Clickhouse-file:基于Clickhouse-local实现Clickhouse高效写入数据
前言
ClickHouse是一个用于OLAP(在线分析处理)的列式数据库管理系统,它专门为大数据量和高并发场景而设计。ClickHouse具有快速的扫描和聚合海量数据的能力,并且支持高并发查询,使其在处理数据分析任务方面比传统的行存储数据库更具优势。ClickHouse是一个开源项目,可以在较少的硬件资源上运行,并且可以轻松地水平扩展,以适应不断增长的数据量和流量。在快速增大的数据量的情况下,使用传统的数据写入模式,如:JDBC、CSV,会增大Clickhouse服务的数据解析压力。那是否有方法一方面能够提升数据写入量,另一方面减少Clickhouse的服务数据解析、写入压力呢?
1. 常用clickhouse flink connector
- 基于Clickhouse-jdbc
使用官方提供的Clickhouse-jdbc驱动,通过SQL的形式将数据提交到Clickhouse服务器。优势是灵活性最高,但是在大数据量写入的情况下该方法会触发频繁的后台文件合并,甚至会出现“too many parts”的错误,同时大量的SQL解析对Clickhouse服务器有影响。
- 官方插件(基于CSV)
将数据源流转化为CSV格式数据,并通过Http请求批量发送到Clickhouse。优势在于不需要任何驱动依赖,格式简单。缺点是稳定性差,对网络稳定性要求高
项目地址:GitHub - ivi-ru/flink-clickhouse-sink: Flink sink for Clickhouse
- 基于clickhouse-file插件
Clickhouse-file插件,其主要实现方式是,将数据写入到CSV文件,然后通过Clickhouse-local将CSV数据文件转换为Clickhouse-file数据文件,然后将CLickhouse-file上传到远程Clickhouse服务器,用户通过Clickhouse查询数据。其优势是处理大数据量速度快,并且由于在本地生成数据文件,对Clickhouse服务器压力相对较小。缺点是配置复杂度高,通用性较差。其相对于JDBC模式的显著优势是,处理海量数据对服务器造成的压力较小。现在已开源Clickhouse-file的产品有:ClickhouseFile | Apache SeaTunnel,项目仓库地址:seatunnel/seatunnel-connectors-v2/connector-clickhouse · GitHub
2. Clickhouse-file模式
基于Clickhouse-file 模式的,其主要实现方式是,将数据写入到CSV文件,然后通过Clickhouse-local将CSV数据文件转换为Clickhouse-file数据文件,然后将CLickhouse-file上传到远程Clickhouse服务器,用户通过Clickhouse查询数据。现在已开源的积压Clickhouse-file的项目有:ClickhouseFile | Apache SeaTunnel
2.1 基于Clickhouse file模式处理流程
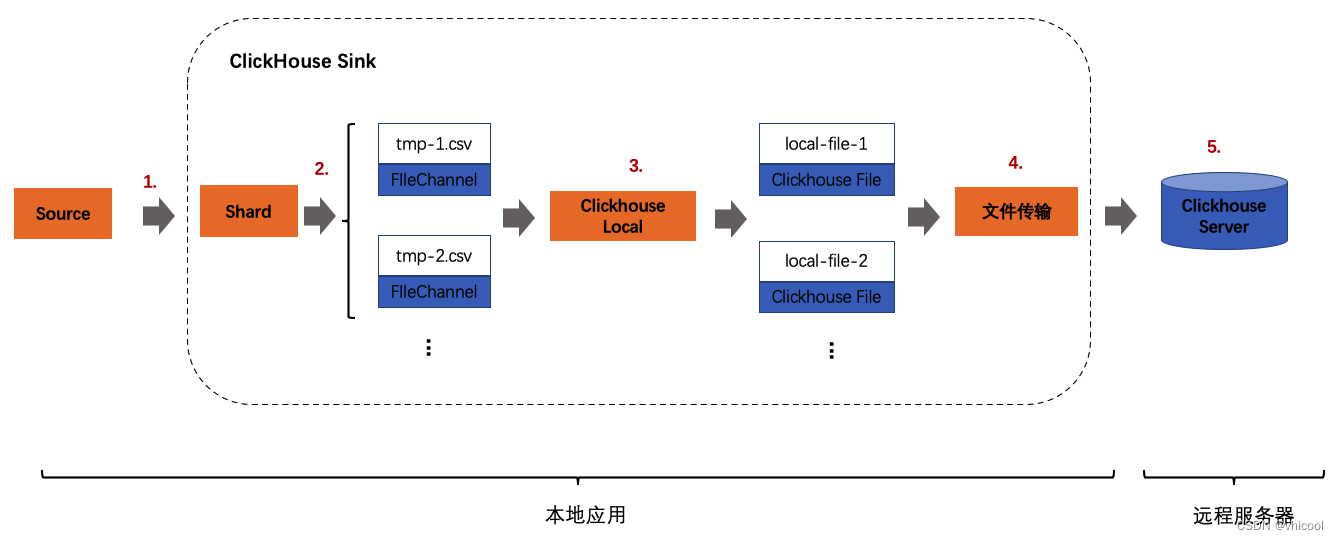
-
Clickhouse Sink接收到源端数据源数据流
-
根据本地缓存的集群的数据分片策略,将数据分别写入到不同的本地缓存CSV文件
-
在同步执行数据快照时或缓存已满,使用Clickhouse Local将加载缓存的CSV数据文件,并生成本地Clickhouse文件
-
将Clickhouse本地文件,通过文件传输工具rsync传输到远程Clickhouse数据目录
-
数据文件Attach到Clickhouse Server,用户可以从Clickhouse中查询数据
2.2 关键技术组件
- clickhouse-local
