Flink sql join 快速入门
Flink stream join
基于窗口join
Flink 中 Window 可以将无限流切分成有限流,是处理有限流的核心组件,现在Flink 中 Window 可以是时间驱动的(Time Window),也可以是数据驱动的(Count Window)
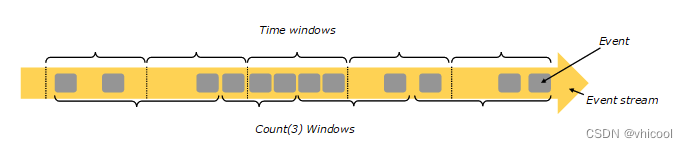
窗口连接将共享一个公key并位于同一窗口中的两个流的元素连接起来。这些窗口可以通过使用窗口赋值器来定义,并根据两个流中的元素进行计算。
然后,来自两边的元素被传递给用户定义的JoinFunction或FlatJoinFusion,用户可以在其中发出符合连接条件的结果。
stream.join(otherStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(<WindowAssigner>)
.apply(<JoinFunction>)
Tumbling window join(滚动窗口join)
滚动窗口有固定的尺寸,窗口间的元素无重复。当执行滚动窗口连接时,具有公key和公共滚动窗口的所有元素将作为成对组合进行连接(inner join)
因为这就像一个内部连接,所以一个流中的元素在其滚动窗口中没有来自另一个流的元素时,不会发出。
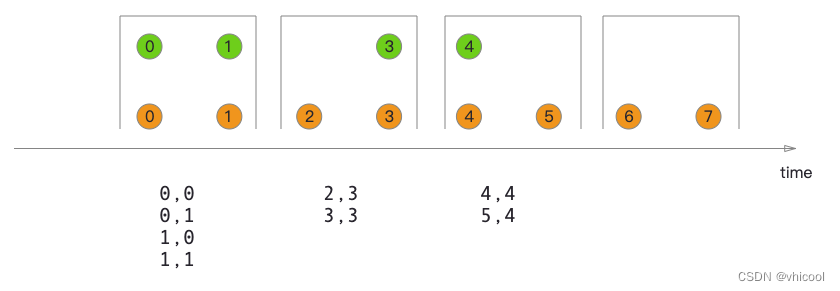
如图所示,我们定义了一个大小为2毫秒的翻转窗口,其结果为[0,1],[2,3]形式的窗口
DataStream<Integer> orangeStream = ...
DataStream<Integer> greenStream = ...
orangeStream.join(greenStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(TumblingEventTimeWindows.of(Time.milliseconds(2)))
.apply (new JoinFunction<Integer, Integer, String> (){
@Override
public String join(Integer first, Integer second) {
return first + "," + second;
}
});
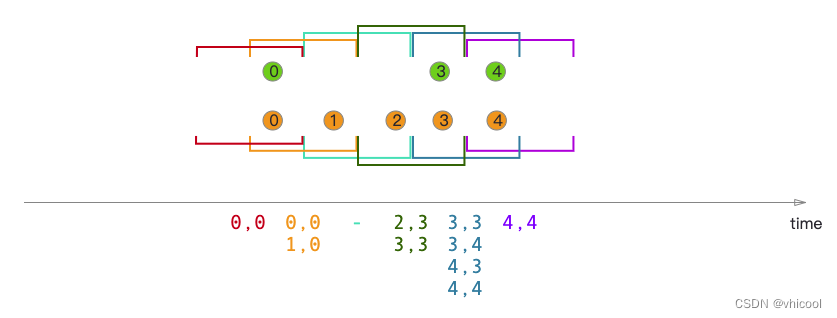
Sliding Window Join(滑动窗口join)
滑动**窗口有固定尺寸,数据可能会重复(当滑动尺寸小于窗口尺寸,数据会重复)。**当执行滑动窗口连接时,具有公共key和公共滑动窗口的所有元素将作为成对组合进行连接,并传递给JoinFunction或FlatJoinFusion。
在本例中,我们使用大小为两毫秒的滑动窗口,并将其滑动一毫秒,从而产生滑动窗口[1,0],[0,1],[1,2],[2,3]…。x轴下方的连接元素是传递给每个滑动窗口的JoinFunction的元素
DataStream<Integer> orangeStream = ...
