我们也可以研究一组函数fl-f14。但我们不把它包括在内,以免扩大文件的内容。因此,对于所有函数(从fl到f25)和困难函数(从f15到f25),参加CEC2005特别会议的算法给出的结果是独立分析的。
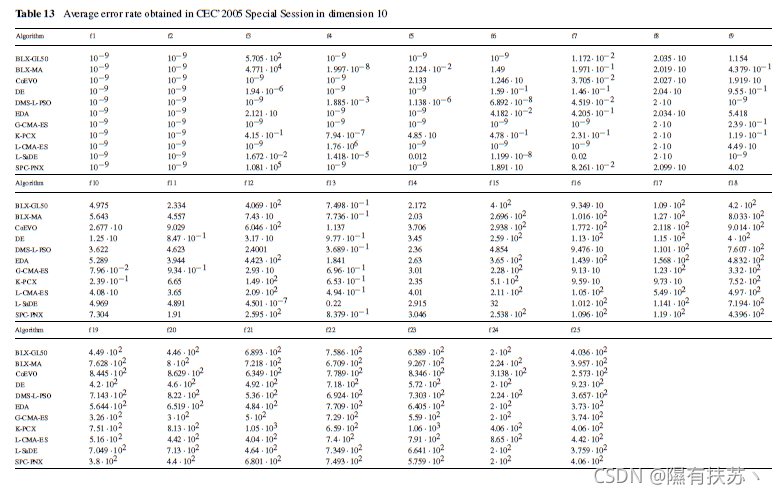
就像我们以前做的那样。我们考虑使用每个算法获得的错误率作为性能衡量。这种情况对应于多问题分析,因此使用非参数统计检验比使用参数统计检验更可取,正如我们在前一节中看到的那样。附录B表13总结了通过函数和算法组织的比赛的官方结果。
值包含在表13允许我们执行严格的统计研究,以检查是否算法的结果,而重要的考虑他们不同在质量上连续函数的逼近我们的研究将集中在算法的平均错误率最低比较,G-CMA-ES。我们将研究这个算法相对于其他算法的行为。我们将确定它提供的结果是否比其他算法提供的结果更好,计算每个比较的p值。
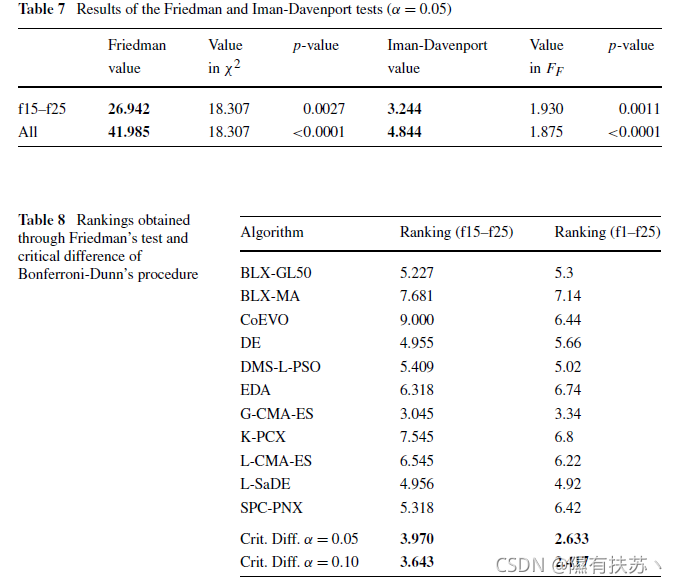
表7为采用Friedman’s和Iman-Davenport’s检验的结果,看结果是否存在全局差异。考虑Friedman和Iman-Davenport的p值低于显著性水平(a=0.05),第一组和第二组的功能观测结果存在显著性差异。注意这些结果。事后的统计分析可以帮助我们发现算法之间的具体差异。
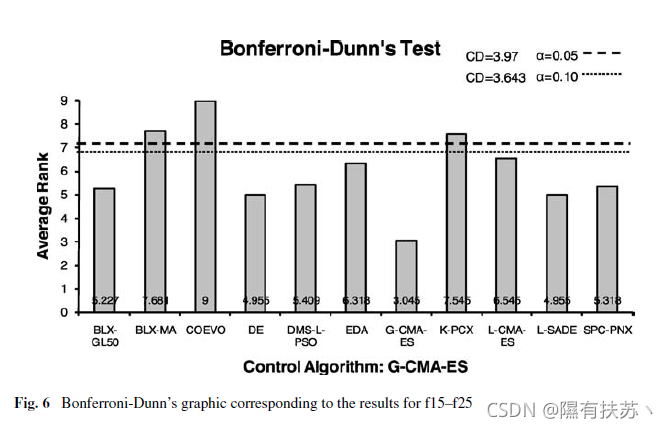
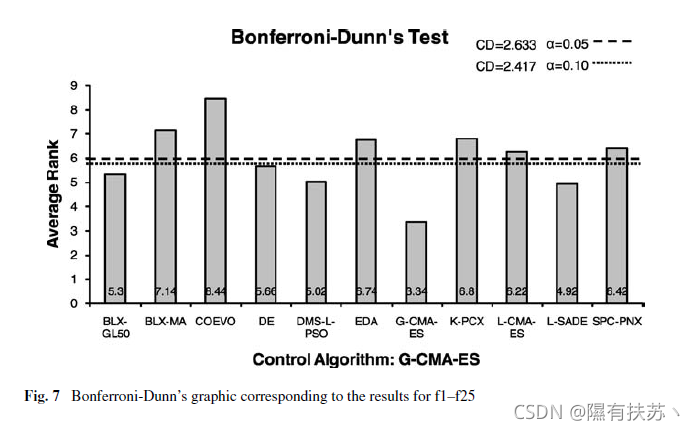
首先,我们将使用Bonferroni-Dunn检验来检测控制算法G-CMA-ES的显著差异。表8总结了Friedman检验和Bonferroni-Dunn程序的临界差值。图6和图7显示了两组函数的图形表示(包括每个算法获得的排名)。在Bonferroni-Dunn的图表中,每个算法获得的排名之间的差异被说明。在其中,我们可以画一条水平切线,表示性能最好的算法的阈值,即排名杆最低的算法。以考虑它比其他算法更好。剪线绘制每一层的意义被认为是在研究高度等于排名之和的控制算法和相应的关键区别Bonferroni-Dunn计算的方法(请参阅附录A .)那些酒吧超过这条线是一种算法的关联比控制较差的性能算法。
通过对Bonferroni-Dunn检验的应用,我们发现G-CMA-ES作为控制算法存在以下显著差异:f15-25:G-CMA-ES优于CoEVO和BLX-MA和K-PCX, a = 0.05和a =0.10(3/10算法)请注意BLX-MA。K-PCX。EDA。蛇蝎美人与a= 0.05和a=0.10(6/10算法)。尽管G-CMA-ES的错误率和排名率最低。Bonferroni-Dunn测试并不能比其他所有算法更好地区分。
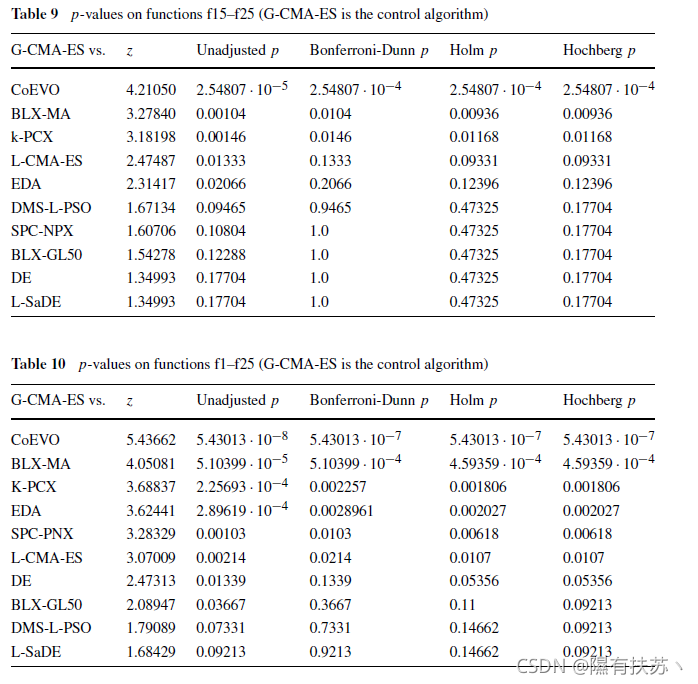
