深度强化学习记录
增强学习是什么
增强学习
- 与环境交互
- 获取反馈
agent 目标是最大化累积奖励,称为期望值回馈
增强学习框架
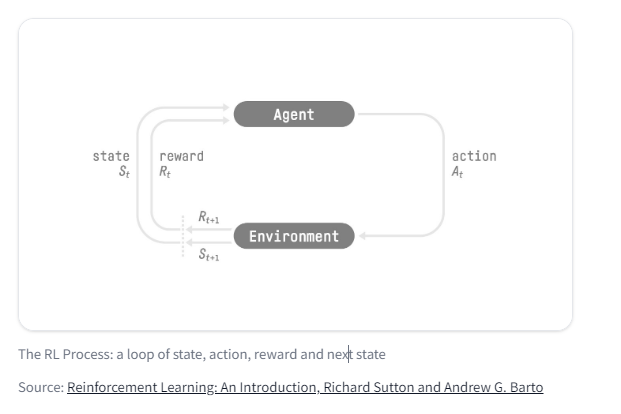
RL Process
RL process叫做Markov Decision Process (MDP)
The reward hypothesis
RL基于奖励假设,目标函数是最大化期望回归,maximize the expected cumulative reward
the Markov Property
the Markov Property 暗示agent只需要最近的状态去学习下一步采取什么动作,不考虑历史状态和行为
Observations/States Space
agent从环境中学到的信息,
- State s
一个完整的这个世界状态的描述 - Observation o
一个部分的这个世界状态的描述
Action Space
环境中所有可能动作的集合
环境来自离散或者连续空间
Rewards and the discounting
agent知道采取行动是否是好的
累积奖励:
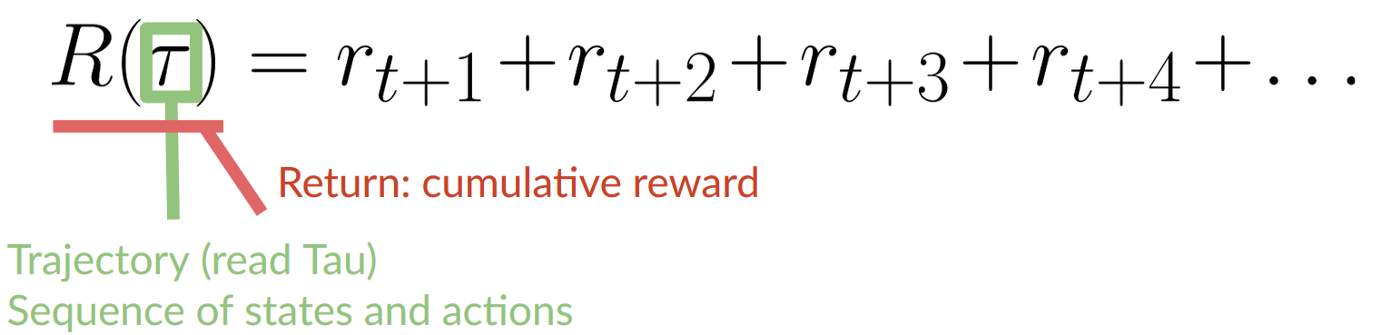
即时奖励更有可能发生,因为比起长期奖励他们更容易预测
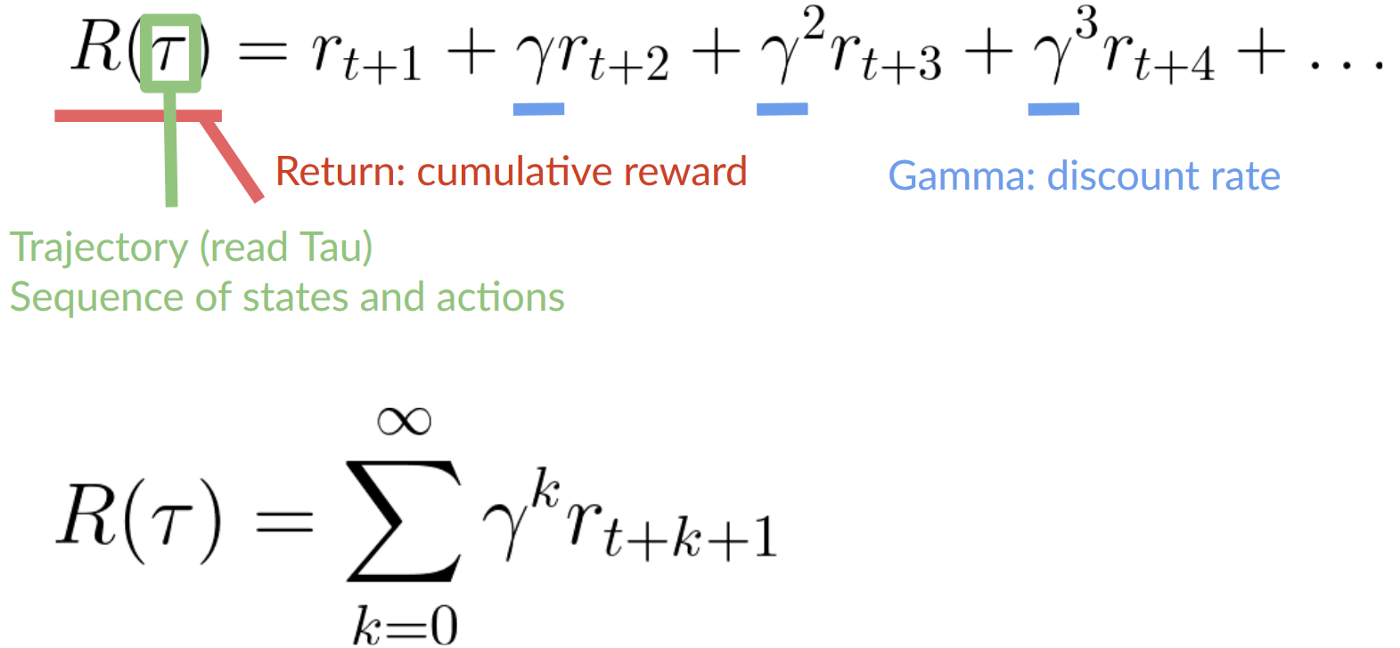
- 定义一个discount rate叫gamma,0-1之间。大多时候是0.99-0.95(gamma越大,discount越小,agent更在乎长期回归。gamma越小,discount越大,agent更关系短期回报)