DataStream<Integer> greenStream = ...
orangeStream.join(greenStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(SlidingEventTimeWindows.of(Time.milliseconds(2) /* size */, Time.milliseconds(1) /* slide */))
.apply (new JoinFunction<Integer, Integer, String> (){
@Override
public String join(Integer first, Integer second) {
return first + "," + second;
}
});
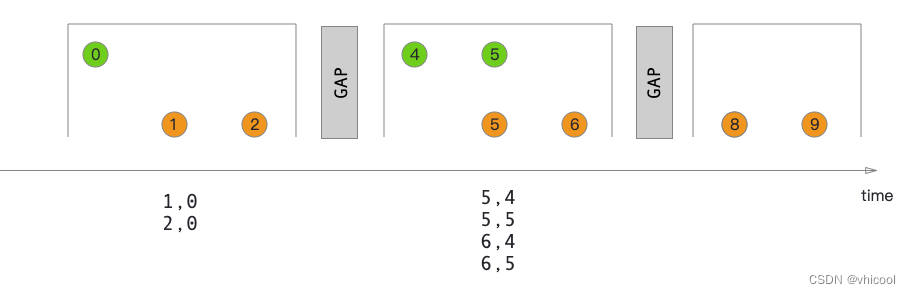
Session Window Join(会话窗口join)
**会话窗口不重叠并且没有固定的开始和结束时间,会话在固定时间内没有接受到数据时,会关闭当前会话,并开启新的会话。**当执行会话窗口连接时,具有相同key的所有元素(当“组合”时满足会话条件)将以成对组合的方式连接,并传递给JoinFunction或FlatJoinFusion
本例我们定义了一个会话窗口连接,其中每个会话被至少1ms的间隔分隔。
DataStream<Integer> orangeStream = ...
DataStream<Integer> greenStream = ...
orangeStream.join(greenStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(EventTimeSessionWindows.withGap(Time.milliseconds(1)))
.apply (new JoinFunction<Integer, Integer, String> (){
@Override
public String join(Integer first, Integer second) {
return first + "," + second;
}
});
Interval Join
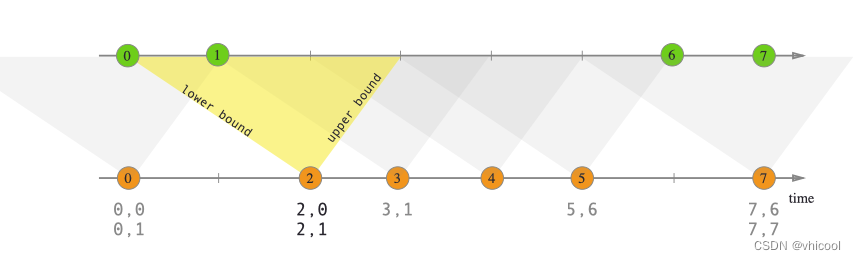
间隔连接使用一个公共key连接两个流的元素(A和B),其中流B的元素具有与流A中元素的时间戳相对的时间间隔中的时间戳,也就是:
b.timestamp ∈ [a.timestamp + lowerBound; a.timestamp + upperBound]。那么A和B有相同的key,就可以进行内部join间隔联接当前仅支持事件时间。
在上面的示例中,我们连接了两个流“橙色”和“绿色”,下限为-2毫秒,上限为+1毫秒。
orangeElem.ts + lowerBound <= greenElem.ts <= orangeElem.ts + upperBound
DataStream<Integer> orangeStream = ...
DataStream<Integer> greenStream = ...
orangeStream
.keyBy(<KeySelector>)
.intervalJoin(greenStream.keyBy(<KeySelector>))
.between(Time.milliseconds(-2), Time.milliseconds(1))
.process (new ProcessJoinFunction<Integer, Integer, String(){
@Override
public void processElement(Integer left, Integer right, Context ctx, Collector<String> out) {
out.collect(first + "," + second);
}
});
Flink sql query join
流式join
Regular Joins(双流join)
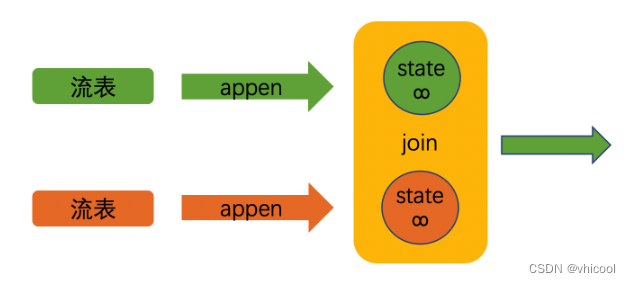
双流join是最通用的联接类型(支持 Batch\Streaming),其中任何新记录或联接两侧的更改都是可见的,并影响整体的Join结果。
对于流式查询,双流join的语法是最灵活的,允许任何类型的更新(插入、更新、删除)输入表。然而,此操作具有重要的操作含义:它需要将连接输入的两侧永远保持在Flink状态。因此,根据所有输入表和中间联接结果的不同输入行的数量,计算查询结果所需的状态可能会无限增长。可以为查询配置提供适当的状态生存时间(TTL),以防止状态大小过大。同时,这可能会影响查询结果的正确性。
因为资源问题 Regular Join 通常是不可持续的,一般只用做有界数据流的 Join。
数据一直根据输入流一直更新,“逐步逼近”最终的精确值,下游可能看到不断变化的结果,为了执行结果更新,下游需要定义主键。同时,状态可能会无限增长
特性:
- 支持INNER、LEFT、RIGHT、FULL OUT JOIN
- 语义语法和传统sql join一致
- 左右流都会触发更新
- 状态持续增长、一般结合 state TTl配合使用
语法:
SELECT * FROM Orders
[INNER|RIGHT|LEFT|FULL OUTER] JOIN Product
ON Orders.productId = Product.id
-
流表 join 流表
如果其中一个流表触发更新操作,同样触发join生成最新的结果
