Sqoop实操案例-互联网招聘数据迁移
🥇🥇【大数据学习记录篇】-持续更新中~🥇🥇
💓💓持续更新中,感谢各位前辈朋友们支持学习~💓💓
上一篇文章写到了Sqoop的安装与验证,这篇文章接着上篇文章延伸Sqoop迁移数据的案例操作,如果Sqoop没有安装成功的小伙伴们可以参考我上一篇文章:大数据组件Sqoop-安装与验证

1.环境介绍
本次用到的环境有:
Oracle Linux 7.4
Hadoop 2.7.4
mysql
sqoop
2.启动hadoop环境
1.打开命令窗口,启动HDFS平台。
start-all.sh
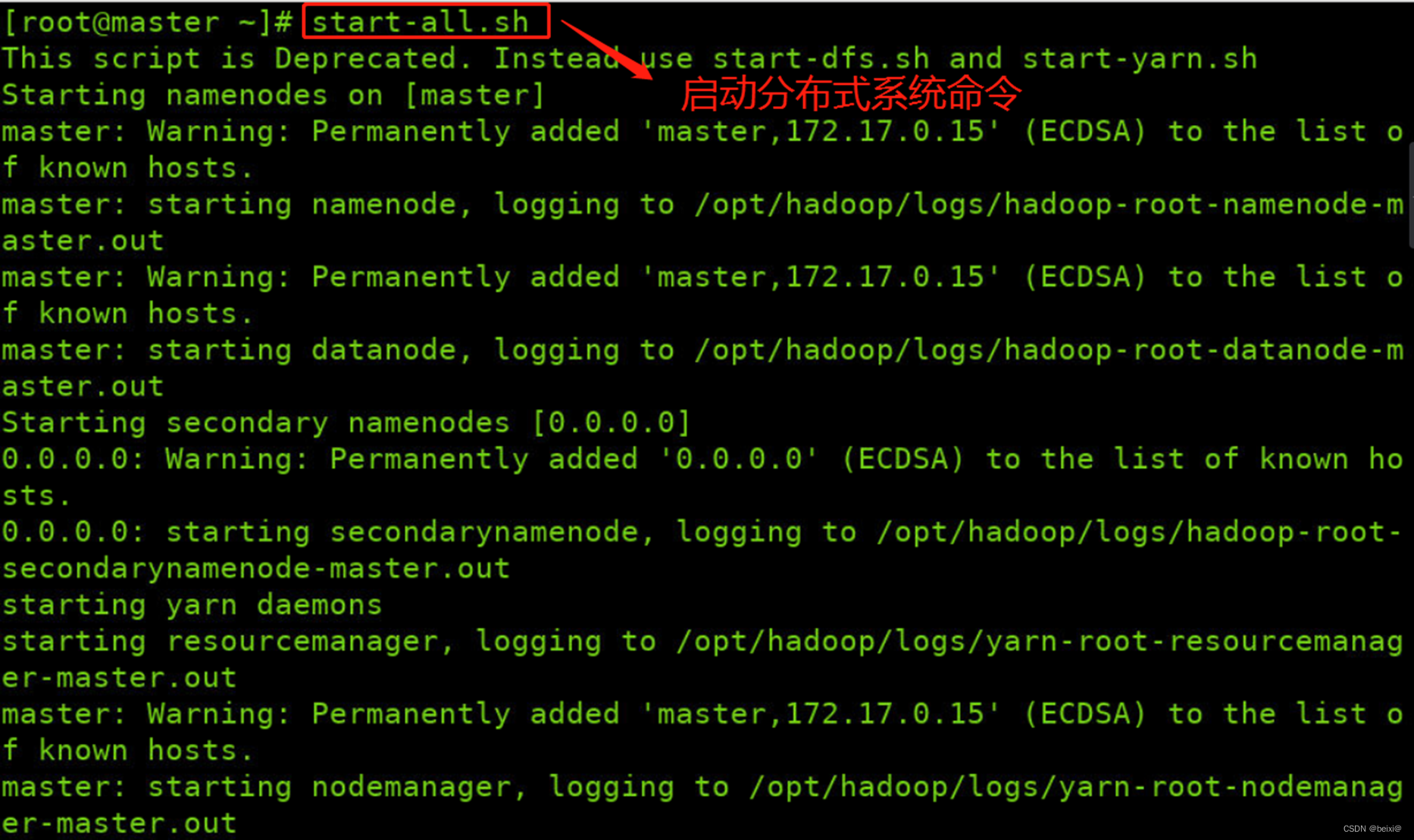
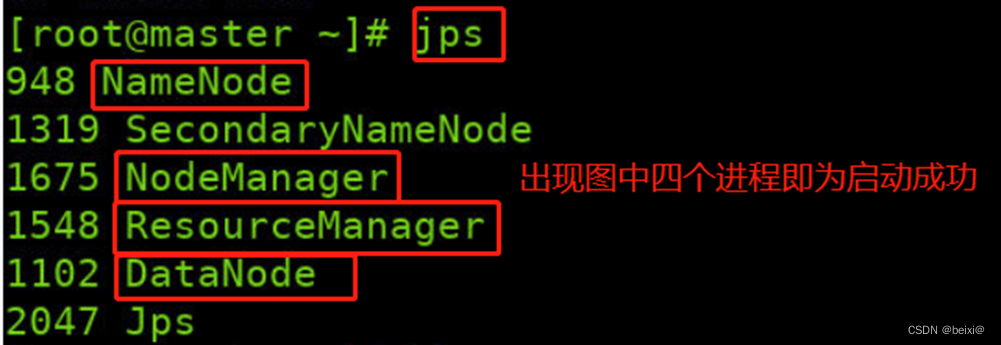
2.查看master上HDFS守护进程,注意:依据系统不同,实际显示可能与截图有出入,只要红色框中HDFS所示4个进程存在,即是正确
jps
3.互联网招聘数据迁移案例
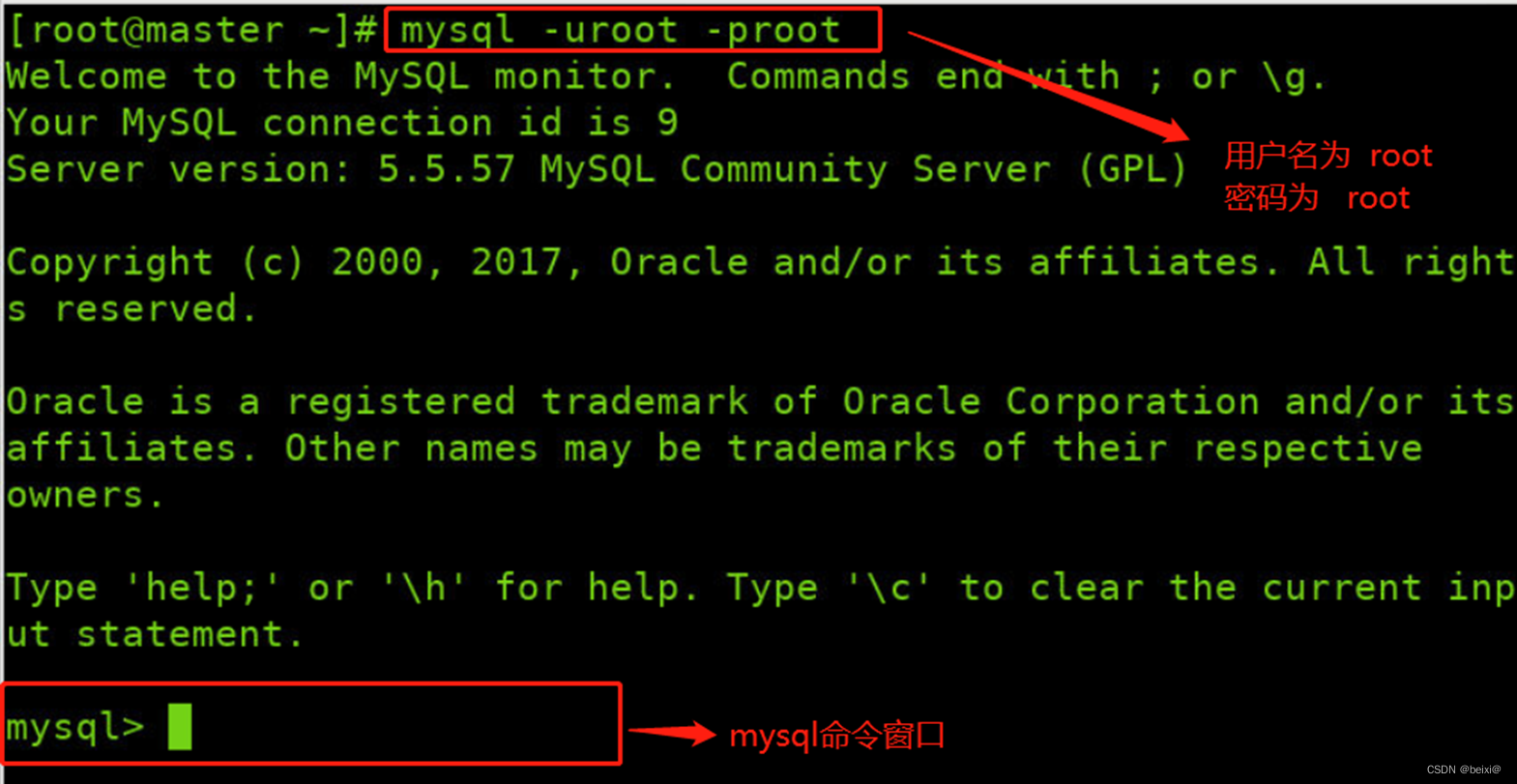
1.进入Linux命令窗口,登录mysql,我这里账号密码都是root