- 每一个奖励会被gamma计算到时间指数步骤,未来期望奖励发生概率降低
任务类型
两种任务: episodic ,continuing
Episodic task:
有一个开始点和结束点(终止状态),an episode: a list of States, Actions, Rewards, and new States ,比如超级玛丽
Continuing tasks:
任务会一直继续,学会选择最好的策略,同时与环境交互。比如自动化股市交易,agent一直运行直到我们决定停止
The Exploration/Exploitation trade-off
- Exploration 采取随机行动探索环境,发现更多信息
- Exploitation 利用已知信息最大化奖励
我们需要平衡 多少时候去探索环境,多少时候去利用环境信息获取奖励。
必须定义一个规则帮助我们折衷
两个解决RL 问题的主要方法
换一个说法,如何建立一个RL agent最大化累积期望
The Policy π: the agent’s brain
Policy π 是Agent大脑,这个函数告诉我们,在当前状态下去采取什么行动
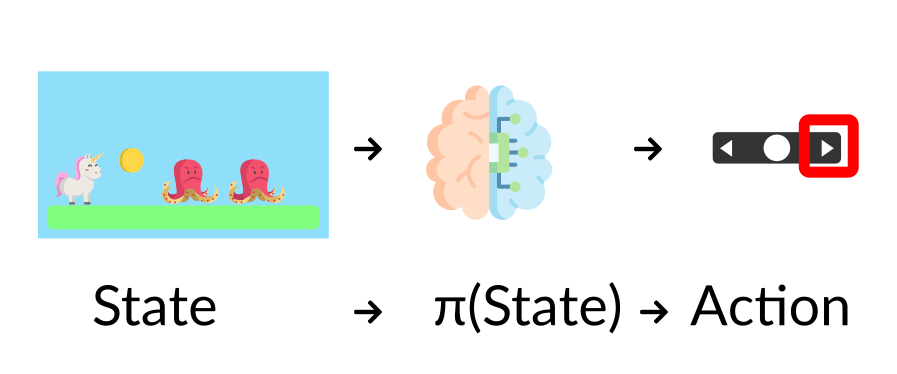
Policy 是我们想学习的函数,我们的目标是找到最优的policy π* (最大化期望回归),通过训练找到。两个训练方法:
- 直接,教给agent学习采取哪个行动,根据当前状态:Policy-Based Methods
- 间接,教给agent学习哪一个状态更有价值,然后采取行动通向更多有价值状态 :Value-Based Methods.