与前一节相同,我们将使用更强大的程序,如Holm’s和Hochberg’s(附录A.3中描述),将控制算法与其余算法进行比较。结果通过计算每个比较的p值来显示。表9和表10显示了考虑两组函数的Bonferroni-Dunn、Holm和Hochberg程序的p值。计算p值的过程在附录A.3中进行了说明。Holm的过程和Hochberg的过程让我们指出了以下不同点,以G-CMA-ES作为控制算法:
- f15-25:G-CMA-ES优于CoEVO。BLX-MA和K-PCX的a=0.05(3/10算法),优于L-CMA-ES的a=0.10(4/10算法)。在这里,Holm和Hochberg的程序是一致的,考虑到Bonferroni-Dunn的a =0.10,他们拒绝了一个额外的假设。
- fl-25:基于Holm的程序,它的性能优于CoEVO, BLX-MA。K-PCX EDA。SPC-PNX和L-CMA-ES的a =0.05(6/10算法),它也得出DE的a =0.10(7/10算法)。它拒绝等量的假设。正如Bonferroni-Dunn所做的那样,a = 0.05。当a =0.10时,它还拒绝了一个比Bonferroni-Dunn多出的假设。
- 当我们建立a= 0.05时,ochberg程序的行为与Holm程序的行为相同。但是,当a= 0.10时,它得到不同的结果。比较中所有的p值都低于0.10,因此所有与它们相关的假设都被拒绝(10/10算法)。事实上。Hochberg的程序从整体上考虑了所有函数,确定了G-CMAES是竞赛中最优的算法。
在接下来的研究中,我们将通过两两比较的方式将G-CMA-ES算法与其他算法进行比较。在本研究中,我们将使用Wilcoxon检验(见附录A.2)直到现在。我们已经使用程序来执行多次比较,以检查算法的行为。鉴于Hochberg的过程结果,这个过程不是必要的,但我们包括它是为了强调使用多重比较过程而不是两两比较之间的差异。表11和12总结了应用Wilcoxon检验的结果。它们显示每次比较获得的排名和相关的p值。
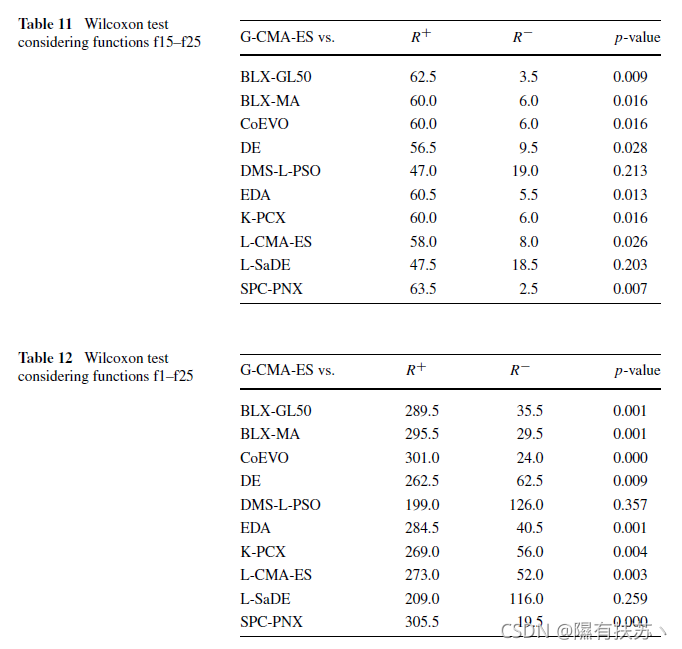
Wilcoxon检验执行两种算法之间的单独比较(成对比较)。两两比较中的p值是独立于另一个p值的。如果我们试图在威尔考克森的分析中提取一个包含不止一个两两比较的结论。我们将从两两比较的组合中得到一个累积误差。在统计术语。我们正在失去对家庭明智错误率(FWER)的控制。定义为在执行多个成对测试时,在所有假设中做出一个或多个错误发现的概率。结合两两比较的真实统计显著性为:
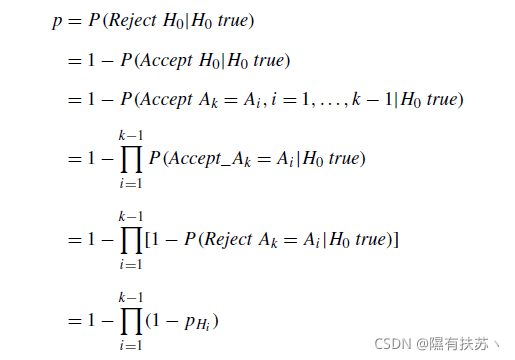
观察表11,声明:“G-CMA-ES算法优于BLX-GL50, BLX-MA, CoEVO, DE, EDA, K-PCX, L-CMA-ES和SPC-PNX显著性水平a =0.05”的算法不能正确,除非我们不能检查对flower的控制。考虑到独立的两两比较,G-CMA-ES算法确实优于这八种算法,因为p值低于a =0.05。另一方面,请注意,其中没有包含两种算法。如果我们将它们纳入多重比较,在f15-125组中得到的p值为p=0.4505,考虑到所有函数,p= 0.5325。在这种情况下,就不可能说“G-CMA-ES算法的性能明显优于其他算法”。因为实现的p值太高了。