mysql -uroot -proot
2.构建源数据库
create database job_db character set 'utf8' collate 'utf8_general_ci';

3.查看数据库
show databases;

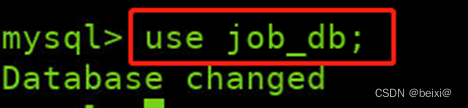
4.使用job_db数据库
use job_db;
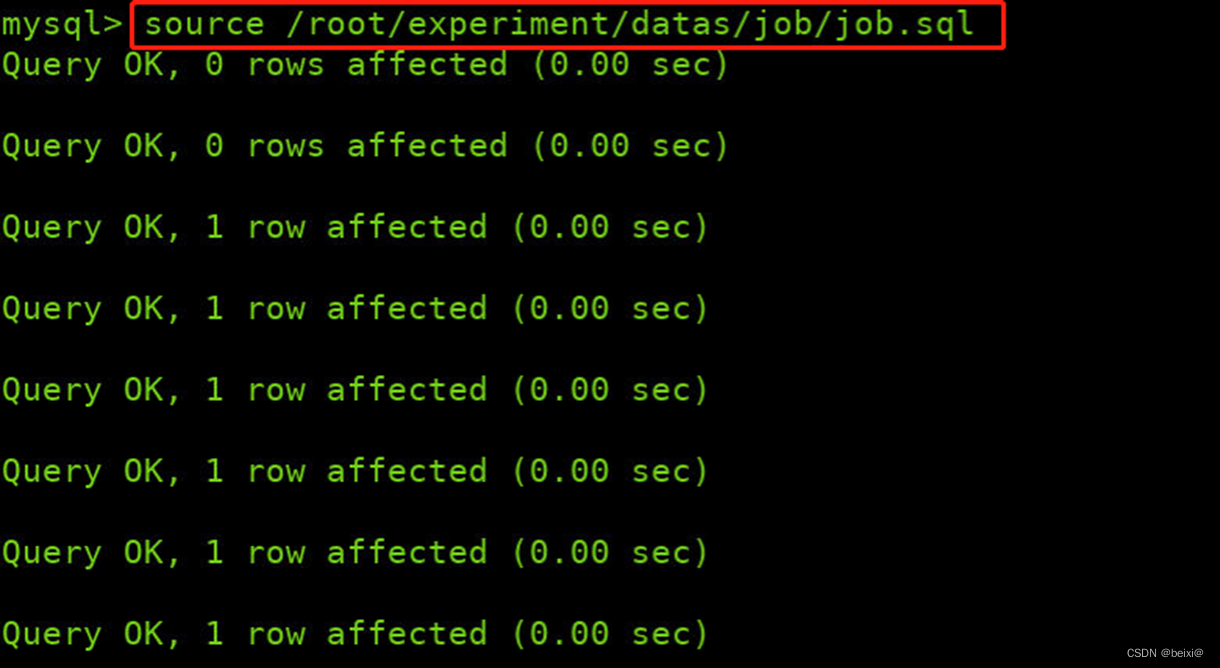