CREATE TABLE users ( user_id STRING, name STRING, age INT, gmt_time TIMESTAMP(3) ) WITH ( 'connector' = 'kafka', 'topic' = 'users', 'properties.bootstrap.servers' = 'localhost:9092', 'properties.group.id' = 'orders2ConsumerGroup', 'scan.startup.mode' = 'latest-offset', 'format' = 'json' ); CREATE TABLE address ( user_id STRING, address STRING, update_time TIMESTAMP(3) ) WITH ( 'connector' = 'kafka', 'topic' = 'address', 'properties.bootstrap.servers' = 'localhost:9092', 'properties.group.id' = 'orders2ConsumerGroup', 'scan.startup.mode' = 'latest-offset', 'format' = 'json' ); select u.user_id,u.name,u.age,a.address FROM users AS u LEFT JOIN address AS a ON u.user_id = a.user_id; --users -- {"user_id":"u1","name":"li","age":20,"gmt_time":"2022-11-01 10:00:00"} -- {"user_id":"u2","name":"li","age":20,"gmt_time":"2022-11-01 10:00:10"} --address -- {"user_id":"u1","address":"shanghai","update_time":"2022-11-01 10:00:05"} -- {"user_id":"u2","address":"beijing","update_time":"2022-11-01 10:00:15"} -- {"user_id":"u2","address":"anhui","update_time":"2022-11-01 10:00:16"} -- user_id name age address -- u1 li 20 shanghai -- u2 li 20 beijing -- u2 li 20 anhui -
维表 join 维表
CREATE TABLE users ( `user_id` STRING, `name` STRING, `age` INT, `gmt_time` TIMESTAMP(3) ) WITH ( 'connector' = 'jdbc', 'url' = 'jdbc:mysql://localhost:3306/flink', 'table-name' = 'user', 'username' = 'root', 'password' = '123456' ) CREATE TABLE address ( `user_id` STRING, `address` STRING, `gmt_time` TIMESTAMP(3) ) WITH ( 'connector' = 'jdbc', 'url' = 'jdbc:mysql://localhost:3306/flink', 'table-name' = 'user_address', 'username' = 'root', 'password' = '123456' ) select users.name, users.user_id, users.age, address.address from users,address where users.user_id = address.user_id
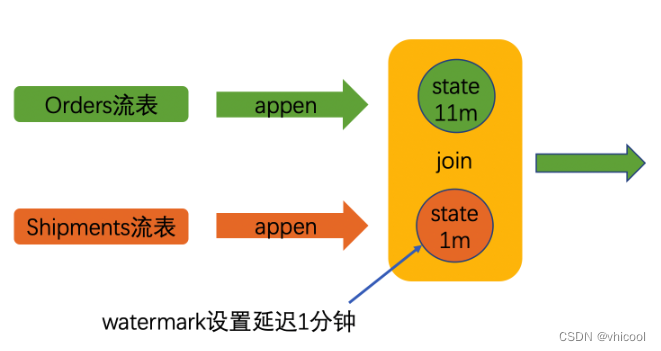
Interval Joins(区间join)
**是双流join的优化,**基于处理时间或事件时间,在一定时间区间内数据,相同的key进行join(支持 Batch\Streaming)。Interval Join 可以让一条流去 Join 另一条流中前后一段时间内的数据。对于stream查询,时间区间oin只支持有时间属性的
append-only表。由于时间属性是准单调递增的,Flink可以从其状态中删除旧值,而不会影响结果的正确性。
特征:由于给定了关联的区间,因此只需要保留很少的状态,内存压力较小。但是缺点是如果关联的数据晚到或者早到,导致落不到 JOIN 区间内,就可能导致结果不准确。只支持普通 Append 数据流,不支持含 Retract 的动态表。支持事件时间和处理时间
- 支持INNER、LEFT、RIGHT、FULL OUT JOIN
- 语义语法和传统sql join一致
- 左右流都会触发更新
- state根据时间区间保留,自动清理
- 输出流保留时间属性
如:如果订单在收到订单10小时后发货,则此查询将把所有订单与其相应的发货联系起来
# 两表有时间戳字段,并且作为 watermark。或者使用PROCTIME() 函数来生成一个处理时间戳
SELECT *
FROM Orders o, Shipments s
WHERE o.id = s.order_id
AND o.order_time BETWEEN s.ship_time - INTERVAL '10' HOUR AND s.ship_time
有效的join连接条件
