YOLOv8最新改进系列:YOLOv8+BiFormer(CVPR 2023最新提出),基于动态稀疏注意力构建高效金字塔网络架构,用动态、查询感知的方式实现计算的有效分配,嘎嘎提升目标检测效果!
YOLOv8最新改进系列
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽 改进后的源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!
截止到发稿,B站YOLOv8最新改进系列的源码包已更新了24种+损失函数改进!
自己排列组合2-4种后,不考虑位置已达上万种改进方法,考虑位置不同后可排列上百万种!专注AI,关注B站博主:AI学术叫叫兽!
YOLOv8最新改进系列:YOLOv8+BiFormer,基于动态稀疏注意力构建高效金字塔网络架构,用动态、查询感知的方式实现计算的有效分配,嘎嘎提升目标检测效果!!!
一、BiFormer概述
1.1 导读
众所周知,Transformer相比于CNNs的一大核心优势便是借助自注意力机制的优势捕捉长距离上下文依赖。正所谓物极必反,在原始的 Transformer 架构设计中,这种结构虽然在一定程度上带来了性能上的提升,但却会引起两个老生常态的问题:
1、内存占用大
2、计算代价高
在我B站视频的演示中,充分的证明了上述问题。
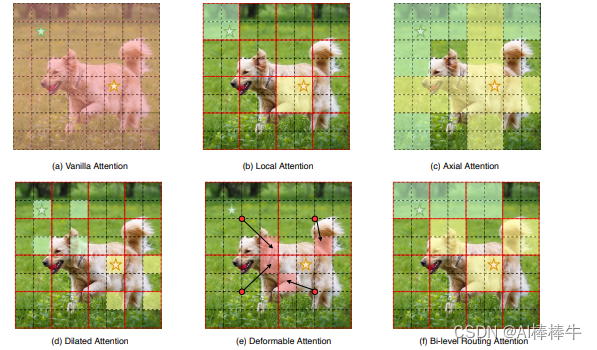
让我们先简单的看下上图:其中图(a)是原始的注意力实现,其直接在全局范围内操作,导致高计算复杂性和大量内存占用;而对于图(b)-(d),这些方法通过引入具有不同手工模式的稀疏注意力来减轻复杂性,例如局部窗口、轴向条纹和扩张窗口等;而图(e)则是基于可变形注意力通过不规则网格来实现图像自适应稀疏性;
总的来说,作者认为以上这些方法大都是通过将 手工制作 和 与内容无关 的稀疏性引入到注意力机制来试图缓解这个问题。因此,本文通过双层路由(bi-level routing)提出了一种新颖的动态稀疏注意力(dynamic sparse attention ),以实现更灵活的计算分配和内容感知,使其具备动态的查询感知稀疏性,如图(f)所示。
此外,基于该基础模块,本文构建了一个名为BiFormer的新型通用视觉网络架构。由于 BiFormer 以查询自适应的方式关注一小部分相关标记,而不会分散其他不相关标记的注意力,因此它具有良好的性能和高计算效率。最后,通过在图像分类、目标检测和语义分割等多项计算机视觉任务的实证结果充分验证了所提方法的有效性。
1.2 方法-Bi-Level Routing Attention
为了缓解多头自注意力(Multi-Head Self-Attention, MHSA)的可扩展性问题,先前的一些方法提出了不同的稀疏注意力机制,其中每个查询只关注少量的键值对,而非全部。然而,这些方法有两个共性问题:
要么使用手工制作的静态模式(无法自适应);
要么在所有查询中共享键值对的采样子集(无法做到互不干扰);
为此,作者探索了一种动态的、查询感知的稀疏注意力机制,其关键思想是在粗糙区域级别过滤掉大部分不相关的键值对,以便只保留一小部分路由区域(这不就把冗余的信息干掉了吗老铁们)。其次,作者在这些路由区域的联合中应用细粒度的token-to-token注意力。
简单梳理下。假设我们输入一张特征图,通过线性映射获得QKV;其次,我们通过领接矩阵构建有向图找到不同键值对对应的参与关系,可以理解为每个给定区域应该参与的区域;最后,有了区域到区域路由索引矩阵 ,我们便可以应用细粒度的token-to-token注意力了。