5.原始job.sql文件存储在/root/experiment/datas/job/job.sql,将原始数据导入mysql,构建原始表数据
source /root/experiment/datas/job/job.sql
6.查看导入结果
show tables;

7.查看表数据
select * from position;

8.退出mysql窗口
quit;
9. 进入sqoop根目录
cd /opt/sqoop

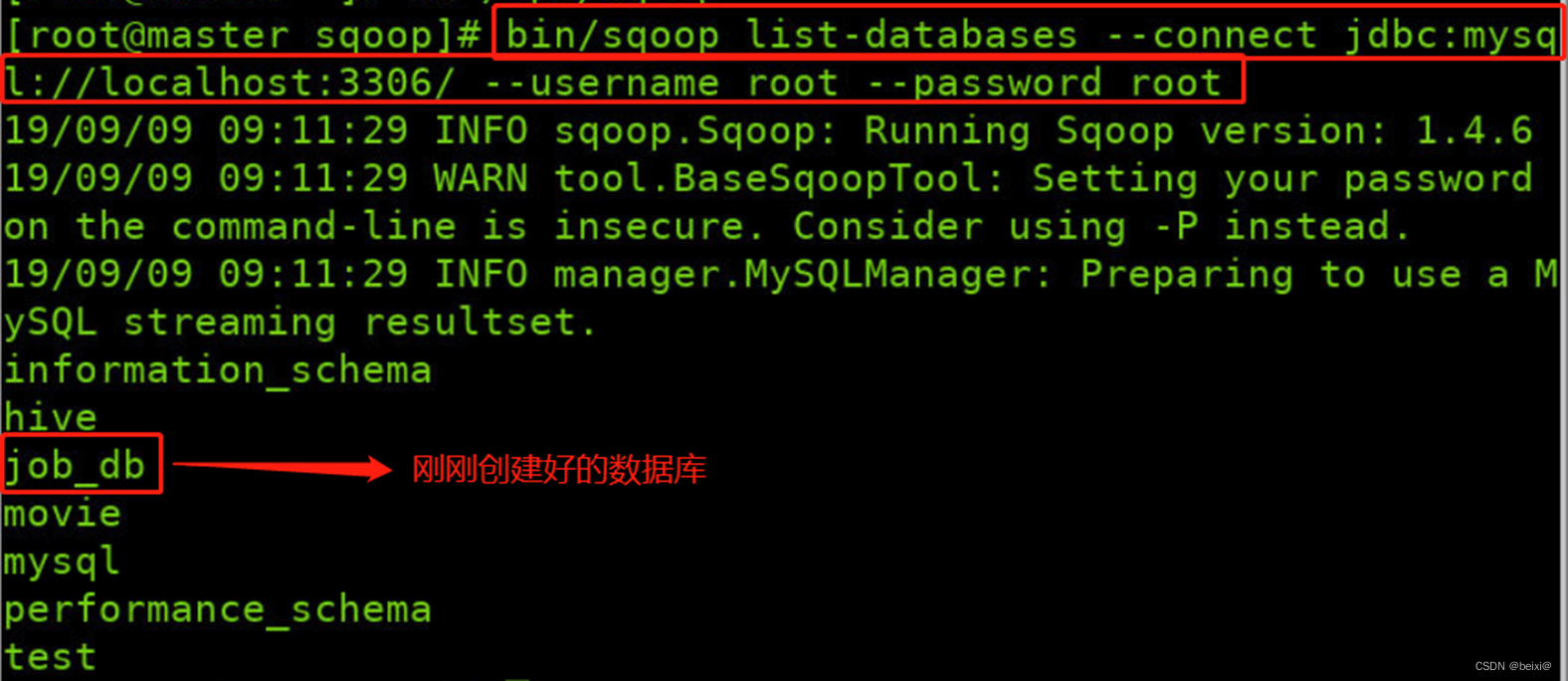
