普通策略梯度算法原理及PyTorch实现【VPG】
有没有想过强化学习 (RL) 是如何工作的?
在本文中,我们将从头开始构建最简单的强化学习形式之一 —普通策略梯度(VPG)算法。 然后,我们将训练它完成著名的 CartPole 挑战 — 学习从左向右移动购物车以平衡杆子。 在此过程中,我们还将完成对 OpenAI 的 Spinning Up 学习资源的第一个挑战。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎
本文的代码可以在 这里 找到。
1、我们的方法
我们将通过创建一个简单的深度学习模型来解决这个问题,该模型接受观察并输出随机策略(即采取每个可能行动的概率)。
然后,我们需要做的就是通过在环境中采取行动并使用此策略来收集经验。
当我们有足够的批量经验(几个episode经验的集合)后,我们需要转向梯度下降来改进模型。 在较高层面上,我们希望增加策略的预期回报,这意味着调整权重和偏差以增加高预期回报行动的概率。 就 VPG 而言,这意味着使用策略梯度定理,该定理给出了该预期回报的梯度方程(如下所示)。
这就是全部内容了—所以让我们开始编码吧!
2、创建模型
我们将首先创建一个带有一个隐藏层的非常简单的模型。 第一个线性层从 CartPole 的观察空间获取输入特征,最后一层返回可能结果的值。
def create_model(number_observation_features: int, number_actions: int) -> nn.Module:
"""Create the MLP model
Args:
number_observation_features (int): Number of features in the (flat)
observation tensor
number_actions (int): Number of actions
Returns:
nn.Module: Simple MLP model
"""
hidden_layer_features = 32
return nn.Sequential(
nn.Linear(in_features=number_observation_features,
out_features=hidden_layer_features),
nn.ReLU(),
nn.Linear(in_features=hidden_layer_features,
out_features=number_actions),
)3、获取策略
我们还需要为每个时间步获取一个模型策略(以便我们知道如何采取行动)。 为此,我们将创建一个 get_policy 函数,该函数使用模型输出策略下每个操作的概率。 然后,我们可以返回一个分类(多项式)分布,该分布可用于选择根据这些概率随机分布的特定动作。
def get_policy(model: nn.Module, observation: np.ndarray) -> Categorical:
"""Get the policy from the model, for a specific observation
Args:
model (nn.Module): MLP model
observation (np.ndarray): Environment observation
Returns:
Categorical: Multinomial distribution parameterized by model logits
"""
observation_tensor = torch.as_tensor(observation, dtype=torch.float32)
logits = model(observation_tensor)
# Categorical will also normalize the logits for us
return Categorical(logits=logits)4、从策略中采样动作
从这个分类分布中,对于每个时间步长,我们可以对其进行采样以返回一个动作。 我们还将获得该动作的对数概率,这在稍后计算梯度时会很有用。
def get_action(policy: Categorical) -> tuple[int, float]:
"""Sample an action from the policy
Args:
policy (Categorical): Policy
Returns:
tuple[int, float]: Tuple of the action and it's log probability
"""
action = policy.sample() # Unit tensor
# Converts to an int, as this is what Gym environments require
action_int = action.item()
# Calculate the log probability of the action, which is required for
# calculating the loss later
log_probability_action = policy.log_prob(action)
return action_int, log_probability_action5、计算损失
梯度的完整推导如这里所示。 宽松地说,它是每个状态-动作对的对数概率之和乘以该对所属的整个轨迹的回报的梯度。 额外的外层和汇总若干个情节(即一批),因此我们有重要的数据。
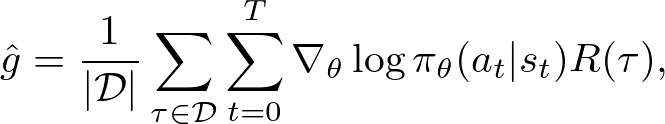
要使用 PyTorch 计算此值,我们可以做的是计算下面的伪损失,然后使用 .backward() 获取上面的梯度(注意我们刚刚删除了梯度项):
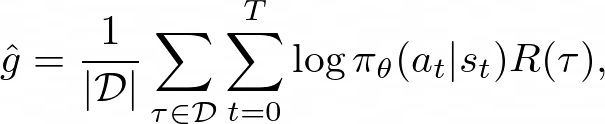
这通常被称为损失,但它并不是真正的损失,因为它不依赖于模型的性能。 它只是对于获取策略梯度有用。
def calculate_loss(epoch_log_probability_actions: torch.Tensor, epoch_action_rewards: torch.Tensor) -> float:
"""Calculate the 'loss' required to get the policy gradient
Formula for gradient at
https://spinningup.openai.com/en/latest/spinningup/rl_intro3.html#deriving-the-simplest-policy-gradient
Note that this isn't really loss - it's just the sum of the log probability
of each action times the episode return. We calculate this so we can
back-propagate to get the policy gradient.