Policy-Based Methods
这个函数会定义每个状态到最一致行动的映射。或者说,该函数在该状态下所有可能的行动定义一个概率分布
有两种类型policies:
- 确定的 。给定状态下一直返回相同的行动的policy
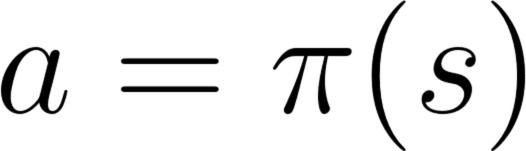
- 随机的:在行动上输出一个概率分布

Value-Based Methods
学习一个从状态映射到该状态期望值映射的价值函数
一个状态的价值是如果agent从那个状态开始,并且按照policy(带着最高价值)行动,可以获取的期望折扣
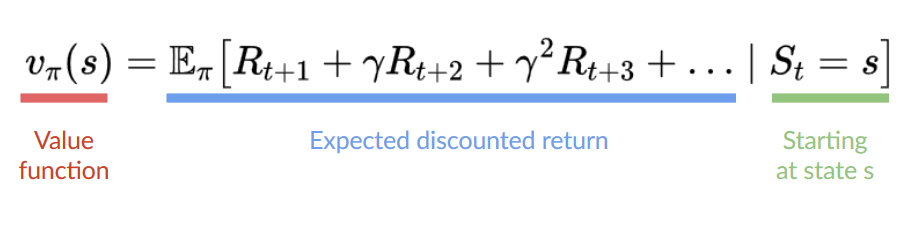
每一步选择价值函数定义的最大值,-7, then -6, then -5

UNIT0 增强学习中的deep
“deep"指的是深度学习中的网络
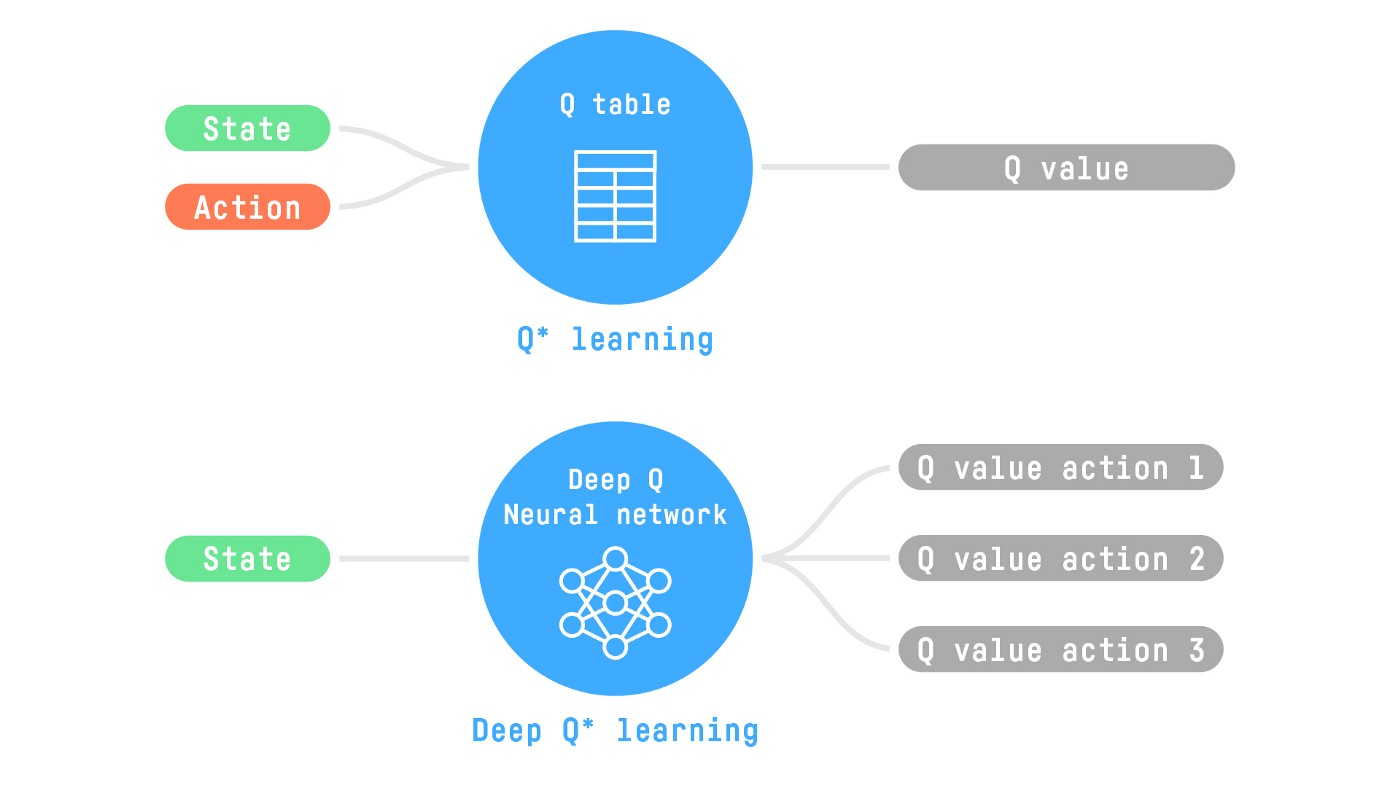
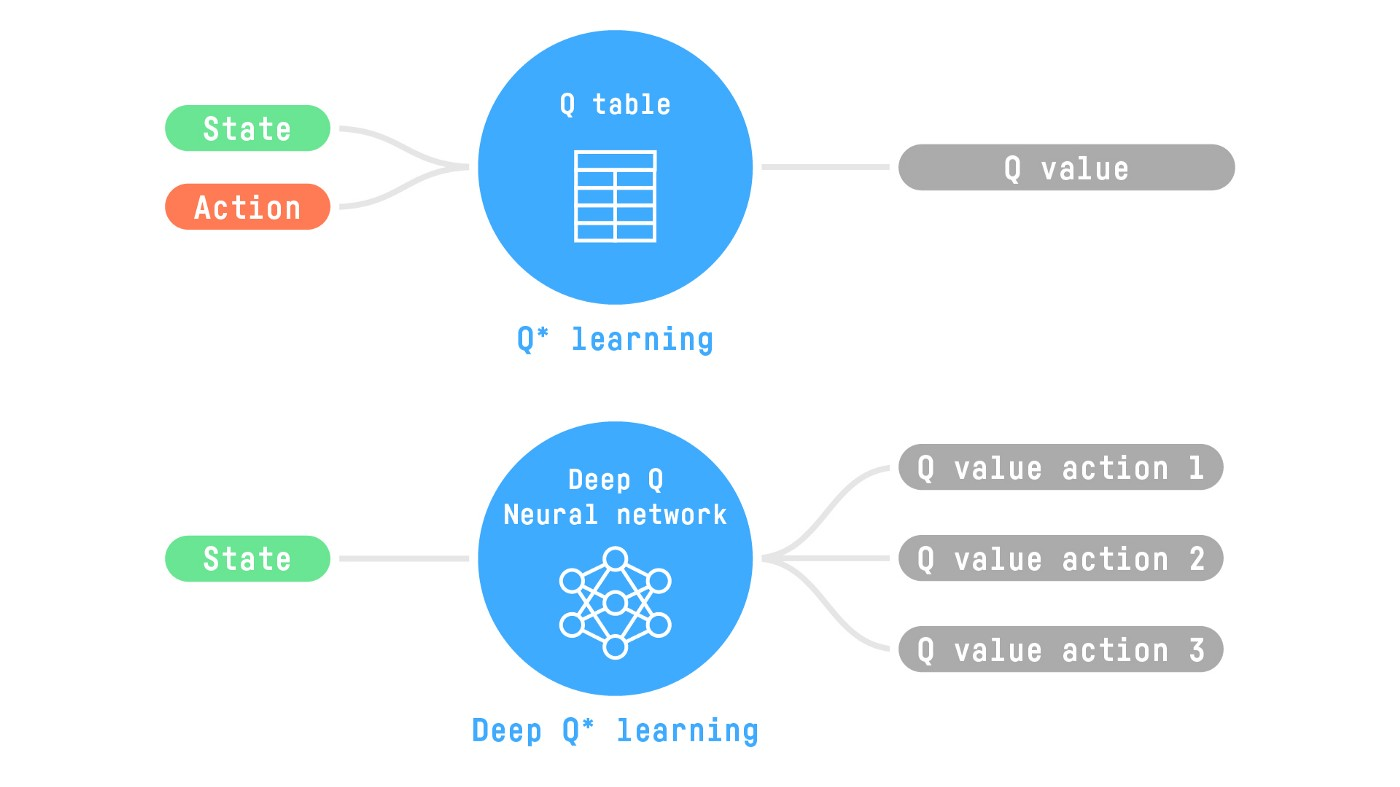
两种基于值的算法, Q-Learning和 Deep Q-Learning.
Q-Learning使用传统算法,创建一个Q表找到每一个状态对应的行动。
Deep Q-Learning 使用神经网络最大化Q值
总结
- 增强学习从行动中学习的计算方式,建立一个agent,通过试错与环境交互,收到环境奖励(正、负)作为回馈
- RL agent目标是最大化累计期望奖励
- RL 过程是一个循环,它会输出:state,action,reward,next state
- 计算累积期望奖励,需要为奖励做折扣:即时奖励更有可能发生,因为它比长期奖励更可以预测
- 解决RL问题,找到一个合适policy.