clickhouse local,开发人员可以直接从命令行使用SQL命令(使用clickhouse SQL方言),提供了一种简单高效的方式来访问clickhouse功能,而无需完整安装clickhouse。用户可以使用clickhouse在不连接clickhouse服务器的情况下,生成clickhouse文件数据,并且支持大多数clickhouse engine。根据这个特性,我们可以在本地将数据通过clickhouse local工具,在本地生成clickhouse数据文件,此文件传输到远程clickhouse数据目录,用户即可查询新的数据。
参考资料:clickhouse-local | ClickHouse Docs
-
clickhouse 临时文件传输到clickhouse服务器
支持两种文件传输方式:rsync、scp
-
相同点:
- 均是基于ssh协议的安全传输工具。
- 都可以通过远程主机的IP地址或域名进行连接,并且需要用户名和密码进行身份验证。
- 传输数据时都会使用加密技术来保证数据的安全性。
-
不同点:
- scp只支持文件传输,而rsync除了可以传输文件,还可以传输目录、链接、设备文件等。
- rsync比scp更加灵活,能够自动检测并同步源和目标之间的差异,只传输发生变化的部分,从而提高传输效率。
- rsync复制时可以指定多个源目录,将它们合并到一个目的目录中,而scp只能传输单个文件或目录。
- rsync还支持增量备份,并且可以在网络传输中断后恢复传输,而scp则不支持这些特性。
-
- Linux rsync
Linux rsync是一种用于文件同步和备份的命令行工具。它能够快速、可靠地将本地或远程计算机之间的文件进行同步,同时可以压缩数据传输并保证数据完整性。rsync的主要优点包括增量备份、支持复制硬链接和符号链接、支持过滤器以排除或包含特定文件和目录等功能。使用rsync可以帮助用户快速而有效地管理和备份文件,特别是在需要将文件从一个位置复制到另一个位置的情况下,比如在服务器之间同步数据。
Rsync可用于镜像数据、增量备份、在系统之间复制文件,并可替代scp、sftp和cp命令。
-
本地文件传输到远程:
rsync -a /opt/media/ remote_user@remote_host_or_ip:/opt/media/ -
远程文件传输到本地:
rsync -a remote_user@remote_host_or_ip:/opt/media/ /opt/media/
参考资料:Rsync Command in Linux with Examples | Linuxize
- scp
基于SSH协议的安全文件传输命令,它可以在本地与远程系统之间复制文件和目录。
-
本地文件传输到远程:
scp /opt/media/ remote_user@remote_host_or_ip:/opt/media/ -
远程文件传输到本地:
scp remote_user@remote_host_or_ip:/opt/media//opt/media/
3. 实战
场景:将本地生成的CSV文件,通过Clickhouse-file导入到远程Clickhouse服务器
-
在clickhouse存在表
my_first_tableCREATE TABLE my_first_table ( user_id UInt32, message String, timestamp DateTime ) ENGINE = ReplacingMergeTree PARTITION BY toYYYYMMDD(timestamp) PRIMARY KEY user_id -
本地新增CSV文件
test_tmp.csv,并写入数据
echo -e "1,wang,2023-05-11 10:00:00\n2,zhang,2023-05-12 11:00:00\n3,sun,2023-05-13 12:00:00" > /Users/vhicool/data/test_tmp.csv
- 通过clickhouse local将CSV文件转换为Clickhouse-file
./clickhouse local --file "/Users/vhicool/data/test_tmp.csv" -S "user_id UInt32,message String,timestamp DateTime" -N "test_tmp_table" \
