二十、SQL 数据分析基础与进阶(一)
文章目录
说明:本文对前面学习的 SQL 查询语句进行总结复习。
一、破冰 SELECT 基础检索
1.1 检索所需要的列
1.1.1 检索单列数据
语法:
SELECT <列名> FROM <数据库名>.<数据表名>;
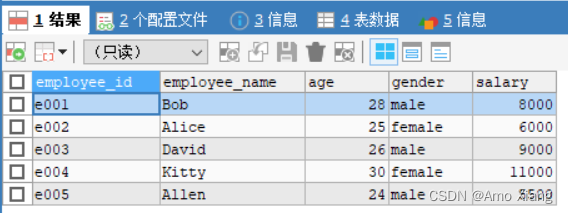
员工信息表包括 employee_id(员工 ID)、employee_name(员工姓名)、age(年龄)、gender(性别)和 salary(薪资)5 个字段,一共有 5 条数据记录。如下图所示:
准备工作,创建表并插入数据,SQL 代码如下:
DROP TABLE IF EXISTS employee_info;
CREATE TABLE employee_info (
employee_id VARCHAR (8),
employee_name VARCHAR (8),
age INT,
gender VARCHAR (8),
salary INT
);
INSERT employee_info (
employee_id,
employee_name,
age,
gender,
salary
) VALUES ('e001', 'Bob', 28, 'male', 8000),
('e002', 'Alice', 25, 'female', 6000),
('e003', 'David', 26, 'male', 9000),
('e004', 'Kitty', 30, 'female', 11000),
('e005', 'Allen', 24, 'male', 5500);
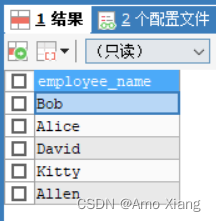
【练习1】查询单列数据。如查询员工姓名,代码如下:
SELECT employee_name FROM sql数据分析.`employee_info`;
-- 省略数据库名 sql数据分析,只写出数据表名
SELECT employee_name FROM employee_info;
查询结果如下图所示,可以发现,employee_name 列数据被检索出来了。
1.1.2 检索多列数据
语法:
SELECT <列名 1>,<列名 2>,...,<列名 n> FROM <数据表名>;
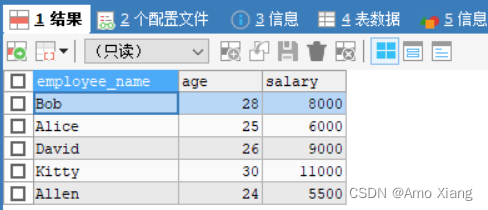
【练习2】以员工信息表为例,查询员工姓名、年龄和薪资,代码如下:
SELECT
employee_name,
age,
salary
FROM
employee_info;
-- 写法2
SELECT
employee_name,
age,
salary
FROM
sql数据分析.`employee_info`;
查询结果如下图所示:
1.2 * 符号初体验
在 SQL 中,* 符号是通配符,表示匹配任意或所有数据,语法如下:
SELECT * FROM <数据表>; -- 从数据表中查询所有数据
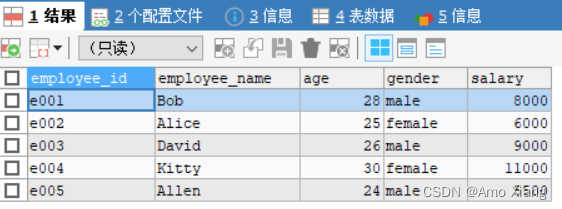
【练习3】以员工信息表为例,查询表中所有数据,代码如下:
SELECT * FROM employee_info;
SELECT * FROM sql数据分析.`employee_info`;
查询结果如下图所示:
1.3 独特的 DISTINCT
语法格式:
SELECT DISTINCT <字段名 1>,<字段名 2>,...,<字段名 n> FROM <表名>;
数据准备:
INSERT INTO employee_info (
employee_id,
employee_name,
age,
gender,
salary
) VALUE ('e006', 'Ben', 28, 'male', 8000);
插入数据后的数据表如下图所示:
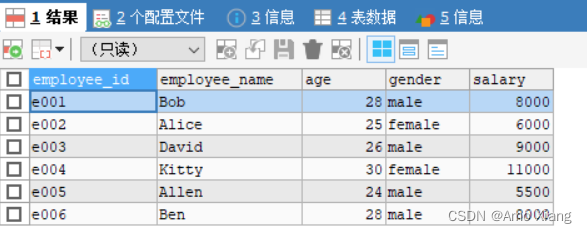
可以发现,gender 列中出现重复数据,male 出现了 4 次,female 出现了 2 次。【练习4】以员工信息表为例,对gender列的数据进行去重,代码如下:
mysql> SELECT gender FROM employee_info;
+--------+
| gender |
+--------+
| male |
| female |
| male |
| female |
| male |
| male |
+--------+
6 rows in set (0.00 sec)
-- DISTINCT 对单列数据进行去重处理的方法。
mysql> SELECT DISTINCT gender FROM employee_info;
+--------+
| gender |
+--------+
| male |
| female |
+--------+
2 rows in set (0.00 sec)
如果 DISTINCT 后面连接多个字段名,则可以对多字段组合进行去重处理, 示例代码如下:
mysql> SELECT gender,salary FROM employee_info;
-- 未去重之后的数据记录为 6条
+--------+--------+
| gender | salary |
+--------+--------+
| male | 8000 |
| female | 6000 |
| male | 9000 |
| female | 11000 |
| male | 5500 |
| male | 8000 |
+--------+--------+
6 rows in set (0.00 sec)
mysql> SELECT DISTINCT gender,salary FROM employee_info;
-- 去重之后的数据记录为 5条
+--------+--------+
| gender | salary |
+--------+--------+
| male | 8000 |
| female | 6000 |
| male | 9000 |
| female | 11000 |
| male | 5500 |
+--------+--------+
5 rows in set (0.00 sec)
1.4 使用 ORDER BY 排序检索结果
语法格式:
-- DESC 降序 ASC 升序 默认升序
ORDER BY <字段名1> <DESC|ASC>,<字段名2><DESC|ASC>,...,<字段名n> <DESC|ASC>;
【练习5】以员工信息表为例,将查询结果按照age列进行降序排列,代码如下:
mysql> SELECT * FROM employee_info ORDER BY age DESC;
+-------------+---------------+------+--------+--------+
| employee_id | employee_name | age | gender | salary |
+-------------+---------------+------+--------+--------+
| e004 | Kitty | 30 | female | 11000 |
| e001 | Bob | 28 | male | 8000 |
| e006 | Ben | 28 | male | 8000 |
| e003 | David | 26 | male | 9000 |
| e002 | Alice | 25 | female | 6000 |
| e005 | Allen | 24 | male | 5500 |
+-------------+---------------+------+--------+--------+
6 rows in set (0.00 sec)
【练习6】以员工信息表为例,将查询结果按照age列进行升序排列,代码如下:
mysql> SELECT * FROM employee_info ORDER BY age ASC;
+-------------+---------------+------+--------+--------+
| employee_id | employee_name | age | gender | salary |
+-------------+---------------+------+--------+--------+
| e005 | Allen | 24 | male | 5500 |
| e002 | Alice | 25 | female | 6000 |
| e003 | David | 26 | male | 9000 |
| e001 | Bob | 28 | male | 8000 |
| e006 | Ben | 28 | male | 8000 |
| e004 | Kitty | 30 | female | 11000 |
+-------------+---------------+------+--------+--------+
6 rows in set (0.00 sec)
-- 从结果来看跟上面字段后加 ASC 是一致的
-- 如果没有显示指定查询结果的排序方式是升序还是降序,则默认按照升序进行排列
mysql> SELECT * FROM employee_info ORDER BY age;
+-------------+---------------+------+--------+--------+
| employee_id | employee_name | age | gender | salary |
+-------------+---------------+------+--------+--------+
| e005 | Allen | 24 | male | 5500 |
| e002 | Alice | 25 | female | 6000 |
| e003 | David | 26 | male | 9000 |
| e001 | Bob | 28 | male | 8000 |
| e006 | Ben | 28 | male | 8000 |
| e004 | Kitty | 30 | female | 11000 |
+-------------+---------------+------+--------+--------+
6 rows in set (0.00 sec)
【练习7】以员工信息表为例,查询结果先按照age列进行降序排列,当age列的各个数据相同时,在按照salary列进行升序排列,代码如下:
mysql> -- 插入数据
mysql> INSERT INTO employee_info (
-> employee_id,
-> employee_name,
-> age,
-> gender,
-> salary