10.使用命令列出主机所有数据库
bin/sqoop list-databases --connect jdbc:mysql://localhost:3306/ --username root --password root
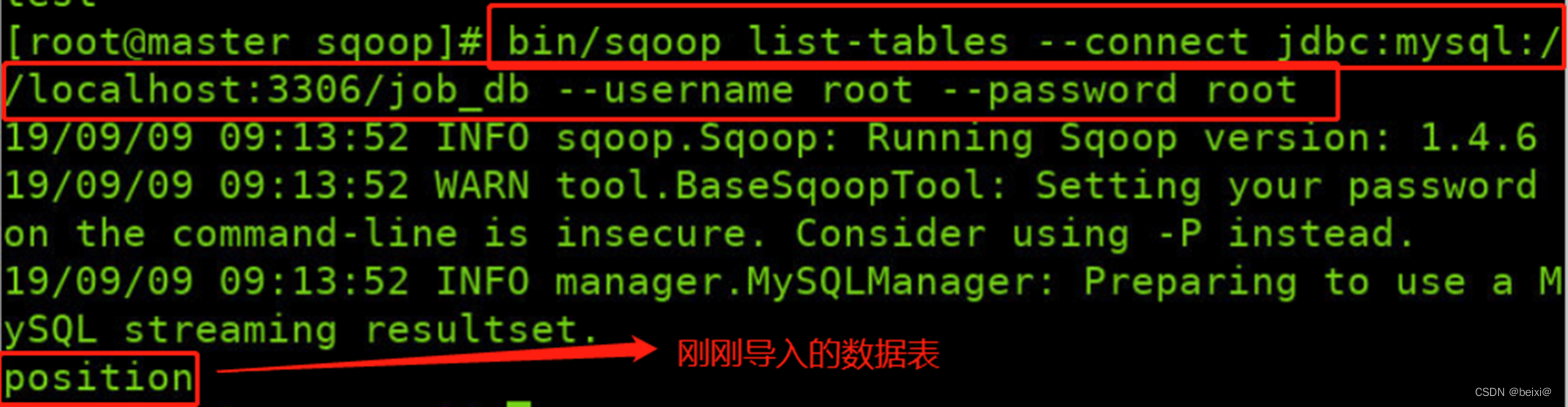
11.用命令列出job_db数据库中所有的数据表
bin/sqoop list-tables --connect jdbc:mysql://localhost:3306/job_db --username root --password root