由表达式(1)和表11、12可知,G-CMA-ES优于之前列举的8种算法,其p值为
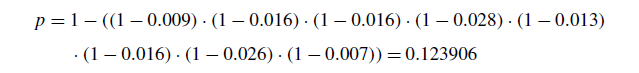
对于f15-25和这组函数:
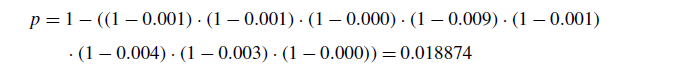
考虑所有的功能。因此,只有在比较中考虑到所有函数时,才可以肯定前面的说法为执行多重比较而设计的程序在其定义中控制FWER。通过使用本节中考虑的示例,我们使用了G-CMA-ES算法作为控制。
我们可以很容易地反映出所使用的所有测试程序的力量之间的关系。按幂级数递增,并考虑到学习中所有的函数。程序可按以下方式排序:Bonferroni-Dunn (p =0.9213)。Wilcoxon’s检验(用于多次比较时)(p=0.5325)、Holm (p=0.1466)和Hochberg (p=0.0921)。
最后,我们必须指出,这里使用的统计程序表明,最佳算法是G-CMA-ES。虽然在Hansen(2005)。函数的分类取决于它们的困难程度不同于本文所使用的(我们将单峰函数和可溶多峰函数合并在一组中),G-CMA-ES算法被强调为考虑错误率的最佳行为算法。因此,总结一下。在本文中,Hansen(2005)的结论得到了统计上的支持。
5关于使用非参数检验的一些考虑
考虑到本文中所展示的非参数检验应用的所有结果、表格和图表,我们可以对非参数统计技术的使用提出一些方面和细节:
-
对各种算法进行多重比较,首先必须使用统计方法检验相关样本均值之间的差异,即各算法得到的结果。一旦这个检验拒绝了均数相等的假设。利用事后统计方法可以检测算法之间的具体差异。
-
霍尔姆的程序总是被认为比Bonferroni-Dunn的程序更好,因为它适当地控制了flower,而且它比Bonferroni-Dunn的更强大。我们强烈建议在严格比较中使用Holm的方法。然而。由Bonferroni-Dunn检验提供的结果适合用图形表示来显示。霍赫伯格的方法比霍姆的更有效。在实践中,报告的方法与Holm方法之间的差异相当小,但在本文中,我们展示了一个Hochberg方法得到的p值低于Holm方法的例子(见表10)。我们建议将这个测试与Holm的方法结合使用。
-
虽然Wilcoxon检验和其余用于多重比较的事后检验属于非参数统计检验,但它们的操作方式不同。主要差异在于排名的计算。Wilcoxon检验根据函数之间的差异独立计算排名,而Friedman和导数程序计算算法之间的排名。
-
关于样本量(在多问题分析中执行Wilcoxon或Friedman检验时的函数数),有两个主要方面:
首先,需要规定每项测试可接受的最小样本。关于这个规格没有确定的协议。统计学家研究了当统计检验有一定的能力时的最小样本量(Noether 1987;莫尔斯1999年)。在我们的例子中,最好使用尽可能大的样本量,因为统计检验(定义为检验将拒绝错误零假设的概率)的威力将会增加。