-> ) VALUE ('e007', 'George', 26, 'male', 10000);
Query OK, 1 row affected (0.00 sec)
mysql> SELECT * FROM employee_info ORDER BY age DESC, salary ASC;
-- David和George的年龄相同,都是26岁,而David的薪资比George的薪资低,所以David排在George前面
+-------------+---------------+------+--------+--------+
| employee_id | employee_name | age | gender | salary |
+-------------+---------------+------+--------+--------+
| e004 | Kitty | 30 | female | 11000 |
| e001 | Bob | 28 | male | 8000 |
| e006 | Ben | 28 | male | 8000 |
| e003 | David | 26 | male | 9000 |
| e007 | George | 26 | male | 10000 |
| e002 | Alice | 25 | female | 6000 |
| e005 | Allen | 24 | male | 5500 |
+-------------+---------------+------+--------+--------+
7 rows in set (0.00 sec)
1.5 使用 LIMIT 限制返回行数
当需要查看某张表的数据字段和内容概况时,不需要查询并显示所有记录,只需要查看前几行记录即可,使用 LIMIT 限制查询所返回的行数,语法格式:
LIMIT 初始位置,记录数 -- 如果初始位置为0,则可以省略
-- 1.初始位置是开始读取的第一条记录的编号
-- 在查询结果中,第一个结果的记录编号是0,而不是1,第二个结果的记录编号是 1,后面的记录依次类推
-- 2.记录数 表示显示记录的条数
MySQL8.0 中可以这样写: LIMIT 记录数 OFFSET 初始位置
【练习8】以员工信息表为例,查询员工信息表所有字段信息,并返回前3行记录,代码如下:
-- 可以看出下面三种写法查询出来的结果是一致的
mysql> SELECT * FROM employee_info LIMIT 0,3;
+-------------+---------------+------+--------+--------+
| employee_id | employee_name | age | gender | salary |
+-------------+---------------+------+--------+--------+
| e001 | Bob | 28 | male | 8000 |
| e002 | Alice | 25 | female | 6000 |
| e003 | David | 26 | male | 9000 |
+-------------+---------------+------+--------+--------+
3 rows in set (0.00 sec)
mysql> SELECT * FROM employee_info LIMIT 3;
+-------------+---------------+------+--------+--------+
| employee_id | employee_name | age | gender | salary |
+-------------+---------------+------+--------+--------+
| e001 | Bob | 28 | male | 8000 |
| e002 | Alice | 25 | female | 6000 |
| e003 | David | 26 | male | 9000 |
+-------------+---------------+------+--------+--------+
3 rows in set (0.00 sec)
mysql> SELECT * FROM employee_info LIMIT 3 OFFSET 0;
+-------------+---------------+------+--------+--------+
| employee_id | employee_name | age | gender | salary |
+-------------+---------------+------+--------+--------+
| e001 | Bob | 28 | male | 8000 |
| e002 | Alice | 25 | female | 6000 |
| e003 | David | 26 | male | 9000 |
+-------------+---------------+------+--------+--------+
3 rows in set (0.00 sec)
【练习9】以员工信息表为例,查询员工信息表所有字段信息,并返回从第3行开始的后3行记录,代码如下:
-- 可以看出下面两种写法查询出来的结果是一致的
mysql> SELECT * FROM employee_info LIMIT 2,3;
+-------------+---------------+------+--------+--------+
| employee_id | employee_name | age | gender | salary |
+-------------+---------------+------+--------+--------+
| e003 | David | 26 | male | 9000 |
| e004 | Kitty | 30 | female | 11000 |
| e005 | Allen | 24 | male | 5500 |
+-------------+---------------+------+--------+--------+
3 rows in set (0.00 sec)
mysql> SELECT * FROM employee_info LIMIT 3 OFFSET 2;
+-------------+---------------+------+--------+--------+
| employee_id | employee_name | age | gender | salary |
+-------------+---------------+------+--------+--------+
| e003 | David | 26 | male | 9000 |
| e004 | Kitty | 30 | female | 11000 |
| e005 | Allen | 24 | male | 5500 |
+-------------+---------------+------+--------+--------+
3 rows in set (0.00 sec)
1.6 ORDER BY 与 LIMIT 结合的妙用
现在有一张学生成绩表,如下所示:
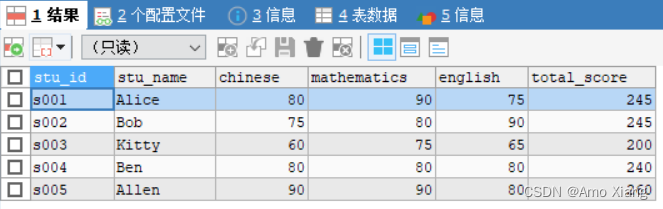
创建表并插入数据,代码如下:
mysql> DROP TABLE IF EXISTS student_score;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> CREATE TABLE student_score (
-> stu_id VARCHAR (8),
-> stu_name VARCHAR (8),
-> chinese INT,
-> mathematics INT,
-> english INT,
-> total_score INT
-> );
Query OK, 0 rows affected (0.02 sec)
mysql> INSERT INTO student_score (
-> stu_id,
-> stu_name,
-> chinese,
-> mathematics,
-> english,
-> total_score
-> ) VALUE ('s001', 'Alice', 80, 90, 75, 245),
-> ('s002', 'Bob', 75, 80, 90, 245),
-> ('s003', 'Kitty', 60, 75, 65, 200),
-> ('s004', 'Ben', 80, 80, 80, 240),
-> ('s005', 'Allen', 90, 90, 80, 260);
Query OK, 5 rows affected (0.00 sec)
Records: 5 Duplicates: 0 Warnings: 0
【练习10】以学生成绩表为例,按照总分进行排序,并查询总分排在前2名的学生信息,如果他们的总分相同,则按照他们的数学成绩降序排列,代码如下:
mysql> SELECT
-> *
-> FROM
-> student_score
-> ORDER BY total_score DESC,
-> mathematics DESC
-> LIMIT 2;
+--------+----------+---------+-------------+---------+-------------+
| stu_id | stu_name | chinese | mathematics | english | total_score |
+--------+----------+---------+-------------+---------+-------------+
| s005 | Allen | 90 | 90 | 80 | 260 |
| s001 | Alice | 80 | 90 | 75 | 245 |
+--------+----------+---------+-------------+---------+-------------+
2 rows in set (0.00 sec)
注意:上述方法有一个小缺陷,若存在多个学生的总分并列第 2 名时,则只能找出一条记录,例如这里的 Bob 的总分和 Alice 的总分相同,应该并列第 2 名。
二、过滤数据,选你所想
创建商品进货信息表并向表中插入数据,代码如下:
mysql> DROP TABLE IF EXISTS purchase_info;
Query OK, 0 rows affected (0.01 sec)
--