- 有两种找到最优policy方法:直接训练policy,或者训练一个价值函数可以计算每一个state期望回馈,使用函数定义policy
- 最后,说到Deep RL,因为我们引入了深度神经网络评估采取的行动(policy-based)或者评估状态价值(value-based)),所以叫做"deep"
UNIT2 介绍Q-Learning
The Bellman Equation: simplify our value estimation
Bellman 公式思想:计算每一个value作为期望回归的总和过程太长,所以我们计算即时奖励+状态的discounted value 总和作为value

Monte Carlo vs Temporal Difference Learning
两种学习策略
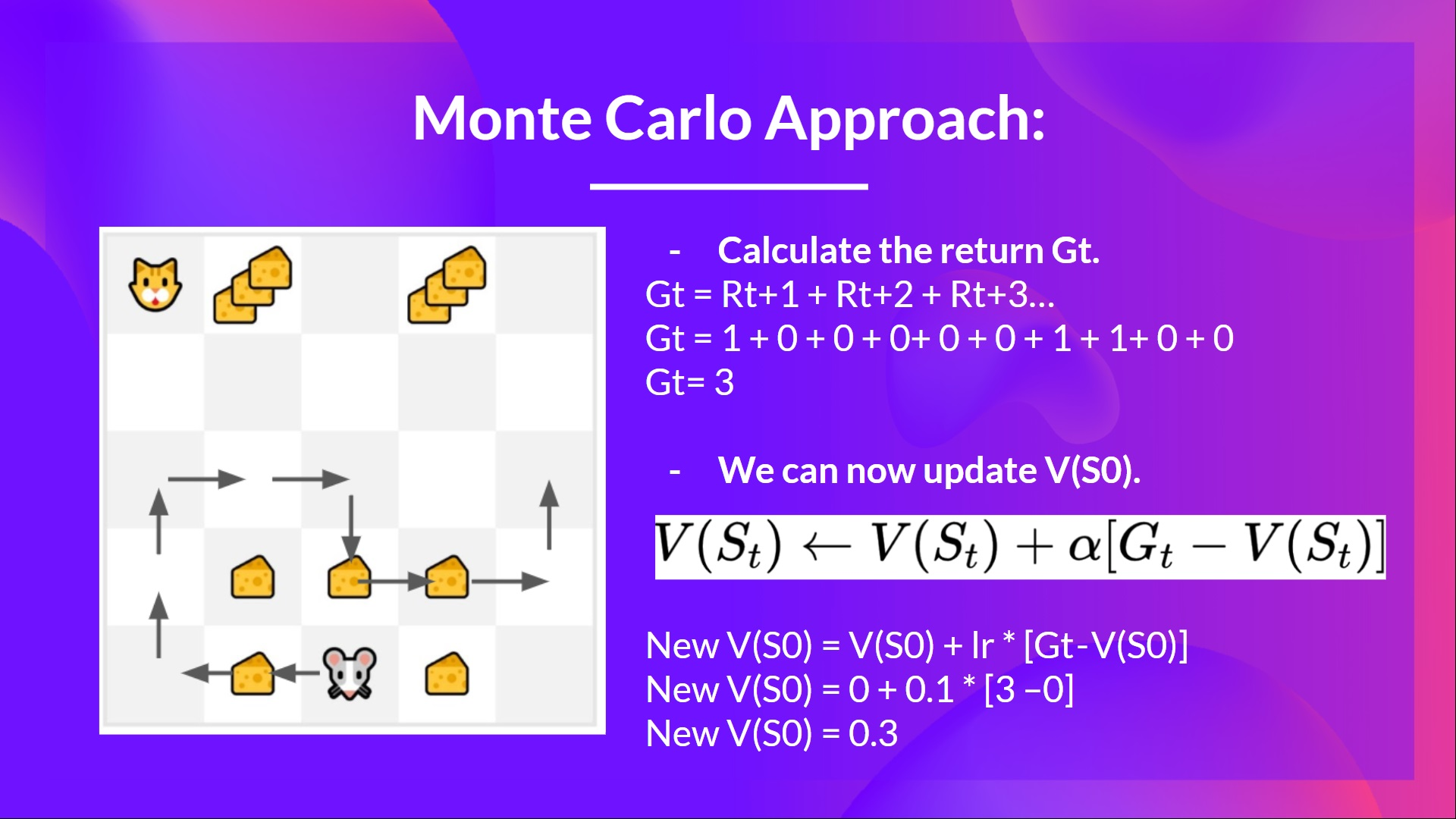
Monte Carlo 在学习前,利用完整的一个episode(表示一个智能体从开始到结束的一次交互过程,包括了环境状态、智能体的决策和行动以及最终的奖励或惩罚)
Temporal Difference 只使用一步(St,At,Rt+1,St+1)学习
Monte Carlo:在episode最后学习

Temporal Difference Learning:每一步都在学习

Q-Learning是什么?