此外,在多问题分析中,样本量的增加依赖于新函数的可用性(这在实参数优化领域是众所周知的)。其次。我们必须研究如果有更大的样本量,结果会如何变化。用于比较两个或多个样本的所有统计检验。样本量的增加有利于测试的能力。在下列项目中。我们将声明Wilcoxon检验受这一因素的影响小于Friedman检验。最后,作为一个经验法则,函数的数量(N)在研究中应该是N=a.k。其中k为要比较的算法个数,并且a>2。 -
考虑到之前的观察和知道非参数检验所执行的操作,我们可以推断出Wilcoxon检验受所使用的函数数量的影响。另一方面,当我们引用多重比较测试(如Friedman’s测试)时,算法和函数的数量都是至关重要的,因为所有的临界值都取决于N的值(参见附录A.3中的表达式)。然而,函数数量的增加/减少很少影响排序的计算。在这些过程中,当我们想要控制FWER时,所使用的函数的数量是一个需要考虑的重要因素。
-
为了使用每种类型的测试,需要使用适当数量的算法,而不是适当数量的函数。在多个比较过程中使用的算法的数量必须小于函数的数量。在CEC’2005特别会议的研究中,我们可以看到使用函数数量的影响,而算法数量保持不变。例如,当考虑f15-125基团和所有函数时得到的p值。在后一种情况下,对于每个测试过程,获得的p值总是低于第一个。一般来说,p值较低,这与在多个比较过程中使用的函数数量的增加一致;因此,算法之间的差异更容易被发现。
-
在Wilcoxon检验中,前面的陈述可能不正确。在多次比较过程中所使用的函数数量的影响比在Wilcoxon检验中更明显。例如,f15-125组的Wilcoxon检验计算的最终p值低于fl-25组(见上一节)。
6结论
在本文中,我们研究了统计技术在优化问题中进化算法行为分析中的使用,分析了参数和非参数统计检验的使用。
我们区分了两种类型的分析。第一个称为单问题分析,即对每个函数/问题分别进行结果分析。第二个。所谓多问题分析,就是把所有研究的问题同时考虑进去,对结果进行分析。
在单问题分析中,我们看到安全使用参数统计的必要条件通常是不满足的。然而,在参数分析和非参数分析之间所得到的结果是相当相似的。此外,还有转换或调整样本结果以供参数统计检验使用的程序。
我们鼓励使用非参数检验,当我们想要分析在多问题分析中,连续优化问题的进化算法得到的结果。由于不满足保证参数试验可靠性的初始条件。在这种情况下,结果来自不同的问题,不可能用参数统计的方法来分析结果。
关于非参数检验的使用,我们已经展示了如何使用Fried man, Iman-Davenport。Bonferroni-Dunn。河中沙洲。业务。和Wilcoxon的测试;总的来说。是一个很好的算法分析工具。在CEC’2005实参数优化专题会议上,我们使用这些程序对每个算法的结果进行了比较。
附录A:推论统计检验简介