mysql> CREATE TABLE purchase_info (
-> commodity_id VARCHAR (8),
-> category VARCHAR (16),
-> colour VARCHAR (16),
-> purchase_quantity INT,
-> purchase_date DATE
-> );
Query OK, 0 rows affected (0.01 sec)
-- commodity_id: 商品ID category 商品类别 colour 商品颜色 purchase_quantity 采购数量 purchase_date 采购日期
mysql> INSERT INTO
-> purchase_info
-> (commodity_id,category,colour,purchase_quantity,purchase_date)
-> VALUES ('c001','clothing','black',150,'2020-04-25')
-> ,('c002','clothing','white',50,'2020-04-05')
-> ,('c003','shoes','white',500,'2020-03-23')
-> ,('c004','shoes','red',200,'2020-04-07')
-> ,('c005','clothing','blue',120,'2020-04-15');
Query OK, 5 rows affected (0.00 sec)
Records: 5 Duplicates: 0 Warnings: 0
查看 purchase_info 表:
mysql> SELECT * FROM purchase_info;
+--------------+----------+--------+-------------------+---------------+
| commodity_id | category | colour | purchase_quantity | purchase_date |
+--------------+----------+--------+-------------------+---------------+
| c001 | clothing | black | 150 | 2020-04-25 |
| c002 | clothing | white | 50 | 2020-04-05 |
| c003 | shoes | white | 500 | 2020-03-23 |
| c004 | shoes | red | 200 | 2020-04-07 |
| c005 | clothing | blue | 120 | 2020-04-15 |
+--------------+----------+--------+-------------------+---------------+
5 rows in set (0.00 sec)
在查询时,通常需要对查询结果进行筛选。语法格式:
WHERE 查询条件
查询条件可以是:
① 带比较运算符和逻辑运算符的查询条件
【练习11】以purchase_info表为例,查询商品类别为服装(clothing)的商品记录,代码如下:
-- 其他算术运算符: > < >= <= !=/<>
mysql> SELECT * FROM purchase_info WHERE category = 'clothing';
+--------------+----------+--------+-------------------+---------------+
| commodity_id | category | colour | purchase_quantity | purchase_date |
+--------------+----------+--------+-------------------+---------------+
| c001 | clothing | black | 150 | 2020-04-25 |
| c002 | clothing | white | 50 | 2020-04-05 |
| c005 | clothing | blue | 120 | 2020-04-15 |
+--------------+----------+--------+-------------------+---------------+
3 rows in set (0.00 sec)
【练习12】以purchase_info表为例,查询商品类别为服装(clothing)且颜色为黑色(black)的商品记录,代码如下:
mysql> -- AND 并列多个筛选条件,相当于`且`的条件效果
mysql> -- 查询出来的商品记录需要同时满足商品类别为服装和商品颜色为黑色两个条件
mysql> SELECT * FROM purchase_info WHERE category = 'clothing' AND colour = 'black';
+--------------+----------+--------+-------------------+---------------+
| commodity_id | category | colour | purchase_quantity | purchase_date |
+--------------+----------+--------+-------------------+---------------+
| c001 | clothing | black | 150 | 2020-04-25 |
+--------------+----------+--------+-------------------+---------------+
1 row in set (0.00 sec)
【练习13】以purchase_info表为例,查询商品类别为服装(clothing)或者颜色为黑色(black)的商品记录,代码如下:
mysql> -- 使用 OR 完成相当于`或`的条件效果
mysql> -- 查询出来的商品记录只需要满足商品类别为服装和商品颜色为黑色两个条件中的一个条件即可
mysql> SELECT * FROM purchase_info WHERE category = 'clothing' OR colour = 'black';
+--------------+----------+--------+-------------------+---------------+
| commodity_id | category | colour | purchase_quantity | purchase_date |
+--------------+----------+--------+-------------------+---------------+
| c001 | clothing | black | 150 | 2020-04-25 |
| c002 | clothing | white | 50 | 2020-04-05 |
| c005 | clothing | blue | 120 | 2020-04-15 |
+--------------+----------+--------+-------------------+---------------+
3 rows in set (0.00 sec)
【练习14】以purchase_info表为例,查询商品类别为服装(clothing)且颜色为黑色(black)或白色(white)的商品记录,代码如下:
mysql> SELECT * FROM purchase_info WHERE category = 'clothing' AND (colour = 'black' OR colour = 'white');
+--------------+----------+--------+-------------------+---------------+
| commodity_id | category | colour | purchase_quantity | purchase_date |
+--------------+----------+--------+-------------------+---------------+
| c001 | clothing | black | 150 | 2020-04-25 |
| c002 | clothing | white | 50 | 2020-04-05 |
+--------------+----------+--------+-------------------+---------------+
2 rows in set (0.00 sec)
【练习15】以purchase_info表为例,查询采购日期在2020年4月1日之前的商品记录,代码如下:
mysql> SELECT * FROM purchase_info WHERE purchase_date < '2020-04-01';
+--------------+----------+--------+-------------------+---------------+
| commodity_id | category | colour | purchase_quantity | purchase_date |
+--------------+----------+--------+-------------------+---------------+
| c003 | shoes | white | 500 | 2020-03-23 |
+--------------+----------+--------+-------------------+---------------+
1 row in set (0.00 sec)
【练习16】以purchase_info表为例,查询采购日期在2020年4月1日到2020年4月30日(包括边界值)的商品记录,代码如下:
mysql> SELECT
-> *
-> FROM
-> purchase_info
-> WHERE purchase_date >= '2020-04-01'
-> AND purchase_date <= '2020-04-30';
+--------------+----------+--------+-------------------+---------------+
| commodity_id | category | colour | purchase_quantity | purchase_date |
+--------------+----------+--------+-------------------+---------------+