ltime = rtimeltime >= rtime AND ltime < rtime + INTERVAL '10' MINUTEltime BETWEEN rtime - INTERVAL '10' SECOND AND rtime + INTERVAL '5' SECOND
流表和流表
CREATE TABLE currency_rates (
currency STRING,
conversion_rate DECIMAL(32, 2),
update_time timestamp(3),
WATERMARK FOR update_time AS update_time
) WITH (
'connector' = 'kafka',
'topic' = 'currency_rates',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'currencyRatesGroup',
'scan.startup.mode' = 'latest-offset',
'format' = 'json'
);
CREATE TABLE orders (
order_id STRING,
price DECIMAL(32,2),
currency STRING,
order_time timestamp(3),
WATERMARK FOR order_time AS order_time) WITH (
'connector' = 'kafka',
'topic' = 'order',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'orders2ConsumerGroup',
'scan.startup.mode' = 'latest-offset',
'format' = 'json'
);
select o.order_id,o.price,o.order_time,c.currency
FROM orders o,currency_rates c
where o.currency=c.currency and o.order_time BETWEEN c.update_time - INTERVAL '1' HOUR AND c.update_time;
Temporal Joins(时态join)
时态表是一个随时间演变的表,在Flink中也称为动态表。时态表中的行与一个或多个时态周期相关联,并且所有Flink表都是时态的(动态的)。时态表包含一个或多个版本化的表快照,它可以是跟踪更改的更改历史表(例如数据库更改日志,包含所有快照),也可以是具体化更改的维表(例如包含最新快照的数据库表)。
时态表可以分为 版本表 和 普通表。
-
版本表(流表): 如果时态表中的记录可以追踪和并访问它的历史版本,这种表我们称之为版本表,来自数据库的 changelog (如mysql binlog)可以定义成版本表,版本表内的数据始终不会自动清理,只能通过upsert触发。
-
普通表(维表): 如果时态表中的记录仅仅可以追踪并和它的最新版本,这种表我们称之为普通表,来自数据库 或 HBase 、redis的表可以定义成普通表。
特征:
- 只支持INNER JOIN、LEFT JOIN
- 只有左流触发更新
- 输出流保留时间属性
时态join类型
- JOIN Lookup
- JOIN 版本表
JOIN hive分区表
语法
使用
FOR SYSTEM_TIME AS OF table1.proctime表示当左边表的记录与右边的维表join时,只匹配当前处理时间维表所对应的的快照数据(即关联维表当前最新的状态)
SELECT [column_list]
FROM table1 [AS <alias1>]
[LEFT] JOIN table2 FOR SYSTEM_TIME AS OF table1.{ proctime | rowtime } [AS <alias2>]
ON table1.column-name1 = table2.column-name1
扩展:Temporary table(临时表)和Temporal table(时态表)是两个不同概念。Temporary table是临时的表对象,属于当前Session,随着Session的结束而消失,该表不属于Catalog和DB
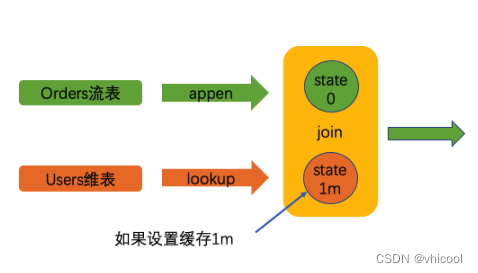
JOIN Lookup
特性:
Lookup join是针对于由作业流表触发,关联右侧维表来补全数据的场景 。默认情况下,在流表有数据变更,都会触发维表查询(可以通过设置维表是否缓存,来减轻查询压力),由于不保存状态,因此对内存占用较小
- 左侧为流表、右侧为维表
- 流表需要指定处理时间
- 具备lookup能力的外部系统
- 自己实现LookupTableSource接口connector
举例
kafka作为流表+jdbc、hbase、redis
--维表
CREATE TEMPORARY TABLE users (
`user_id` STRING,
`name` STRING,
`age` INT,
`gmt_time` TIMESTAMP(3)
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/flink',
'table-name' = 'user',
'username' = 'root',
'password' = '123456'
);
--流表
CREATE TABLE orders (
order_id STRING,
price DECIMAL(32,2),
user_id STRING,
order_time TIMESTAMP(3),
proctime AS PROCTIME()) WITH (