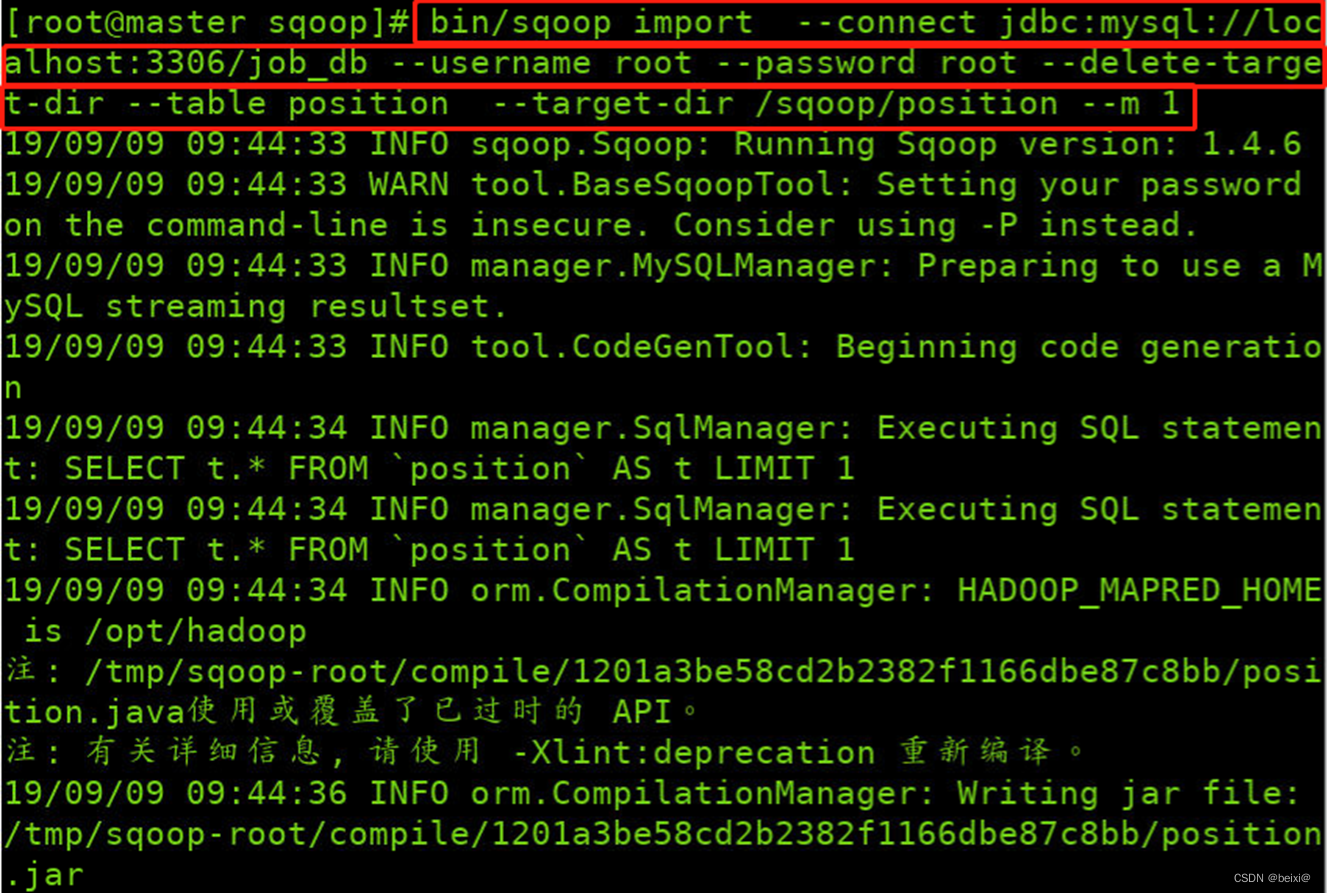
12.使用命令将数据库中的表导入到HDFS指定目录中
bin/sqoop import --connect jdbc:mysql://localhost:3306/job_db --username root --password root --delete-target-dir --table position --target-dir /sqoop/position --m 1