Q-Learning is an off-policy value-based method that uses a TD approach to train its action-value function
Q-Learning是学训练Q函数方法,一个决定在特殊状态下的值,并且在按个状态下采取具体行动的函数

Q来自Quality(在state下的value)
Q-function内部有一个Q-table
Off-policy vs On-policy
Off-policy: using a different policy for acting (inference) and updating (training).
For instance, with Q-Learning, the epsilon-greedy policy (acting policy), is different from the greedy policy that is used to select the best next-state action value to update our Q-value (updating policy).
On-policy: using the same policy for acting and updating.
For instance, with Sarsa, another value-based algorithm, the epsilon-greedy policy selects the next state-action pair, not a greedy policy.

总结:
找到optimal policy两种方法:Policy-based methods. +Value-based method(The state-value function结束时返回值+The action-value function每一步返回值)

Epsilon-greedy strategy:用来平衡exploration 和 exploitation.1-epsilon概率选择最高期望值的行动,epsilon概率随机选择炫动,epsilon随着时间降低exploitation
Greedy strategy:总是选择给予当前环境的了解下最高期望值的行动,没有exploration,在未知情况下表现很差
Unit3
Deep Q-Learning 使用深度神经网络而不是Q-table采取下一步状态评估每一步的Q-values,
Q-Learning是训练Q-Function(action-value function决定了在特殊状态下的值,并且采取具体行动)的算法。
Deep Q-Learning training 可能局限于不稳定,因为结合了一个非线性Q-value函数,bootstrappong,
为了训练稳定:
- Experience Replay to make more efficient use of experiences.(use a replay buffer that saves experience samples that we can reuse during the training,By randomly sampling the experiences, we remove correlation in the observation sequences and avoid action values from oscillating or diverging catastrophically)
- Fixed Q-Target to stabilize the training.
- Double Deep Q-Learning, to handle the problem of the overestimation of Q-values.


Policy 梯度
找到最优 policy π ∗,
- value-based methods,学习价值函数
- policy-based methods
动手实践

Gym : Box2D 环境的部分。环境是一个经典的火箭轨迹优化问题
Gym 库提供了:创建RL环境接口+环境的集合 (gym-control, atari, box2D…)
Stable-Baselines3:是PyTorch增强学习算法的一系列实现,https://github.com/DLR-RM/stable-baselines3
UNIT1报错解决
!sudo apt-get update
!apt install python-opengl
!apt install ffmpeg
!apt install xvfb
!pip3 install pyvirtualdisplay
apt 改成 yum
安装xvfb报错
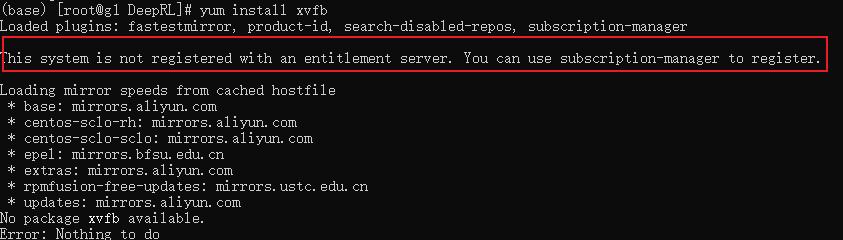
报错要注册,参考https://blog.csdn.net/maibaizhou/article/details/121047462
vim /etc/yum/pluginconf.d/subscription-manager.conf
yum search xvfb