| c001 | clothing | black | 150 | 2020-04-25 |
| c002 | clothing | white | 50 | 2020-04-05 |
| c004 | shoes | red | 200 | 2020-04-07 |
| c005 | clothing | blue | 120 | 2020-04-15 |
+--------------+----------+--------+-------------------+---------------+
4 rows in set (0.00 sec)
② 带 BETWEEN AND 关键字的查询条件(BETWEEN AND 通常用于将取值限制在某个区间内)
【练习17】以purchase_info表为例,查询采购日期在2020年4月1日到2020年4月30日(包括边界值)的商品记录,代码如下:
mysql> SELECT
-> *
-> FROM
-> purchase_info
-> WHERE purchase_date BETWEEN '2020-04-01'
-> AND '2020-04-30';
+--------------+----------+--------+-------------------+---------------+
| commodity_id | category | colour | purchase_quantity | purchase_date |
+--------------+----------+--------+-------------------+---------------+
| c001 | clothing | black | 150 | 2020-04-25 |
| c002 | clothing | white | 50 | 2020-04-05 |
| c004 | shoes | red | 200 | 2020-04-07 |
| c005 | clothing | blue | 120 | 2020-04-15 |
+--------------+----------+--------+-------------------+---------------+
4 rows in set (0.00 sec)
【练习18】以purchase_info表为例,查询采购数量在100到200的商品记录,代码如下:
mysql> SELECT * FROM purchase_info WHERE purchase_quantity BETWEEN 100 AND 200;
+--------------+----------+--------+-------------------+---------------+
| commodity_id | category | colour | purchase_quantity | purchase_date |
+--------------+----------+--------+-------------------+---------------+
| c001 | clothing | black | 150 | 2020-04-25 |
| c004 | shoes | red | 200 | 2020-04-07 |
| c005 | clothing | blue | 120 | 2020-04-15 |
+--------------+----------+--------+-------------------+---------------+
3 rows in set (0.00 sec)
在使用 BETWEEN AND 时,需要注意的是,在查询精确到秒时,容易出现使用错误。创建一个包含商品 ID 和采购日期的表并插入数据,代码如下:
mysql> DROP TABLE IF EXISTS purchase_time;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> CREATE TABLE purchase_time (
-> commodity_id VARCHAR (8),
-> purchase_date DATETIME
-> );
Query OK, 0 rows affected (0.01 sec)
mysql> INSERT INTO purchase_time (commodity_id, purchase_date) VALUES
-> ('c001', '2020-04-25 14:13:38'),
-> ('c002', '2020-04-05 09:12:03'),
-> ('c003', '2020-03-23 18:00:19'),
-> ('c004', '2020-04-30 12:23:01'),
-> ('c005', '2020-05-01 08:12:41');
Query OK, 5 rows affected (0.00 sec)
Records: 5 Duplicates: 0 Warnings: 0
【练习19】以purchase_info表为例,查询采购日期在2020年4月10日到2020年4月30日的所有商品记录,代码如下:
mysql> SELECT
-> *
-> FROM
-> purchase_time
-> WHERE purchase_date BETWEEN '2020-04-10'
-> AND '2020-04-30';
+--------------+---------------------+
| commodity_id | purchase_date |
+--------------+---------------------+
| c001 | 2020-04-25 14:13:38 |
+--------------+---------------------+
1 row in set (0.00 sec)
-- 结合原始数据观察,发现查询结果并不包含2020年4月30日 12:23:01 的那条记录
-- BETWEEN 的AND后连接的日期是限制到日的,则默认为 00:00:00,所以这里右侧的边界值为2020-04-30 00:00:00 则不包含12:23:01 的那条
-- 记录
-- 正确的写法如下:
mysql> SELECT
-> *
-> FROM
-> purchase_time
-> WHERE purchase_date BETWEEN '2020-04-10: 00:00:00'
-> AND '2020-04-30 23:59:59';
+--------------+---------------------+
| commodity_id | purchase_date |
+--------------+---------------------+
| c001 | 2020-04-25 14:13:38 |
| c004 | 2020-04-30 12:23:01 |
+--------------+---------------------+
2 rows in set, 5 warnings (0.00 sec)
③ 带 IS NULL 关键字的查询条件
在商品进货信息表中插入一条含有 NULL 的数据,代码如下:
mysql> INSERT INTO purchase_info
-> (commodity_id,category,colour,purchase_quantity,purchase_date)
-> VALUES ('c007','clothing',NULL,NULL,'2020-04-15');
Query OK, 1 row affected (0.00 sec)
查看 purchase_info 表中的数据:
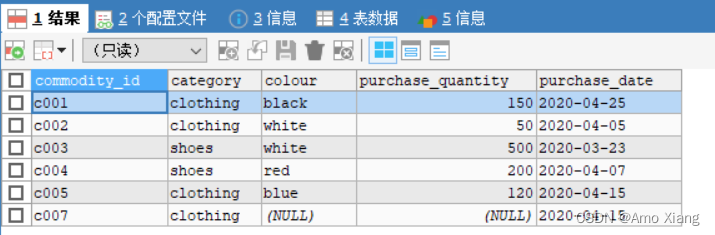
【练习20】以purchase_info表为例,筛选出colour字段为NULL的数据,代码如下:
mysql> SELECT * FROM purchase_info WHERE colour IS NULL;
+--------------+----------+--------+-------------------+---------------+
| commodity_id | category | colour | purchase_quantity | purchase_date |
+--------------+----------+--------+-------------------+---------------+
| c007 | clothing | NULL | NULL | 2020-04-15 |
+--------------+----------+--------+-------------------+---------------+
1 row in set (0.00 sec)
mysql> SELECT * FROM purchase_info WHERE colour <=> NULL;
+--------------+----------+--------+-------------------+---------------+
| commodity_id | category | colour | purchase_quantity | purchase_date |
+--------------+----------+--------+-------------------+---------------+
| c007 | clothing | NULL | NULL | 2020-04-15 |
+--------------+----------+--------+-------------------+---------------+
1 row in set (0.00 sec)
【练习21】以purchase_info表为例,筛选出colour字段不为NULL的数据,代码如下:
mysql> SELECT * FROM purchase_info WHERE colour IS NOT NULL;
+--------------+----------+--------+-------------------+---------------+
| commodity_id | category | colour | purchase_quantity | purchase_date |
+--------------+----------+--------+-------------------+---------------+
| c001 | clothing | black | 150 | 2020-04-25 |