本节专门介绍理解本文中使用的统计术语所必需的问题。此外,还对非参数检验进行了描述,以便在进一步的研究中使用。为了区分非参数测试和参数测试,我们必须检查测试所使用的数据类型。非参数检验是指使用名义或顺序数据的检验。这一事实并不强制它只用于这些类型的数据。将数据从真实值转换为基于排名的数据是可能的。这样,当参数测试的经典数据不能验证测试所要求的条件时,就可以对其进行非参数测试。一般来说,非参数检验的限制性比参数检验的限制性小。尽管当数据条件良好时,它不如参数健壮。
A.1假设检验和p值
在推理统计学中,样本数据主要用两种方法来推断一个或多个总体。其中之一是假设检验。假设检验中最基本的概念是假设。它可以定义为对单个种群或两个或两个以上种群之间关系的预测人群。
假设检验是一种使用样本数据来评估假设的过程。研究假设和统计假设是有区别的。第一个是对研究人员的预测的一般陈述。为了评估一个研究假设。在两个统计假设的框架内重申。它们是零假设,用Ho表示。和备择假设,用H表示。零假设是没有影响或没有差异的陈述。由于研究假设的陈述通常预测了与正在研究的任何东西有关的差异的存在,零假设通常是研究人员希望被拒绝的假设。备择假设是一种统计陈述,表明存在一种影响或差异。在这种情况下。研究者通常期望替代假说得到支持。备选假设可以是无方向性的(双尾假设)和方向性的(单尾假设)。
第一种类型不做特定方向的预测,即H: 100。后者意味着选择下列方向的替代假设之一;即H: > 100或H: u<100。在为研究收集数据时。假设检验过程的下一步是通过使用适当的推理统计检验来评估数据。推理统计检验产生检验统计量。后一个值是通过使用包含关于测试统计量的预期分布信息的特殊表来解释的。这样的表包含测试统计量的极端值(称为临界值),如果null假设为真,这些极端值非常不可能出现。这样的表格可以让研究人员确定研究结果是否具有统计学意义。推理统计中使用的传统假设检验模型假设在进行研究之前。研究人员规定是采用方向性的还是非方向性的替代假设,以及在何种显著性水平上表示要评估的无效假设。表示显著性水平的概率值用o表示。
当我们在科学研究的背景下使用显著性这个术语时,区分统计显著性和实际显著性是有指导意义的。统计学上的显著性只意味着一项研究的结果极不可能是偶然发生的。但这并不一定意味着在一组数据中检测到的任何差异或影响具有任何实际价值。
例如,通常没有人会关心算法A解球函数的误差是否在全局最优值的10-10以内,算法B解球函数的误差是否在全局最优值的10-10以内。可以发现统计意义,但在实际意义上。这种差异并不显著。我们可以计算导致拒绝零假设的最小显著性水平,而不是预先规定显著性水平a。这就是p-value的定义,对于统计分析的许多消费者来说,p-value是一个有用而有趣的数据。p值提供关于统计假设检验是否显著的信息。它还表明了结果的“重要性”:p值越小,反对零假设的证据就越强。最重要的是,它这样做没有承诺一个特定的重要程度。
获得与假设相关的p值最常见的方法是用正态近似法。这是。一旦计算出与统计测试或过程相关联的统计量,我们就可以使用特定的表达式或算法来获得z值,它对应于一个正态分布统计量。然后,用正态分布表。我们可以得到与z相关的p值。
A.2 Wilcoxon配对符号秩检验