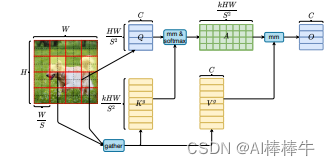
上面是 BRA 模块的示意图。从图中可以看出,该方法是通过收集前 k 个相关窗口中的键值对,并利用稀疏性操作直接跳过最不相关区域的计算来节省参数量和计算量。值得一提的是,以上操作涉及 GPU 友好的密集矩阵乘法,利于服务器端做推理加速。
BiFormer
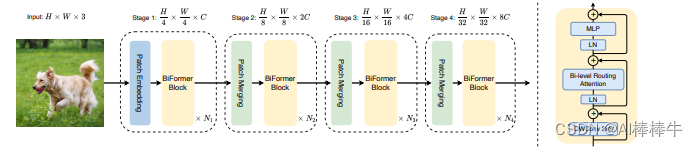
基于BRA模块,本文构建了一种新颖的通用视觉转换器BiFormer。如上图所示,其遵循大多数的vision transformer架构设计,也是采用四级金字塔结构,即下采样32倍。
具体来说,BiFormer在第一阶段使用重叠块嵌入,在第二到第四阶段使用块合并模块来降低输入空间分辨率,同时增加通道数,然后是采用连续的BiFormer块做特征变换。需要注意的是,在每个块的开始均是使用 的深度卷积来隐式编码相对位置信息。随后依次应用BRA模块和扩展率为 的 2 层 多层感知机(Multi-Layer Perceptron, MLP)模块,分别用于交叉位置关系建模和每个位置嵌入。
1.3 实验
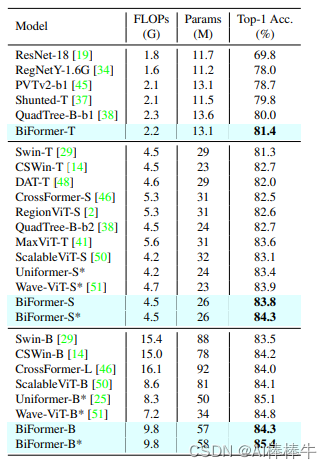
所有模型都在分辨率为 的图像上进行训练和评估。其中星号表示该模型是使用标记标签进行训练的。据笔者所知,这是在没有额外训练数据或训练技巧所能取得的最佳结果。此外,使用基于标记的蒸馏技术,BiFormer-S的准确率可以进一步提高到 !
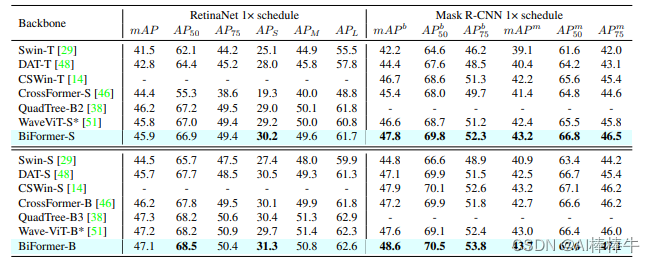
可以看到,本文方法貌似对小目标检测效果比较好。这可能是因为BRA模块是基于稀疏采样而不是下采样,一来可以保留细粒度的细节信息,二来同样可以达到节省计算量的目的。

为了进一步了解双层路由注意力的工作原理,作者将路由区域和注意力响应进行可视化。从图中我们可以清楚地观察到语义相关区域已被成功定位。例如,在第一个场景中的街景所示,如果查询位置在建筑物或树上,则对应的路由区域覆盖相同或相似的实体。而在第二个室内场景中,当我们将查询位置放在鼠标上时,路由区域包含主机、键盘和显示器的一部分,即使这些区域彼此不相邻。这意味着双层路由注意力可以捕获远距离对上下文依赖。
1.4 文章总结
本文提出了一种双层路由注意力模块,以动态、查询感知的方式实现计算的有效分配。其中,BRA模块的核心思想是在粗区域级别过滤掉最不相关的键值对。它是通过首先构建和修剪区域级有向图,然后在路由区域的联合中应用细粒度的token-to-token注意力来实现的。值得一提的是,该模块的计算复杂度可压缩至 !最后,基于该模块本文构建了一个金字塔结构的视觉Transformer——BiFormer,它在四种流行的视觉任务、图像分类、目标检测、实例分割和语义分割方面均表现出卓越的性能。
更多目标检测算法改进和论文写作内容请关注B站:AI学术叫叫兽
二、YOLOv8+GSConv+Slim Neck
2.1 修改YAML文件
2.2 新建BiFormer.py
2.3注册(包含很多改进,不需要的可删)
三、验证是否成功即可
执行命令
python train.py
改完收工!
关注B站:AI学术叫叫兽
从此走上科研快速路
遥遥领先同行!!!!
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!