'connector' = 'kafka',
'topic' = 'order',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'latest-offset',
'format' = 'json'
);
----使用FOR SYSTEM_TIME AS OF table1.proc_time表示当左边表的记录与右边的维表join时,只匹配当前处理时间维表所对应的的快照数据(即关联维表当前最新的状态)
select orders.order_id,orders.price,orders.order_time,c.name
FROM orders
LEFT JOIN users FOR SYSTEM_TIME AS OF orders.proctime AS c
ON orders.user_id = c.user_id;
JOIN 版本表
可以追溯数据历史版本的表,如:数据库changelog,数据源有:mysql-binlog、kafka-upsert、oracle-cdc等。需要具备事件时间和主键两个属性。
-
**版本表:**本身具备upsert特性的表,直接作为版本表的数据源使用
CREATE TABLE currency_rates ( currency STRING, conversion_rate DECIMAL(32, 2), update_time TIMESTAMP(3), WATERMARK FOR update_time AS update_time, --事件时间 PRIMARY KEY(currency) NOT ENFORCED -- 主键 ) WITH ( 'connector' = 'kafka', 'value.format' = 'debezium-json', --changelog数据源:{"before":{},"after":{},"op":"u"} /* ... */ ); SELECT order_id, price, currency, conversion_rate, order_time FROM orders LEFT JOIN currency_rates FOR SYSTEM_TIME AS OF orders.order_time ON orders.currency = currency_rates.currency; -
版本视图:本身不是版本表,通过视图、函数转换为版本视图
-- kafka json格式的数据为append-only数据源 CREATE TABLE ratesHistory ( currency STRING, conversion_rate DECIMAL(32, 2), update_time TIMESTAMP(3), WATERMARK FOR update_time AS update_time --事件时间 ) WITH ( 'connector' = 'kafka', 'format' = 'json', /* ... */ ); -- 转化为版本视图 CREATE VIEW versionedRates AS SELECT currency,conversion_rate,update_time -- 事件时间:update_time FROM ( SELECT * ,ROW_NUMBER() OVER(PARTITION BY currency -- 主键:currency ORDER BY update_time DESC) AS rowNum FROM ratesHistory) where rowNum=1; SELECT order_id, price, currency, conversion_rate, order_time FROM orders LEFT JOIN versionedRates FOR SYSTEM_TIME AS OF orders.order_time ON orders.currency = currency_rates.currency;
Event Time Temporal Join(版本表)
事件时间临时join 允许针对版本化表进行联接。这意味着可以通过更改元数据来丰富表,并在某个时间点检索其值。临时join取一个任意表(左输入),并将每一行与版本化表(右输入)中相应行的相关版本相关联。没有时间窗口
特性:
与双流join不同,尽管构建端发生了更改,但之前的临时表结果不会受到影响。与间隔join相比,时态表join没有定义oin记录的时间窗口。左侧表的记录总是在时间属性指定的时间与右侧表的版本连接。因此,构建端的行可能任意陈旧
- 左侧为流表、右侧为版本表
- 两侧表都需要指定事件时间
- 版本表的数据会持续增加
满足场景:
-
左输入表为流表,右输入表为版本表( Changelog 动态表,即 Upsert、Retract 数据流,而非 Append 数据流)
-
两侧表都需要设置watermark,版本表需要设置主键,主键必须包含在 JOIN 等值条件中
-
版本表发生变更,不会触发查询结果输出,会根据主键更新临时表
**举例 **
用户在下订单时,需要根据订单时间的汇率,计算订单金额,其中下单是以不同的货币技术,我们需要将他输出到特定货币(CNY)
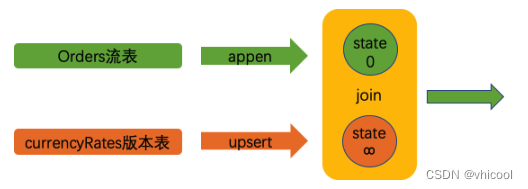
# 订单表(普通表)
CREATE TABLE orders (
order_id STRING,
price DECIMAL(32,2),
currency STRING,
order_time timestamp(3),
WATERMARK FOR order_time AS order_time
) WITH (
'connector' = 'kafka',