Wilcoxon检验用于回答以下问题:两个样本是否代表两个不同的总体?它是一个非参数的程序,用于假设检验的情况下,涉及两个样本的设计。它类似于非参数统计过程中的配对t检验:因此,它是一种旨在检测两种算法行为之间的显著差异的配对检验。
Wilcoxon检验的原假设为Ho: Bp=0;在两个结果样本所代表的基础人群中,差异分数的中位数等于零。另一种假设是H:Bp 0,也可以用H:Bp>或Hl:9p <0作为方向假设。
在下面,我们描述测试计算。设di为两种算法在N个函数中的第i个函数上的性能分数之差。根据其绝对值对差异进行排序;如果平局,则分配平均级别。设Rt是第二个算法优于第一个算法的函数的秩和,R是相反的函数的秩和。di =0的秩在和之间平均分配;如果它们的数量是奇数,其中一个被忽略:
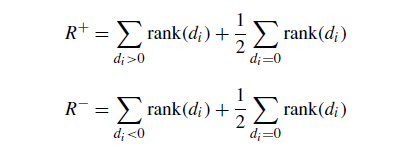
设T是最小的和,T =min(R+, R-)如果T小于或等于N个自由度的Wilcoxon分布值,则拒绝均值相等的原假设。与比较相关的p值的获取是通过Wilcoxon T统计量的正态逼近来实现的。此外,该检验的p值的计算通常包含在知名的统计软件包(SPSS, SAS, R等)中。
A.3 Friedman按等级双向方差分析
Friedman检验用于回答这个问题:在一组k个样本中(其中k22),是否至少有两个样本代表具有不同中位数的总体值?它是一个非参数程序,用于假设检验情况下,涉及两个或多个样本的设计。
它类似于非参数统计过程中的重复测量方差分析:因此,它是一个多重比较测试,旨在检测两个或多个算法的行为之间的显著差异。Friedman检验的原假设为Ho:01=02=…= Bk;总体I的中位数表示总体j的中位数,即1< I <k 1< j<k。另一种假设是H:不是Ho,所以它是非方向性的。
在下面,我们描述测试计算。计算算法(r;对于算法I和k个算法)的每个函数,分配给其中最好的排序1。最差的是k。在零假设下,由假设算法的结果是等价的而形成,因此。他们的排名也很相似,根据弗里德曼的统计:
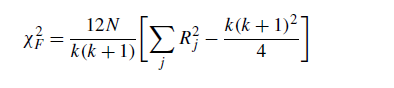
是按x分布,自由度为k-1, Rj= r, N为函数个数。当n> 10和kbbb5时,Friedman统计量的临界值与x2分布中建立的值一致。在相反的情况下,可以在Sheskin(2003)中看到准确的值;金(1999)伊曼和达文波特(1980)从弗里德曼的统计量提出了一个推导,因为最后一个度量产生了保守的不良效应。建议的统计数字是
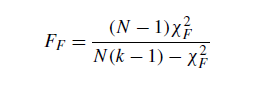
按照自由度为k-1和(k-1)(N-1)的F分布分布。
对于给定x2或Fr统计量的p值的计算可以使用Abramowitz(1974)的算法来完成,而且,大多数统计软件包都包含它.