| c002 | clothing | white | 50 | 2020-04-05 |
| c003 | shoes | white | 500 | 2020-03-23 |
| c004 | shoes | red | 200 | 2020-04-07 |
| c005 | clothing | blue | 120 | 2020-04-15 |
+--------------+----------+--------+-------------------+---------------+
5 rows in set (0.00 sec)
【练习22】以purchase_info表为例,对包含NULL的purchase_quantity字段进行排序,并且分别使用升序和降序排列,代码如下:
-- 注意: 在默认情况下,MySQL排序显示NULL最小
mysql> SELECT * FROM purchase_info ORDER BY purchase_quantity;
+--------------+----------+--------+-------------------+---------------+
| commodity_id | category | colour | purchase_quantity | purchase_date |
+--------------+----------+--------+-------------------+---------------+
| c007 | clothing | NULL | NULL | 2020-04-15 |
| c002 | clothing | white | 50 | 2020-04-05 |
| c005 | clothing | blue | 120 | 2020-04-15 |
| c001 | clothing | black | 150 | 2020-04-25 |
| c004 | shoes | red | 200 | 2020-04-07 |
| c003 | shoes | white | 500 | 2020-03-23 |
+--------------+----------+--------+-------------------+---------------+
6 rows in set (0.00 sec)
mysql> SELECT * FROM purchase_info ORDER BY purchase_quantity DESC;
+--------------+----------+--------+-------------------+---------------+
| commodity_id | category | colour | purchase_quantity | purchase_date |
+--------------+----------+--------+-------------------+---------------+
| c003 | shoes | white | 500 | 2020-03-23 |
| c004 | shoes | red | 200 | 2020-04-07 |
| c001 | clothing | black | 150 | 2020-04-25 |
| c005 | clothing | blue | 120 | 2020-04-15 |
| c002 | clothing | white | 50 | 2020-04-05 |
| c007 | clothing | NULL | NULL | 2020-04-15 |
+--------------+----------+--------+-------------------+---------------+
6 rows in set (0.00 sec)
④ 带 IN 关键字的查询条件
【练习23】以purchase_info表为例,查询商品进货信息表中商品颜色为黑色、白色和蓝色的商品记录,代码如下:
mysql> SELECT * FROM purchase_info WHERE colour='black' OR colour='white' OR colour='blue';
+--------------+----------+--------+-------------------+---------------+
| commodity_id | category | colour | purchase_quantity | purchase_date |
+--------------+----------+--------+-------------------+---------------+
| c001 | clothing | black | 150 | 2020-04-25 |
| c002 | clothing | white | 50 | 2020-04-05 |
| c003 | shoes | white | 500 | 2020-03-23 |
| c005 | clothing | blue | 120 | 2020-04-15 |
+--------------+----------+--------+-------------------+---------------+
4 rows in set (0.00 sec)
-- 使用 IN 关键字进行简化
mysql> SELECT * FROM purchase_info WHERE colour IN ('black', 'white', 'blue');
+--------------+----------+--------+-------------------+---------------+
| commodity_id | category | colour | purchase_quantity | purchase_date |
+--------------+----------+--------+-------------------+---------------+
| c001 | clothing | black | 150 | 2020-04-25 |
| c002 | clothing | white | 50 | 2020-04-05 |
| c003 | shoes | white | 500 | 2020-03-23 |
| c005 | clothing | blue | 120 | 2020-04-15 |
+--------------+----------+--------+-------------------+---------------+
4 rows in set (0.00 sec)
【练习24】以purchase_info表为例,查询商品进货信息表中商品颜色不为黑色、白色和蓝色(为其他颜色)的商品记录,代码如下:
mysql> SELECT * FROM purchase_info WHERE colour NOT IN ('black', 'white', 'blue');
+--------------+----------+--------+-------------------+---------------+
| commodity_id | category | colour | purchase_quantity | purchase_date |
+--------------+----------+--------+-------------------+---------------+
| c004 | shoes | red | 200 | 2020-04-07 |
+--------------+----------+--------+-------------------+---------------+
1 row in set (0.00 sec)
【练习25】以purchase_info表为例,查询出除红色外的颜色且颜色信息不为空的商品记录,代码如下:
-- 错误写法
mysql> SELECT * FROM purchase_info WHERE colour NOT IN ('red', NULL);
Empty set (0.00 sec)
mysql> SELECT * FROM purchase_info WHERE colour <> 'red' AND colour IS NOT NULL;
+--------------+----------+--------+-------------------+---------------+
| commodity_id | category | colour | purchase_quantity | purchase_date |
+--------------+----------+--------+-------------------+---------------+
| c001 | clothing | black | 150 | 2020-04-25 |
| c002 | clothing | white | 50 | 2020-04-05 |
| c003 | shoes | white | 500 | 2020-03-23 |
| c005 | clothing | blue | 120 | 2020-04-15 |
+--------------+----------+--------+-------------------+---------------+
4 rows in set (0.00 sec)
⑤ 带 LIKE 关键字的查询条件等
创建一张员工联系方式表并插入数据,代码如下:
mysql> DROP TABLE IF EXISTS contact_info;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> CREATE TABLE contact_info (
-> employee_id VARCHAR (8),
-> employee_name VARCHAR (8),
-> email VARCHAR (32)
-> );
Query OK, 0 rows affected (0.01 sec)
mysql>
mysql> INSERT INTO contact_info (employee_id, employee_name, email) VALUE ('e001', '王乐', '12345@qq.com'),
-> ('e002', '张三', '88888@163.com'),
-> (
-> 'e003',
-> '王梦瑶',
-> 'wangmengyao@163.com'
-> ),
-> (
-> 'e004',