'topic' = 'order',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'orders2ConsumerGroup',
'scan.startup.mode' = 'latest-offset',
'format' = 'json'
);
-- 汇率表 (版本表)
CREATE TABLE currency_rates (
currency STRING,
conversion_rate DECIMAL(32, 2),
update_time TIMESTAMP(3),
WATERMARK FOR update_time AS update_time,
PRIMARY KEY(currency) NOT ENFORCED
) WITH (
'connector' = 'kafka',
'topic' = 'currency_rates',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'currencyRatesGroup',
'scan.startup.mode' = 'latest-offset',
'format' = 'debezium-json',
'debezium-json.schema-include' = 'true'
);
select o.order_id,o.price,o.order_time,c.currency
FROM orders AS o
LEFT JOIN currency_rates FOR SYSTEM_TIME AS OF o.order_time AS c
ON o.currency = c.currency;
-- 汇率表(版本视图)
CREATE TABLE ratesHistory (
currency STRING,
conversion_rate DECIMAL(32, 2),
update_time TIMESTAMP(3),
WATERMARK FOR update_time AS update_time
) WITH (
'connector' = 'kafka',
'topic' = 'currency_rates',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'currencyRatesGroup',
'scan.startup.mode' = 'latest-offset',
'format' = 'json'
);
CREATE VIEW versionedRates AS
SELECT currency,conversion_rate,update_time
FROM (
SELECT * ,ROW_NUMBER() OVER(PARTITION BY currency
ORDER BY update_time DESC) AS rowNum
FROM ratesHistory)
where rowNum=1;
select o.order_id,o.price,o.order_time,c.currency
FROM orders AS o
LEFT JOIN versionedRates FOR SYSTEM_TIME AS OF o.order_time AS c
ON o.currency = c.currency;
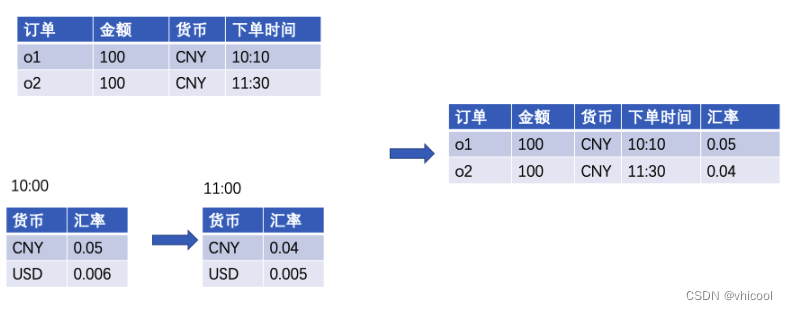
Processing Time Temporal Join(不建议使用)
由于基于处理时间的时态表 JOIN 存在 Bug(参见 FLINK-19830),因此在最新的 Flink 版本中已被禁用
处理时间临时表join使用处理时间属性将行与外部版本化表中key的最新版本相关联。和事件时间临时join的区别是:右侧版本话表没有版本时间作为事件时间用来设置watermark,因此需要使用处理时间作为版本时间。这种join的强大之处在于,当在Flink中将表具体化为动态表不可行时,它允许Flink直接与外部系统协作。
SELECT
o_amount, r_rate
FROM
Orders,
LATERAL TABLE (Rates(o_proctime))
WHERE
r_currency = o_currency
JOIN LATERAL
JOIN LATERAL 是单流驱动的join,根据左表逐条数据动态和右表进行JOIN。相对于其他flink Jon,JOIN LATERAL 的右边不是一个物理表,而是一个视图(view)或者Table-valued Funciton。LATERAL和 CROSS APPLY的语义相同
单流驱动的join
# LATERAL
SELECT
e.NAME, e.DEPTNO, d.NAME
FROM EMPS e, LATERAL (
SELECT *
FORM DEPTS d
WHERE e.DEPTNO=d.DEPTNO
) as d;
# inner join
SELECT users, tag
FROM Orders, LATERAL TABLE(unnest_udtf(tags)) t AS tag;
SELECT order_id, res
FROM Orders,
LATERAL TABLE(table_func(order_id)) t(res)
SELECT order_id, res
FROM Orders
LEFT OUTER JOIN LATERAL TABLE(table_func(order_id)) t(res)
ON TRUE
# CROSS APPLAY
SELECT
c.customerid, c.city, o.orderid
FROM Customers c, CROSS APPLAY(