在上述两个测试中拒绝原假设并不涉及检测被比较的算法之间存在的差异。它们只告诉我们,为了在多重比较的框架内进行两两比较,所有被比较结果的样本之间存在差异。我们可以进行事后处理。在这种情况下。通常会选择一个控制算法(可能是一个要比较的建议)。然后,进行后期处理,将控制算法与剩下的k-1算法进行比较。在下面,我们将介绍三个事后程序:
1 Bonferroni-Dunn的程序(Zar 1999);它类似于Dunnet的方差分析设计测试。两种算法的性能存在显著差异排名的平均回答至少和它的关键差异(CD)一样大。
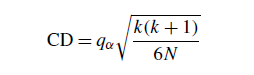
qα的值是与控制项进行多重非参数比较的Q’的临界值(Zar 1999表B.16)。
- 霍尔姆(1979)程序:为了对比Bonferroni-Dunn程序,我们处理了一个程序,根据其重要性顺序检查假设。我们用顺序表示p值,p2,…Spk-1。霍尔姆的方法是从最显著的p值开始,将每个pi与a/(k-i)进行比较。如果pi小于a/(k-1),那么相应的假设就被拒绝了,我们只能将p2与a/(k-2)进行比较。如果第二个假设被拒绝,我们就继续这个过程。一旦某一假设不能被否定,所有剩下的假设就会被支持。i算法与ji算法的比较统计如下:
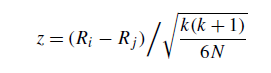
z的值用于从正态分布表(p值)中找到相应的概率,并与o的对应值进行比较。
霍尔姆的方法比Bonferroni-Dunn的方法更强大,而且它对所检查的假设没有额外的假设。
3 Hochberg(1988)程序:这是一种与Holm方法相反的渐进程序。比较最大的p值和a,第二大的p值和a/2等等,直到遇到一个可以拒绝的假设。所有p值较小的假设也被拒绝。Hochbere的方法比Holm的更强大(Shaffer 1995)。
当一个p值在倍数比较范围内时,它反映了某一比较的概率误差。但它没有考虑到属于家庭的其余比较。解决此问题的一种方法是报告考虑到执行多个测试的调整p值(apv)。一个APV可以直接作为一个假设的p值,属于多个算法的比较。
在下面。我们将根据Wright(1992)的指示说明如何计算上述三个事后程序的apv。
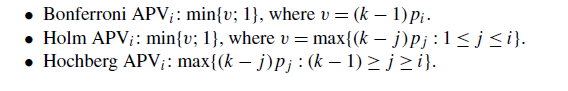
Appendix B: published average results of the CEC’2005 Special Session
原文:Salvador García,Daniel Molina,Manuel Lozano,Francisco Herrera."A study on the use of non-parametric tests for analyzing the evolutionary algorithms’ behaviour: a case study on the CEC’2005 Special Session on Real Parameter Optimization”. J Heuristics. 2009.15,617-644.10.1007/s10732-008-9080-4.