-> '李四',
-> 'lisi001@qq.com'
-> );
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
查看 contact_info 表中的数据,如下图所示:
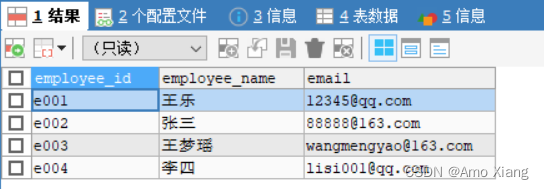
【练习26】以contact_info表为例,查询使用163邮箱的员工信息,代码如下:
-- %: 匹配零到多个字符
mysql> SELECT * FROM contact_info WHERE email LIKE '%163.com';
+-------------+---------------+---------------------+
| employee_id | employee_name | email |
+-------------+---------------+---------------------+
| e002 | 张三 | 88888@163.com |
| e003 | 王梦瑶 | wangmengyao@163.com |
+-------------+---------------+---------------------+
2 rows in set (0.00 sec)
【练习27】以contact_info表为例,查询个人邮箱中包含8这个数字的员工信息,代码如下:
mysql> SELECT * FROM contact_info WHERE email LIKE '%8%';
+-------------+---------------+---------------+
| employee_id | employee_name | email |
+-------------+---------------+---------------+
| e002 | 张三 | 88888@163.com |
+-------------+---------------+---------------+
1 row in set (0.00 sec)
【练习28】以contact_info表为例,查询姓王的员工信息,代码如下:
mysql> SELECT * FROM contact_info WHERE employee_name LIKE '王%';
+-------------+---------------+---------------------+
| employee_id | employee_name | email |
+-------------+---------------+---------------------+
| e001 | 王乐 | 12345@qq.com |
| e003 | 王梦瑶 | wangmengyao@163.com |
+-------------+---------------+---------------------+
2 rows in set (0.00 sec)
【练习29】以contact_info表为例,查询姓王且姓名为两个字的员工信息,代码如下:
mysql> SELECT * FROM contact_info WHERE employee_name LIKE '王_';
+-------------+---------------+--------------+
| employee_id | employee_name | email |
+-------------+---------------+--------------+
| e001 | 王乐 | 12345@qq.com |
+-------------+---------------+--------------+
1 row in set (0.00 sec)
-- 姓名为三个字且姓王的
mysql> SELECT * FROM contact_info WHERE employee_name LIKE '王__';
+-------------+---------------+---------------------+
| employee_id | employee_name | email |
+-------------+---------------+---------------------+
| e003 | 王梦瑶 | wangmengyao@163.com |
+-------------+---------------+---------------------+
1 row in set (0.00 sec)
补充:复杂但精确的正则表达式。
正则表达式 说明
^ 匹配字符串的开始位置
$ 匹配字符串的结束位置
. 匹配任何字符
[xyz] 匹配括号内的任意单个字符
[m-n] 匹配m到n的任意单个字符,如[0-9]、[a-z]、[A-Z]
* 匹配0或多次前面的字符
+ 匹配1或多次前面的字符
? 匹配0或1次前面的字符
x|y 匹配x或y
{m} 匹配m次前面的字符
{m,} 匹配大于或等于m次前面的字符
{m,n} 匹配m到n次前面的字符
{0,m} 匹配О到m次前面的字符
(pattern) 括号中的pattern是一个正则表达式,用于匹配指定pattern模式的一个表达式
【练习30】以contact_info表为例,查询个人邮箱至少包含3个连续的8的员工信息,代码如下:
-- 正则表达式的常用方式为:字段名 REGEXP 匹配模式
-- ps: 正则表达式的设计十分精妙,可以多借鉴和探索
mysql> SELECT * FROM contact_info WHERE email REGEXP '8{3,}';
+-------------+---------------+---------------+
| employee_id | employee_name | email |
+-------------+---------------+---------------+
| e002 | 张三 | 88888@163.com |
+-------------+---------------+---------------+
1 row in set (0.00 sec)
【练习31】以contact_info表为例,查询姓王或姓李的员工信息,代码如下:
mysql> SELECT * FROM contact_info WHERE employee_name REGEXP '^[王|李]';
+-------------+---------------+---------------------+
| employee_id | employee_name | email |
+-------------+---------------+---------------------+
| e001 | 王乐 | 12345@qq.com |
| e003 | 王梦瑶 | wangmengyao@163.com |
| e004 | 李四 | lisi001@qq.com |
+-------------+---------------+---------------------+
3 rows in set (0.00 sec)
【练习32】以contact_info表为例,查询个人邮箱中符号@之前含有任意英文字母的员工信息,代码如下:
mysql> SELECT * FROM contact_info WHERE email REGEXP '[A-Za-z].*@';
+-------------+---------------+---------------------+
| employee_id | employee_name | email |
+-------------+---------------+---------------------+
| e003 | 王梦瑶 | wangmengyao@163.com |
| e004 | 李四 | lisi001@qq.com |
+-------------+---------------+---------------------+
2 rows in set (0.00 sec)
三、计算字段真奇妙
创建地址信息表并插入数据,代码如下:
mysql> DROP TABLE IF EXISTS address_info;
Query OK, 0 rows affected, 1 warning (0.00 sec)
-- exact_address: 具体地址 city: 城市 scenic_spot: 景点名称
mysql> CREATE TABLE address_info (
-> address_id VARCHAR (8),
-> scenic_spot VARCHAR (8),
-> city VARCHAR (8),
-> exact_address VARCHAR (24)
-> );
Query OK, 0 rows affected (0.01 sec)
mysql>
mysql> INSERT address_info (address_id,scenic_spot,city,exact_address)
-> VALUES ('a001','顾村公园','上海市','宝山区顾村镇')
-> ,('a002','钟楼','西安市','碑林区东大街和南大街交汇处')
-> ,('a003','迪士尼乐园','上海市','浦东新区川沙镇黄赵路 310 号')
-> ,('a004','田子坊','上海市','泰康路 210 弄')
-> ,('a005','长风公园','上海市','普陀区大渡河路 189 号');
Query OK, 5 rows affected (0.00 sec)
Records: 5 Duplicates: 0 Warnings: 0
查看 address_info 表中的数据,如下图所示:
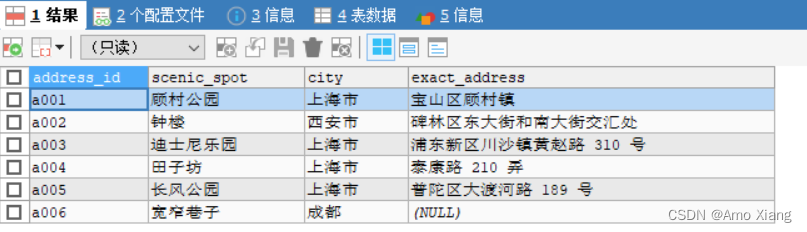
【练习33】以address_info表为例,将city和exact_address组合在一起得到详细地址,代码如下:
mysql> SELECT address_id,CONCAT(city,exact_address) FROM address_info;
+------------+-----------------------------------+
| address_id | CONCAT(city,exact_address) |
+------------+-----------------------------------+
| a001 | 上海市宝山区顾村镇 |
| a002 | 西安市碑林区东大街和南大街交汇处 |
| a003 | 上海市浦东新区川沙镇黄赵路 310 号 |
| a004 | 上海市泰康路 210 弄 |