SELECT
o.orderid, o.customerid
FROM Orders o
WHERE o.customerid = c.customerid
) as o
# LATERAL
SELECT
e.NAME, e.DEPTNO, d.NAME
FROM EMPS e, LATERAL (
SELECT *
FORM DEPTS d
WHERE e.DEPTNO=d.DEPTNO
) as d;
窗口Join
窗口函数
Windowing table-valued functions (Windowing TVFs) Apache Flink提供了几个窗口表值函数(TVF),用于将表的元素划分为多个窗口,包括:
- Tumble Windows
- Hop Windows
- Cumulate Windows
- Session Windows (will be supported soon)
。基于SQL的窗口函数
TUMBLE(滚动窗口)
滚动窗口有固定的尺寸,窗口间的元素无重复
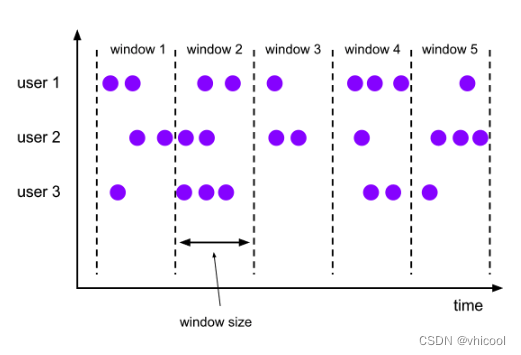
TUMBLE(TABLE data, DESCRIPTOR(timecol), size [, offset ])
data: 包含时间属性列的表timecol: 是一个列描述符,指示数据的哪个时间属性列应映射到滚动窗口size: 是指定滚动窗口宽度的持续时间。offset: 是一个可选参数,用于指定窗口将要开始的偏移量。
例:每10分钟将10分钟内的金额汇总计算
# 其中 watermark(`bidtime` - INTERVAL '1' SECOND )
SELECT window_start, window_end, SUM(price)
FROM TABLE(
TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES))
GROUP BY window_start, window_end;
HOP(滑动窗口)
HOP函数将元素分配给固定长度的窗口。与TUMBLE窗口函数类似,窗口的大小由窗口大小参数配置。另一个窗口滑动参数控制跳转窗口的启动频率
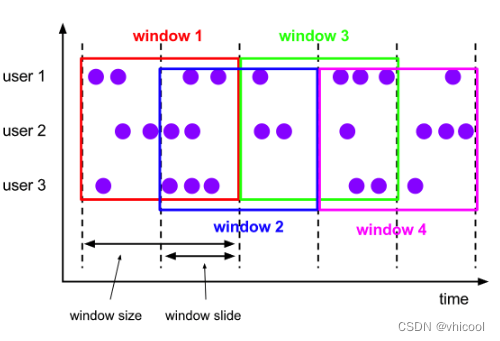
HOP(TABLE data, DESCRIPTOR(timecol), slide, size [, offset ])
data: 包含时间属性列的表timecol: 是一个列描述符,指示数据的哪个时间属性列应该映射到滑动窗口slide: 每个滑动窗口创建的间隔时间size: 是指定滑动窗口宽度的持续时间offset: 是一个可选参数,用于指定窗口将要开始的偏移量。
例:将10分钟内的金额汇总计算,并且每5分钟触发一次计算
# 其中 watermark(`bidtime` - INTERVAL '1' SECOND )
SELECT window_start, window_end, SUM(price)
FROM TABLE(
HOP(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '5' MINUTES, INTERVAL '10' MINUTES))
GROUP BY window_start, window_end;
CUMULATE(累积窗口)
CUMULATE函数有固定的窗口大小和步长,同一个窗口会按照步长逐步累计时间的形式,触发窗口计算操作,其他在同一窗口触发计算的多个滚动窗口有相同的window_start,window_end会累加步长的时间长度。
CUMULATE(TABLE data, DESCRIPTOR(timecol), step, size)
data: 包含时间属性列的表timecol: 是一个列描述符,指示数据的哪个时间属性列应映射到滚动窗口。step: 是指定连续累积窗口结束之间增加的窗口大小的持续时间(步长)size: 是指定累积窗口的最大宽度的持续时间。大小必须是步长的整数倍。offset: 是一个可选参数,用于指定窗口将要开始的偏移量。
例:每2分钟计算总金额,并在累积10分钟后,计算总金额
SELECT window_start, window_end, SUM(price)
FROM TABLE(
CUMULATE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '2' MINUTES, INTERVAL '10' MINUTES))
GROUP BY window_start, window_end;
窗口Join语法
窗口join将时间维度添加到join条件本身中。这样做时,窗口join将两个流的元素连接在一起,这两个流共享一个公共键并位于同一窗口中。窗口join的语义与DataStream窗口联接相同
特性:对于流式查询,与连续表上的其他join不同,窗口join不发出中间结果,而只在窗口结束时发出最终结果,后续延迟数据可能会丢失,实时性和准确性方面都相对较差。此外,窗口join在不再需要时清除所有中间状态
窗口触发join的条件:
- 两个流的水位线均已经推进到
window_end
支持的join类型:
INNER/LEFT/RIGHT/FULL OUTER/ANTI/SEMI JOIN
语法:
SELECT ...
FROM L [LEFT|RIGHT|FULL OUTER] JOIN R -- L and R are relations applied windowing TVF
ON L.window_start = R.window_start AND L.window_end = R.window_end AND ...