Args:
epoch_log_probability_actions (torch.Tensor): Log probabilities of the
actions taken
epoch_action_rewards (torch.Tensor): Rewards for each of these actions
Returns:
float: Pseudo-loss
"""
return -(epoch_log_probability_actions * epoch_action_rewards).mean()6、单个epoch训练
将以上所有内容放在一起,我们现在准备好训练一个epoch了。 为此,我们只需循环播放情节(episode)即可创建批次。 在每个情节中,创建一系列可用于训练模型的动作和奖励(即经验)。
def train_one_epoch(env: gym.Env, model: nn.Module, optimizer: Optimizer, max_timesteps=5000, episode_timesteps=200) -> float:
"""Train the model for one epoch
Args:
env (gym.Env): Gym environment
model (nn.Module): Model
optimizer (Optimizer): Optimizer
max_timesteps (int, optional): Max timesteps per epoch. Note if an
episode is part-way through, it will still complete before finishing
the epoch. Defaults to 5000.
episode_timesteps (int, optional): Timesteps per episode. Defaults to 200.
Returns:
float: Average return from the epoch
"""
epoch_total_timesteps = 0
# Returns from each episode (to keep track of progress)
epoch_returns: list[int] = []
# Action log probabilities and rewards per step (for calculating loss)
epoch_log_probability_actions = []
epoch_action_rewards = []
# Loop through episodes
while True:
# Stop if we've done over the total number of timesteps
if epoch_total_timesteps > max_timesteps:
break
# Running total of this episode's rewards
episode_reward: int = 0
# Reset the environment and get a fresh observation
observation = env.reset()
# Loop through timesteps until the episode is done (or the max is hit)
for timestep in range(episode_timesteps):
epoch_total_timesteps += 1
# Get the policy and act
policy = get_policy(model, observation)
action, log_probability_action = get_action(policy)
observation, reward, done, _ = env.step(action)
# Increment the episode rewards
episode_reward += reward
# Add epoch action log probabilities
epoch_log_probability_actions.append(log_probability_action)
# Finish the action loop if this episode is done
if done == True:
# Add one reward per timestep
for _ in range(timestep + 1):
epoch_action_rewards.append(episode_reward)
break
# Increment the epoch returns
epoch_returns.append(episode_reward)
# Calculate the policy gradient, and use it to step the weights & biases
epoch_loss = calculate_loss(torch.stack(
epoch_log_probability_actions),
torch.as_tensor(
epoch_action_rewards, dtype=torch.float32)
)
epoch_loss.backward()
optimizer.step()
optimizer.zero_grad()
return np.mean(epoch_returns)7、运行算法
现在可以运行算法了。
def train(epochs=40) -> None:
"""Train a Vanilla Policy Gradient model on CartPole
Args:
epochs (int, optional): The number of epochs to run for. Defaults to 50.
"""
# Create the Gym Environment
env = gym.make('CartPole-v0')
# Use random seeds (to make experiments deterministic)
torch.manual_seed(0)
env.seed(0)
# Create the MLP model
number_observation_features = env.observation_space.shape[0]
number_actions = env.action_space.n
model = create_model(number_observation_features, number_actions)
# Create the optimizer
optimizer = Adam(model.parameters(), 1e-2)
# Loop for each epoch
for epoch in range(epochs):
average_return = train_one_epoch(env, model, optimizer)
print('epoch: %3d \t return: %.3f' % (epoch, average_return))
if __name__ == '__main__':
train()大约 40 个 epoch 后,可以看到模型已经很好地学习了环境(得分 180+/ 200):
epoch: 26 return: 118.070
epoch: 27 return: 114.659
epoch: 28 return: 135.405
epoch: 29 return: 144.000
epoch: 30 return: 143.972
epoch: 31 return: 152.091
epoch: 32 return: 166.065
epoch: 33 return: 162.613
epoch: 34 return: 166.806
epoch: 35 return: 172.933
epoch: 36 return: 173.241
epoch: 37 return: 181.071
epoch: 38 return: 186.222
epoch: 39 return: 176.793原文链接:普通策略梯度实现 - BimAnt