-q "CREATE TABLE IF NOT EXISTS my_first_table
(user_id UInt32,message String,timestamp DateTime)
ENGINE = ReplacingMergeTree
PARTITION BY toYYYYMMDD(timestamp)
PRIMARY KEY user_id;
INSERT INTO my_first_table select user_id,message,timestamp from test_tmp_table" \
--path "/Users/vhicool/data/test_tmp_file1"
此时我们到`/Users/vhicool/data/test_tmp_file1/目录下,可以查看当前生成的Clickhouse-file。
data/_local/
└── my_first_table
├── 20230511_1_1_0
├── 20230512_2_2_0
├── 20230513_3_3_0
├── detached
└── format_version.tx
- 将Clickhouse-file文件复制到Clickhouse服务器数据目录
cp -r /Users/vhicool/data/test_tmp_file1/data/_local/my_first_table/*_*_*_* data/default/my_first_table/detached/
-
将数据文件ATTACH到Clickhouse数据表中
local :) ALTER TABLE my_first_table ATTACH PART '20230511_1_1_0' local :) ALTER TABLE my_first_table ATTACH PART '20230512_2_2_0' local :) ALTER TABLE my_first_table ATTACH PART '20230513_3_3_0'查询导入的数据
local :) SELECT * FROM my_first_table ┌─user_id─┬─message─┬───────────timestamp─┐ │ 2 │ zhang │ 2023-05-12 11:00:00 │ └─────────┴─────────┴─────────────────────┘ ┌─user_id─┬─message─┬───────────timestamp─┐ │ 1 │ wang │ 2023-05-11 10:00:00 │ └─────────┴─────────┴─────────────────────┘ ┌─user_id─┬─message─┬───────────timestamp─┐ │ 3 │ sun │ 2023-05-13 12:00:00 │ └─────────┴─────────┴─────────────────────┘ 3 rows in set. Elapsed: 0.002 sec.查询数据分片
local :) SELECT partition, name, rows FROM system.parts WHERE table = 'my_first_table' ┌─partition─┬─name───────────┬─rows─┐ │ 20230511 │ 20230511_1_1_0 │ 1 │ │ 20230512 │ 20230512_2_2_0 │ 1 │ │ 20230513 │ 20230513_3_3_0 │ 1 │ └───────────┴────────────────┴──────┘ 3 rows in set. Elapsed: 0.003 sec.
参考资料
flink官方写入数据支持的格式
clickhouse之数据写入问题_clickhouse insert/jdbc
百亿级数据同步,如何基于 SeaTunnel 的 ClickHouse 实现? | Apache SeaTunnel