paddle ocr 训练数字识别模型
选择识别算法
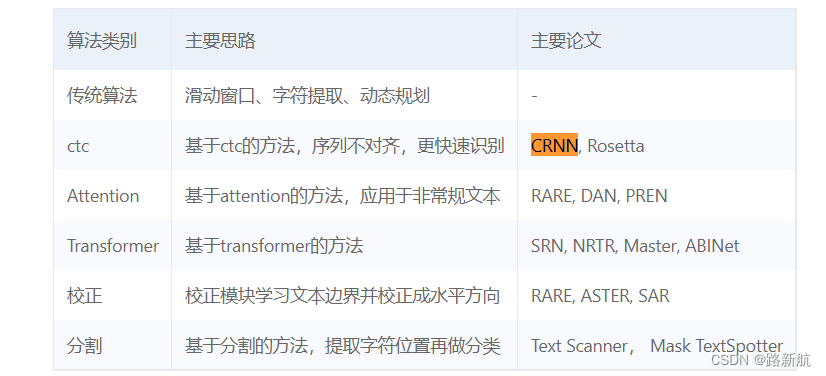

修改配置文件
复制rec_icdar15_train.yml配置文件,预训练模型用rec_mv3_none_bilstm_ctc
更改
- pretrained_model预训练模型路径
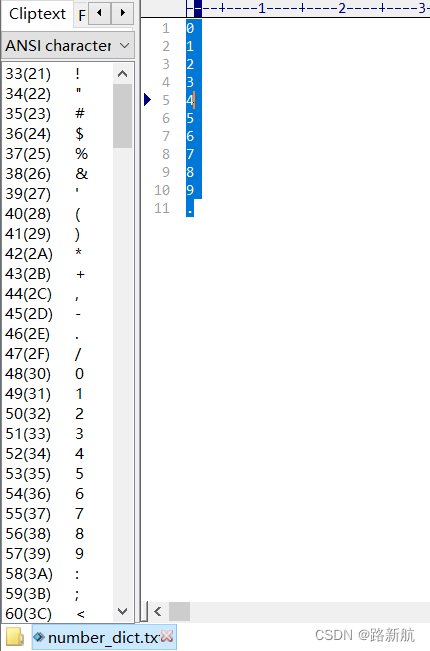
- character_dict_path字典路径,字典内容
- data_dir
- label_file_list
Global:
use_gpu: true
epoch_num: 10
log_smooth_window: 20
print_batch_step: 10000
save_model_dir: ./output/rec/number/
save_epoch_step: 5
# evaluation is run every 2000 iterations
eval_batch_step: [0, 3, 6, 9]
cal_metric_during_train: True
pretrained_model: pretrain_models/rec_mv3_none_bilstm_ctc_v2.0_train/best_accuracy
checkpoints:
save_inference_dir: ./
use_visualdl: False
infer_img: ./train_data/NUMBER/9997_448.jpg
# for data or label process
character_dict_path: ppocr/utils/number_dict.txt
max_text_length: 6
infer_mode: False
use_space_char: True
save_res_path: ./output/rec/predicts_number.txt
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
lr:
learning_rate: 0.0005
regularizer:
name: 'L2'
factor: 0
Architecture:
model_type: rec
algorithm: CRNN
Transform:
Backbone:
name: MobileNetV3
scale: 0.5
model_name: large
Neck:
name: SequenceEncoder
encoder_type: rnn
hidden_size: 96
Head:
name: CTCHead
fc_decay: 0
Loss:
name: CTCLoss
PostProcess:
name: CTCLabelDecode
Metric:
name: RecMetric
main_indicator: acc
Train:
dataset:
name: SimpleDataSet
data_dir: ./train_data/NUMBER/
label_file_list: ["./train_data/NUMBER/rec_gt_train.txt"]
transforms:
- DecodeImage: # load image
img_mode: BGR
channel_first: False
- CTCLabelEncode: # Class handling label
- RecResizeImg:
image_shape: [3, 32, 100]
- KeepKeys:
keep_keys: ['image', 'label', 'length'] # dataloader will return list in this order
loader:
shuffle: True
batch_size_per_card: 256
drop_last: True
num_workers: 12
use_shared_memory: False
Eval:
dataset:
name: SimpleDataSet
data_dir: ./train_data/NUMBER
label_file_list: ["./train_data/NUMBER/rec_gt_test.txt"]
transforms:
- DecodeImage: # load image
img_mode: BGR
channel_first: False
- CTCLabelEncode: # Class handling label
- RecResizeImg:
image_shape: [3, 32, 100]
- KeepKeys:
keep_keys: ['image', 'label', 'length'] # dataloader will return list in this order
loader:
shuffle: False
drop_last: True
batch_size_per_card: 256
num_workers: 4
use_shared_memory: False
文件格式
simple dataset以\t分割
对图像生成标签
import os
import cv2
from tqdm import tqdm
img_folder = r'xxx'
target_img_folder = r'./train_data'
img_file_list = os.listdir(img_folder)
label_list = []
def cv_show(img):
'''
展示图片
@param img:
@param name:
@return:
'''
cv2.namedWindow('name', cv2.WINDOW_KEEPRATIO) # cv2.WINDOW_NORMAL | cv2.WINDOW_KEEPRATIO
cv2.imshow('name', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
index = 1
for file in tqdm(img_file_list):
file_path = os.path.join(img_folder, file)
start_page_str = str(index)
if len(start_page_str) == 1:
start_page_str = '00' + start_page_str
elif len(start_page_str) == 2:
start_page_str = '0' + start_page_str
else:
...
if file.endswith('jpg'):
label = file.split('_')[-1].split('.')[0]
new_file_path = os.path.join(target_img_folder, str(start_page_str) +'_'+label+ '.jpg')
os.rename(file_path,new_file_path)
with open('./rec_gt_train.txt', 'a+', encoding='utf-8') as f:
f.write(str(start_page_str) +'_'+label+ '.jpg'+'\t'+label+'\n')
index += 1
dataset
dataset:
name: SimpleDataSet
data_dir: ./train_data/NUMBER
label_file_list: ["./train_data/NUMBER/xxx.txt"]

训练
python tools/train.py -c configs/rec/rec_icdar15_number_train.yml
有3万张图片,使用预训练模型,预训练模型效果:

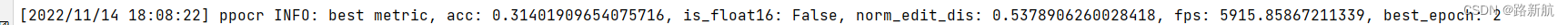
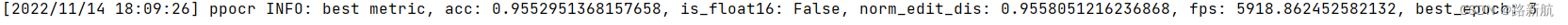

不使用训练模型,精度会差点

python tools/train.py -c configs/rec/rec_r34_vd_none_bilstm_ctc_number.yml
转成推理模型
python tools/export_model.py -c configs/rec/rec_icdar15_number_train.yml -o Global.checkpoints=./output/rec/number_mv3/best_accuracy Global.save_inference_dir=./output/rec_icdar15_number/
警告:
The shape of model params head.fc.weight [192, 12] not matched with loaded params head.fc.weight [192, 37]
因为字典改了
注意
- 测试集和训练集size大于批次
预测
预测图片:

命令行:
python ../../PaddleOCR/tools/infer/predict_rec.py --image_dir="./test_data/000_4.jpg" --rec_model_dir="../../PaddleOCR/output/recnumber_mv3_none_bilstm_ctc/" --rec_image_shape="3, 32, 100" --rec_char_dict_path="../../PaddleOCR/ppocr/utils/number_dict.txt"

原始模型
paddleocr --image_dir=“./test_data/000_4.jpg”

总结
使用不同图像尺寸 效果会变差,训练中还需要做数据增强