| a005 | 上海市普陀区大渡河路 189 号 |
+------------+-----------------------------------+
5 rows in set (0.00 sec)
mysql> -- 在原始表中插入一条含有NULL的记录
mysql> INSERT INTO
-> address_info (address_id,scenic_spot,city,exact_address)
-> VALUE ('a006','宽窄巷子','成都',NULL);
Query OK, 1 row affected (0.00 sec)
mysql> SELECT address_id,CONCAT(city,exact_address) FROM address_info;
-- CONCAT 函数对包含NULL的数据进行拼接时,结果为NULL
+------------+-----------------------------------+
| address_id | CONCAT(city,exact_address) |
+------------+-----------------------------------+
| a001 | 上海市宝山区顾村镇 |
| a002 | 西安市碑林区东大街和南大街交汇处 |
| a003 | 上海市浦东新区川沙镇黄赵路 310 号 |
| a004 | 上海市泰康路 210 弄 |
| a005 | 上海市普陀区大渡河路 189 号 |
| a006 | NULL |
+------------+-----------------------------------+
6 rows in set (0.00 sec)
【练习34】以address_info表为例,将city和exact_address组合在一起得到详细地址,并将拼接结果字段取名为full_address,代码如下:
mysql> SELECT address_id,CONCAT(city,exact_address) AS 'full_address' FROM address_info;
+------------+-----------------------------------+
| address_id | full_address |
+------------+-----------------------------------+
| a001 | 上海市宝山区顾村镇 |
| a002 | 西安市碑林区东大街和南大街交汇处 |
| a003 | 上海市浦东新区川沙镇黄赵路 310 号 |
| a004 | 上海市泰康路 210 弄 |
| a005 | 上海市普陀区大渡河路 189 号 |
| a006 | NULL |
+------------+-----------------------------------+
6 rows in set (0.00 sec)
-- 省略AS的写法
mysql> SELECT address_id,CONCAT(city,exact_address) 'full_address' FROM address_info;
+------------+-----------------------------------+
| address_id | full_address |
+------------+-----------------------------------+
| a001 | 上海市宝山区顾村镇 |
| a002 | 西安市碑林区东大街和南大街交汇处 |
| a003 | 上海市浦东新区川沙镇黄赵路 310 号 |
| a004 | 上海市泰康路 210 弄 |
| a005 | 上海市普陀区大渡河路 189 号 |
| a006 | NULL |
+------------+-----------------------------------+
6 rows in set (0.00 sec)
-- 省略AS与引号
mysql> SELECT address_id,CONCAT(city,exact_address) full_address FROM address_info;
+------------+-----------------------------------+
| address_id | full_address |
+------------+-----------------------------------+
| a001 | 上海市宝山区顾村镇 |
| a002 | 西安市碑林区东大街和南大街交汇处 |
| a003 | 上海市浦东新区川沙镇黄赵路 310 号 |
| a004 | 上海市泰康路 210 弄 |
| a005 | 上海市普陀区大渡河路 189 号 |
| a006 | NULL |
+------------+-----------------------------------+
6 rows in set (0.00 sec)
创建一张购物清单表并插入数据,代码如下:
mysql> DROP TABLE IF EXISTS shopping_list;
Query OK, 0 rows affected (0.01 sec)
mysql> CREATE TABLE shopping_list (
-> commodity_id VARCHAR (8),
-> item_pricing INT,
-> purchase_quantity INT
-> );
Query OK, 0 rows affected (0.01 sec)
mysql>
mysql> INSERT shopping_list (commodity_id,item_pricing,purchase_quantity)
-> VALUES ('c001',100,10)
-> ,('c001',500,1)
-> ,('c001',50,2)
-> ,('c001',2000,1)
-> ,('c001',150,5);
Query OK, 5 rows affected (0.00 sec)
Records: 5 Duplicates: 0 Warnings: 0
查看 shopping_list 表中的数据:
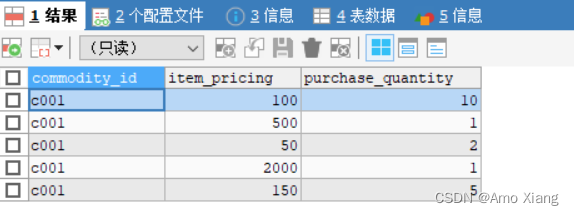
【练习35】以shopping_list表为例,计算得到每种商品的总价,代码如下:
mysql> SELECT *, item_pricing * purchase_quantity AS total_price FROM shopping_list;
+--------------+--------------+-------------------+-------------+
| commodity_id | item_pricing | purchase_quantity | total_price |
+--------------+--------------+-------------------+-------------+
| c001 | 100 | 10 | 1000 |
| c001 | 500 | 1 | 500 |
| c001 | 50 | 2 | 100 |
| c001 | 2000 | 1 | 2000 |
| c001 | 150 | 5 | 750 |
+--------------+--------------+-------------------+-------------+
5 rows in set (0.00 sec)
四、常用的聚合函数
聚合函数作用的对象是某字段的多行数据,返回的是单个值。常用的聚合函数如下:
AVG() 返回某列的平均值
SUM() 返回某列的数据之和
COUNT() 返回某列的行数
MAX() 返回某列的最大值
MIN() 返回某列的最小值
创建一张商品价格表并插入数据,代码如下:
mysql> DROP TABLE IF EXISTS goods_price;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> CREATE TABLE goods_price (
-> goods_id VARCHAR (8),
-> goods_price INT
-> );
Query OK, 0 rows affected (0.01 sec)
mysql>
mysql> INSERT INTO
-> goods_price (goods_id,goods_price)
-> VALUE ('g001',100)
-> ,('g002',2000)
-> ,('g003',500)
-> ,('g004',600)
-> ,('g005',80);
Query OK, 5 rows affected (0.00 sec)
Records: 5 Duplicates: 0 Warnings: 0
查看 goods_price 表中的数据,如下图所示:
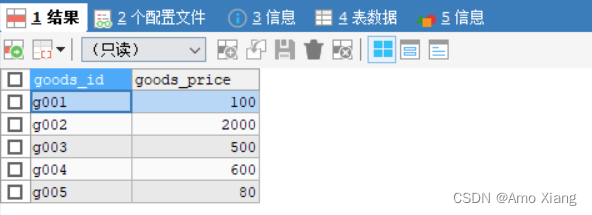
【练习36】以goods_price表为例,查询商品的平均价格,代码如下:
mysql> SELECT AVG(goods_price) FROM goods_price;
+------------------+
| AVG(goods_price) |
+------------------+
| 656.0000 |
+------------------+
1 row in set (0.00 sec
-- 插入一条商品价格为空的数据
mysql> INSERT INTO
-> goods_price (goods_id,goods_price)
-> VALUE ('g006',NULL);
Query OK, 1 row affected (0.00 sec)
mysql> SELECT AVG(goods_price) FROM goods_price;
-- 使用AVG()函数计算得到的结果没有发生变化,因为AVG函数计算时会忽略空值
-- 与AVG函数相同,SUM()、MAX()、MIN()函数在计算时也会忽略空值
+------------------+
| AVG(goods_price) |
+------------------+
| 656.0000 |
+------------------+
1 row in set (0.00 sec)
【练习37】以goods_price表为例,查询商品的价格总和,代码如下:
mysql> SELECT SUM(goods_price) FROM goods_price;
+------------------+
| SUM(goods_price) |
+------------------+