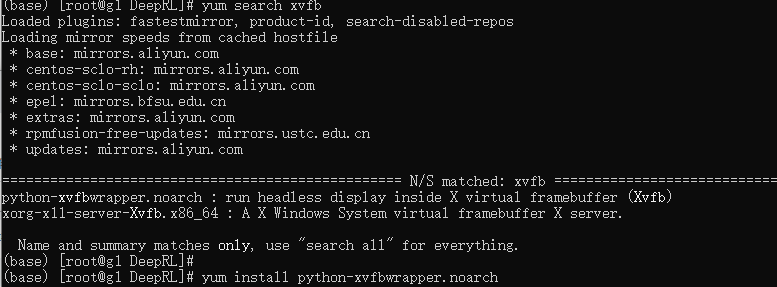
yum install python-xvfbwrapper.noarch
安装Box2D失败,gcc: error trying to exec ‘cc1plus’: execvp: No such file or directory
解决办法 :
使用命令
yum install gcc gcc-c++
参考:https://blog.csdn.net/qq_39240270/article/details/85287599
env = gym.make(“LunarLander-v2”)执行报错executing.executing.NotOneValueFound: Expected one value, found 0
pip3 install box2d box2d-kengz
报错:参数数量错误

解决:更改参数数量还是报错,重新进入python环境莫名其妙就对了
参考手册:https://www.gymlibrary.dev/environments/box2d/lunar_lander/
模型上传时报错
import gym
from stable_baselines3 import PPO
from stable_baselines3.common.vec_env import DummyVecEnv
from stable_baselines3.common.env_util import make_vec_env
from huggingface_sb3 import package_to_hub
# PLACE the variables you've just defined two cells above
# Define the name of the environment
env_id = "LunarLander-v2"
# TODO: Define the model architecture we used
model_architecture = "PPO"
## Define a repo_id
## repo_id is the id of the model repository from the Hugging Face Hub (repo_id = {organization}/{repo_name} for instance ThomasSimonini/ppo-LunarLander-v2
## CHANGE WITH YOUR REPO ID
repo_id = "DiracUniverse/ppo-LunarLander-v2" # Change with your repo id, you can't push with mine 😄
## Define the commit message
commit_message = "Upload PPO LunarLander-v2 trained agent"
# Create the evaluation env
eval_env = DummyVecEnv([lambda: gym.make(env_id)])
# PLACE the package_to_hub function you've just filled here
package_to_hub(
model=model, # Our trained model
model_name=model_name, # The name of our trained model
model_architecture=model_architecture, # The model architecture we used: in our case PPO
env_id=env_id, # Name of the environment
eval_env=eval_env, # Evaluation Environment
repo_id=repo_id, # id of the model repository from the Hugging Face Hub (repo_id = {organization}/{repo_name} for instance ThomasSimonini/ppo-LunarLander-v2
commit_message=commit_message,
)
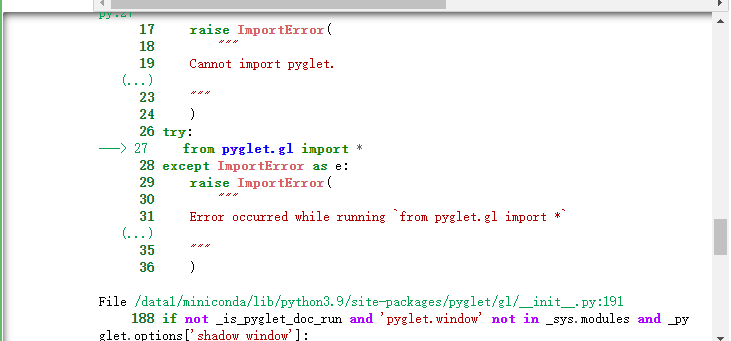
报错,需要图形化界面
CentOS7安装GUI界面及远程连接的实现
如何利用Windows 10连接远程服务器桌面
windows10远程连接centos桌面
xhost:unable to open display""的问题, 设置环境变量 export DISPLAY=:0.0
pytorch 版本不对 报错: CUDA error: CUBLAS_STATUS_EXECUTION_FAILED when calling cublasSgemm( handle, opa, opb, m, n, k, &alpha, a, lda, b, ldb, &beta, c, ldc)
解决:pip install torch==2.0.0