-
INNER/LEFT/RIGHT/FULL OUTER JOIN
SELECT L.num as L_Num, L.id as L_Id, R.num as R_Num, R.id as R_Id, L.window_start, L.window_end FROM ( SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES)) ) L FULL JOIN ( SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES)) ) R ON L.num = R.num AND L.window_start = R.window_start AND L.window_end = R.window_end;例:
CREATE TABLE users ( user_id STRING, name STRING, age INT, gmt_time TIMESTAMP(3), WATERMARK FOR gmt_time AS gmt_time ) WITH ( 'connector' = 'kafka', 'topic' = 'users', 'properties.bootstrap.servers' = 'localhost:9092', 'properties.group.id' = 'orders2ConsumerGroup', 'scan.startup.mode' = 'latest-offset', 'format' = 'json' ); CREATE TABLE address ( user_id STRING, address STRING, update_time TIMESTAMP(3), WATERMARK FOR update_time AS update_time ) WITH ( 'connector' = 'kafka', 'topic' = 'address', 'properties.bootstrap.servers' = 'localhost:9092', 'properties.group.id' = 'orders2ConsumerGroup', 'scan.startup.mode' = 'latest-offset', 'format' = 'json' ); SELECT u.user_id,a.address ,u.window_start,u.window_end FROM ( SELECT * FROM TABLE(TUMBLE(TABLE users,DESCRIPTOR(gmt_time),INTERVAL '10' SECONDS)) ) AS u LEFT JOIN ( SELECT * FROM TABLE(TUMBLE(TABLE address,DESCRIPTOR(update_time),INTERVAL '10' SECONDS)) )AS a ON u.user_id = a.user_id AND u.window_start =a.window_start AND u.window_end = a.window_end; --users -- {"user_id":"u1","name":"li","age":20,"gmt_time":"2022-11-01 10:00:00"} -- {"user_id":"u2","name":"li","age":20,"gmt_time":"2022-11-01 10:00:10"} -- {"user_id":"u2","name":"li","age":20,"gmt_time":"2022-11-01 10:00:20"} --address -- {"user_id":"u1","address":"shanghai","update_time":"2022-11-01 10:00:05"} -- {"user_id":"u2","address":"beijing","update_time":"2022-11-01 10:00:15"} -- {"user_id":"u2","address":"anhui","update_time":"2022-11-01 10:00:20"} user_id address window_start window_end u1 shanghai 2022-11-01 10:00:00.000 2022-11-01 10:00:10.000 u2 beijing 2022-11-01 10:00:10.000 2022-11-01 10:00:20.000 u2 anhui 2022-11-01 10:00:10.000 2022-11-01 10:00:20.000 -
SEMI JOIN
如果在公共窗口的右侧至少有一个匹配行,左窗口返回一行。
SELECT * FROM ( SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES)) ) L WHERE L.num IN ( SELECT num FROM ( SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES)) ) R WHERE L.window_start = R.window_start AND L.window_end = R.window_end); -
ANTI JOIN
返回左侧窗口没有右侧窗口没有匹配的数据
SELECT * FROM ( SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES)) ) L WHERE L.num NOT IN ( SELECT num FROM ( SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES)) ) R WHERE L.window_start = R.window_start AND L.window_end = R.window_end);
总结
| JOIN 类型 | 触发join | 场景 | 实时性 | 准确度 | 内存占用 | waterrmark | 时间属性 |
|---|---|---|---|---|---|---|---|
| 双流join | 双流 | 每一个数据流有变更都会触发join,并且状态会保存 | 高 | 先低后高(逐步更新) | 高(需要设置状态生存时间) | 否 | 事件时间、处理时间 |
| 时间区间 JOIN | 双流 | 拥有相同key且 事件时间处于 lowerBoundTime 和 upperBoundTime之间的元素进行join | 中 | 中(取决于区间大小) | 中(取决于区间大小) | 是(都需要) | 事件时间、处理时间 |
| 时态表 JOIN(版本表) | 单流 | 单流和版本表的join,具有历史版本状态管理功能。流表:事件时间,版本表:事件时间和主键 | 中 | 高(取决于具体实现) | 高(取决于版本表大小 ) | 是(都需要) | 事件时间 |
| 时态表 JOIN(Join Lookup ) | 单流 | 单流和维表的join,join要求一个表具有处理时间属性(流表),另一个表由查找源连接器支持(维表,实现了LookupableTableSource) | 高 | 高(取决于是否缓存、异步等) | 低(取决于是否缓存、异步等) | 是(流表) | 处理时间 |
| JOIN LATERAL | 单流 | 单流和UDTF的join。JOIN LATERAL 的右边不是一个物理表,而是一个视图(view)或者Table-valued Funciton。不具备状态管理功能 | 高 | 高(取决于是否缓存、异步等) | 低(取决于是否缓存、异步等) | 否 | |
| 窗口 JOIN | 双流 | 相同key且位于相同时间窗口的元素进行 join | 低 | 低(取决于窗口大小和类型) | 中(取决于窗口大小) | 是(都需要)watermark取双流中较慢的为准 | 事件时间、处理时间 |