| 3280 |
+------------------+
1 row in set (0.00 sec)
【练习38】以goods_price表为例,查询商品的最高价格,代码如下:
mysql> SELECT MAX(goods_price) FROM goods_price;
+------------------+
| MAX(goods_price) |
+------------------+
| 2000 |
+------------------+
1 row in set (0.00 sec)
【练习39】以goods_price表为例,查询商品的最低价格,代码如下:
mysql> SELECT MIN(goods_price) FROM goods_price;
+------------------+
| MIN(goods_price) |
+------------------+
| 80 |
+------------------+
1 row in set (0.00 sec)
【练习40】以goods_price表为例,对表中的行进行计数,代码如下:
-- count(*)对表中的行进行计数,不管表列中包含的是空值(NULL)还是非空值
mysql> SELECT COUNT(*) FROM goods_price;
+----------+
| COUNT(*) |
+----------+
| 6 |
+----------+
1 row in set (0.00 sec)
-- -- count(列名)对特定列中有值的行计数,统计出的数量是忽略NULL后得出的
mysql> SELECT COUNT(goods_price) FROM goods_price;
+--------------------+
| COUNT(goods_price) |
+--------------------+
| 5 |
+--------------------+
1 row in set (0.00 sec)
创建一张商品品类表并插入数据,代码如下:
mysql> DROP TABLE IF EXISTS goods_category;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> CREATE TABLE goods_category (
-> goods_id VARCHAR (8),
-> category VARCHAR (8)
-> );
Query OK, 0 rows affected (0.01 sec)
mysql>
mysql> INSERT INTO goods_category (goods_id,category)
-> VALUES ('g001','shoes')
-> ,('g002','shoes')
-> ,('g003','skirt')
-> ,('g004','skirt')
-> ,('g005','hat');
Query OK, 5 rows affected (0.00 sec)
Records: 5 Duplicates: 0 Warnings: 0
查看 goods_category 表中的数据,如下图所示:
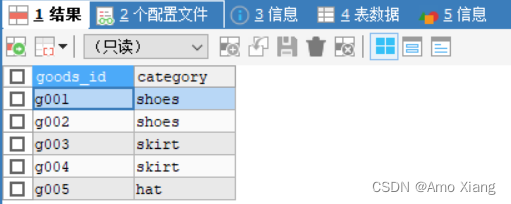
【练习41】以goods_category表为例,统计有多少种商品品类,代码如下:
mysql> SELECT *,COUNT(DISTINCT category) FROM goods_category;
+----------+----------+--------------------------+
| goods_id | category | COUNT(DISTINCT category) |
+----------+----------+--------------------------+
| g001 | shoes | 3 |
+----------+----------+--------------------------+
1 row in set (0.00 sec)
五、分组的意义
语法格式:
GROUP BY 字段1,字段2,...,字段n;
-- 当存在GROUP BY时,使用SELECT查询出来的字段必须出现在GROUP BY之后或者以聚合函数的形式出现
【练习42】以purchase_info表为例,统计不同类别商品的平均进货量,代码如下:
mysql> -- 使用group by category 表示根据category列分组,然后计算每组的AVG(purchase_quantity)
mysql> SELECT category,AVG(purchase_quantity) AS avg_purchase_quantity FROM purchase_info GROUP BY category;
+----------+-----------------------+
| category | avg_purchase_quantity |
+----------+-----------------------+
| clothing | 106.6667 |
| shoes | 350.0000 |
+----------+-----------------------+
2 rows in set (0.00 sec)
【练习43】以purchase_info表为例,同时根据category列和colour列分组,代码如下:
mysql> SELECT
-> category,
-> colour,
-> AVG (purchase_quantity)
-> FROM
-> purchase_info
-> GROUP BY category,
-> colour;
-- 根据多列分组,即多列取值都相同则为一组,purchase_info表中,由于没有category和colour列值都相同
-- 的记录,因此根据这两列分组统计之后的数据条数还是和原始表的数据条数相等,为6条
+----------+--------+-------------------------+
| category | colour | AVG (purchase_quantity) |
+----------+--------+-------------------------+
| clothing | black | 150.0000 |
| clothing | white | 50.0000 |
| shoes | white | 500.0000 |
| shoes | red | 200.0000 |
| clothing | blue | 120.0000 |
| clothing | NULL | NULL |
+----------+--------+-------------------------+
6 rows in set (0.00 sec)
【练习44】以purchase_info表为例,按照商品类别分组后,组成员个数大于3的平均进货量,代码如下:
-- HAVING: 对分组过后的组过滤可以使用HAVING,并且需要将其写在GROUP BY部分之后
mysql> SELECT category,AVG(purchase_quantity),COUNT(*) FROM purchase_info GROUP BY category HAVING COUNT(*) > 3;
+----------+------------------------+----------+
| category | AVG(purchase_quantity) | COUNT(*) |
+----------+------------------------+----------+
| clothing | 106.6667 | 4 |
+----------+------------------------+----------+
1 row in set (0.00 sec)
【练习45】以purchase_info表为例,查询平均进货量最高的3种商品的颜色,代码如下:
mysql> SELECT colour,AVG(purchase_quantity) FROM purchase_info GROUP BY colour ORDER BY AVG(purchase_quantity) DESC LIMIT 3;
+--------+------------------------+
| colour | AVG(purchase_quantity) |
+--------+------------------------+
| white | 275.0000 |
| red | 200.0000 |
| black | 150.0000 |
+--------+------------------------+
3 rows in set (0.00 sec)
六、SELECT 语句的执行顺序
SELECT
category,
AVG (purchase_quantity)
FROM
purchase_info
WHERE colour IS NOT NULL
GROUP BY category
HAVING COUNT (*) >= 2
ORDER BY AVG (purchase_quantity) DESC
LIMIT 1;
执行顺序为:
FROM --> WHERE --> GROUP BY --> COUNT() --> HAVING --> SELECT --> ORDER BY --> LIMIT
① 首先执行 FROM 后面的语句,明确数据来源的表。
② 然后执行 WHERE 后面的语句,对原始数据进行筛选。
③ 接着执行 GROUP BY 后面的语句,对数据进行分组。
④ 然后执行 COUNT(*) 函数,对分组后的数据进行聚合计算。
⑤ 接着执行 HAVING 后面的语句,对分组聚合后的数据进行筛选。
⑥ 然后执行 SELECT 后面的语句,对处理好的数据选择取出的部分。
⑦ 接着执行 ORDER BY 后面的语句,对最终结果进行排序。
⑧ 最后执行 LIMIT 后面的语句,显示展示的部分条目。
至此今天的学习就到此结束了,笔者在这里声明,笔者写文章只是为了学习交流,以及让更多学习数据库的读者少走一些弯路,节省时间,并不用做其他用途,如有侵权,联系博主删除即可。感谢您阅读本篇博文,希望本文能成为您编程路上的领航者。祝您阅读愉快!

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请点赞、评论、收藏一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
编码不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!