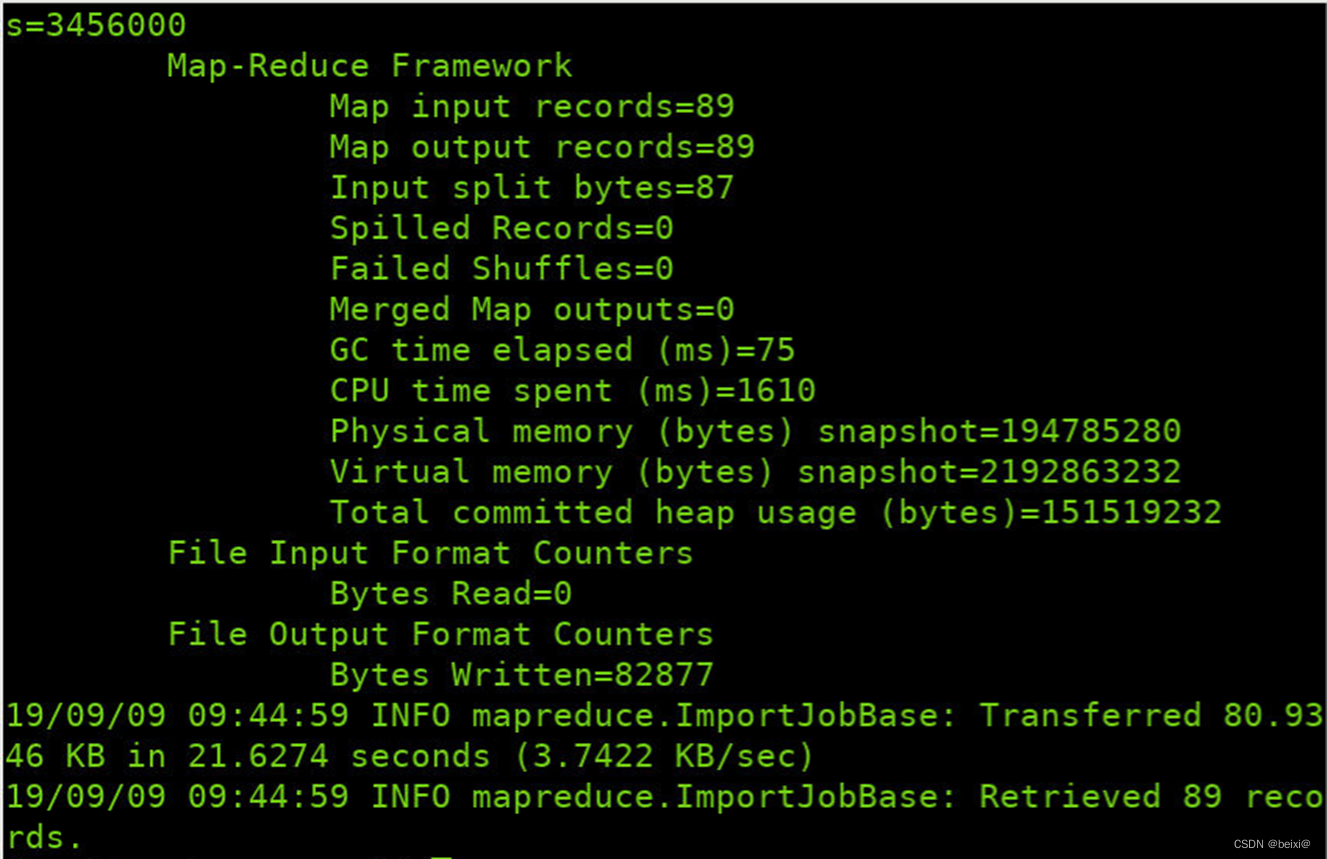
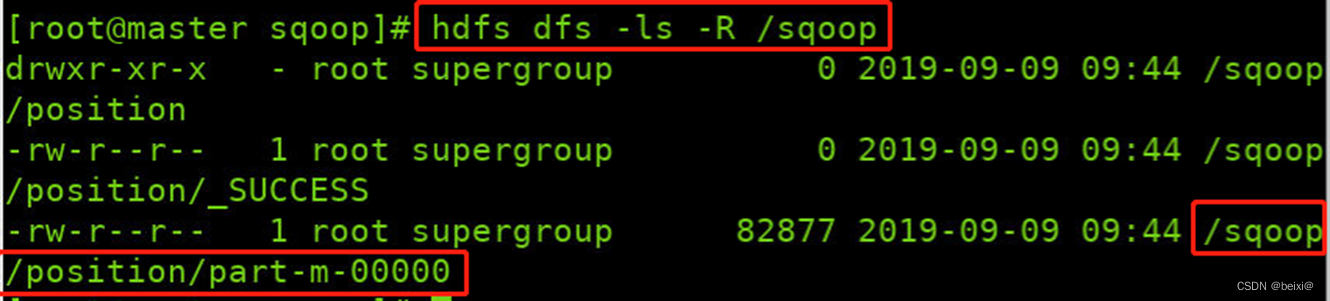
13.查看/sqoop目录下的文件
hdfs dfs -ls -R /sqoop
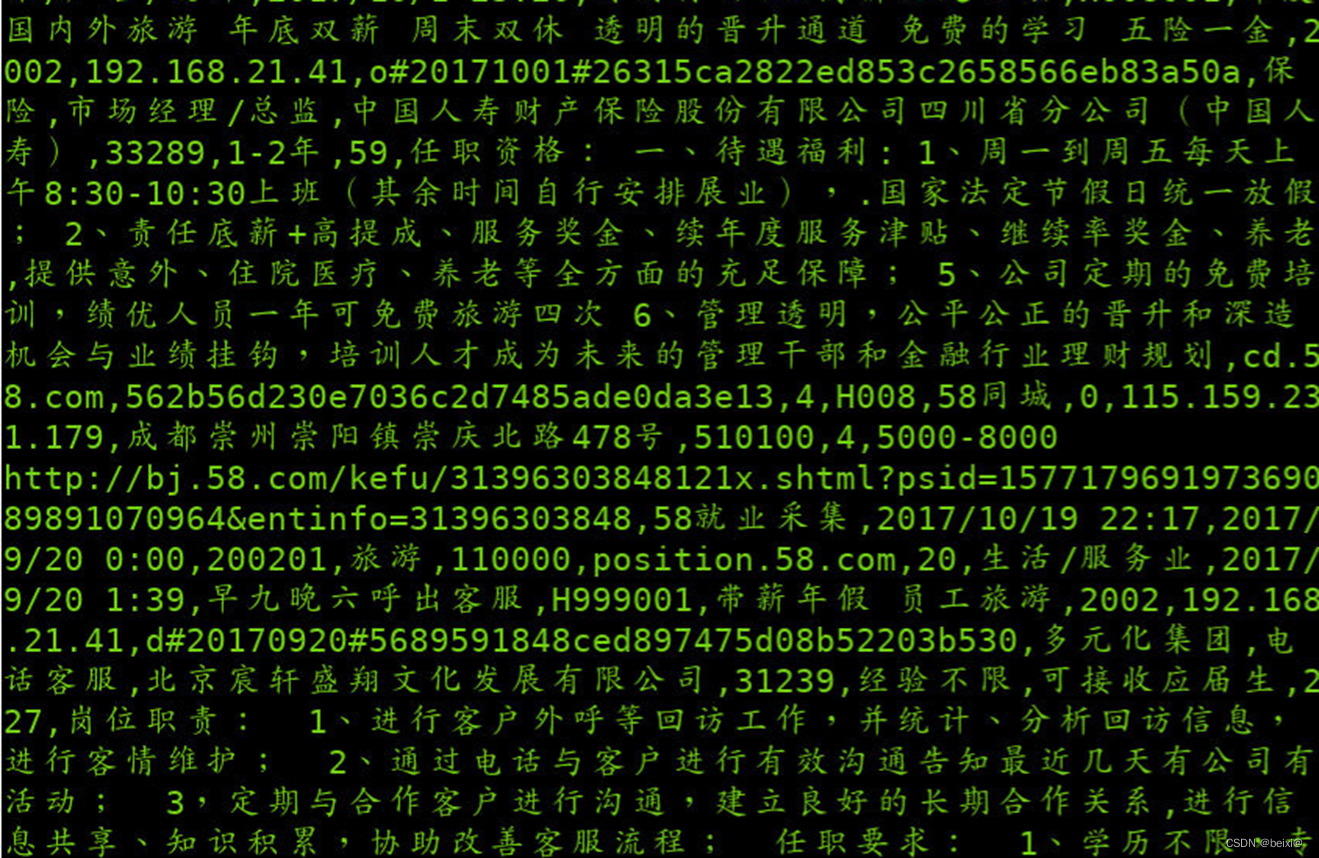
14.查看导入到HDFS的文件内容
hdfs dfs -cat /sqoop/position/part-m-00000

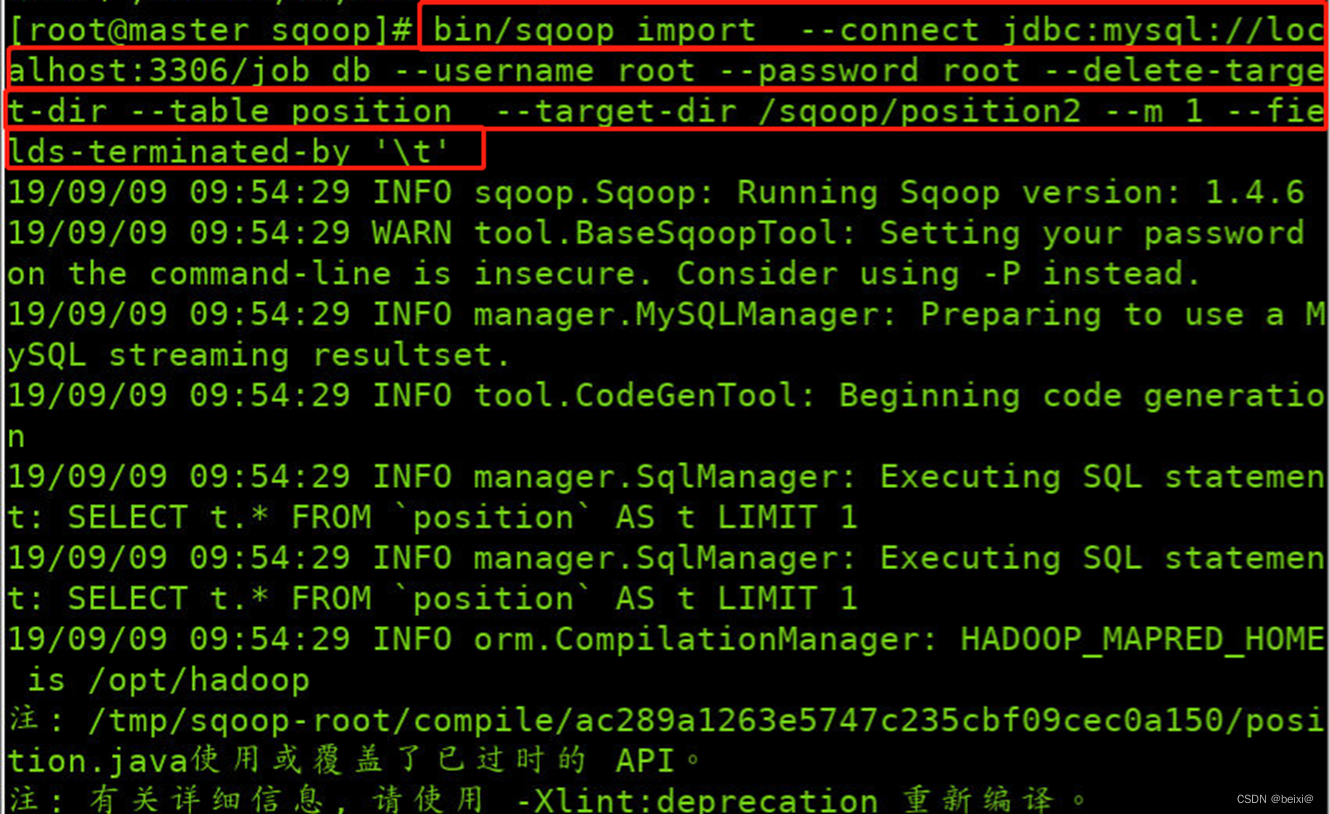
15.再次将数据库中的表数据导入HDFS中,此次采用Tab制表格将字段进行分割
bin/sqoop import --connect jdbc:mysql://localhost:3306/job_db --username root --password root --delete-target-dir --table position --target-dir /sqoop/position2 --m 1 --fields-terminated-by '\t'
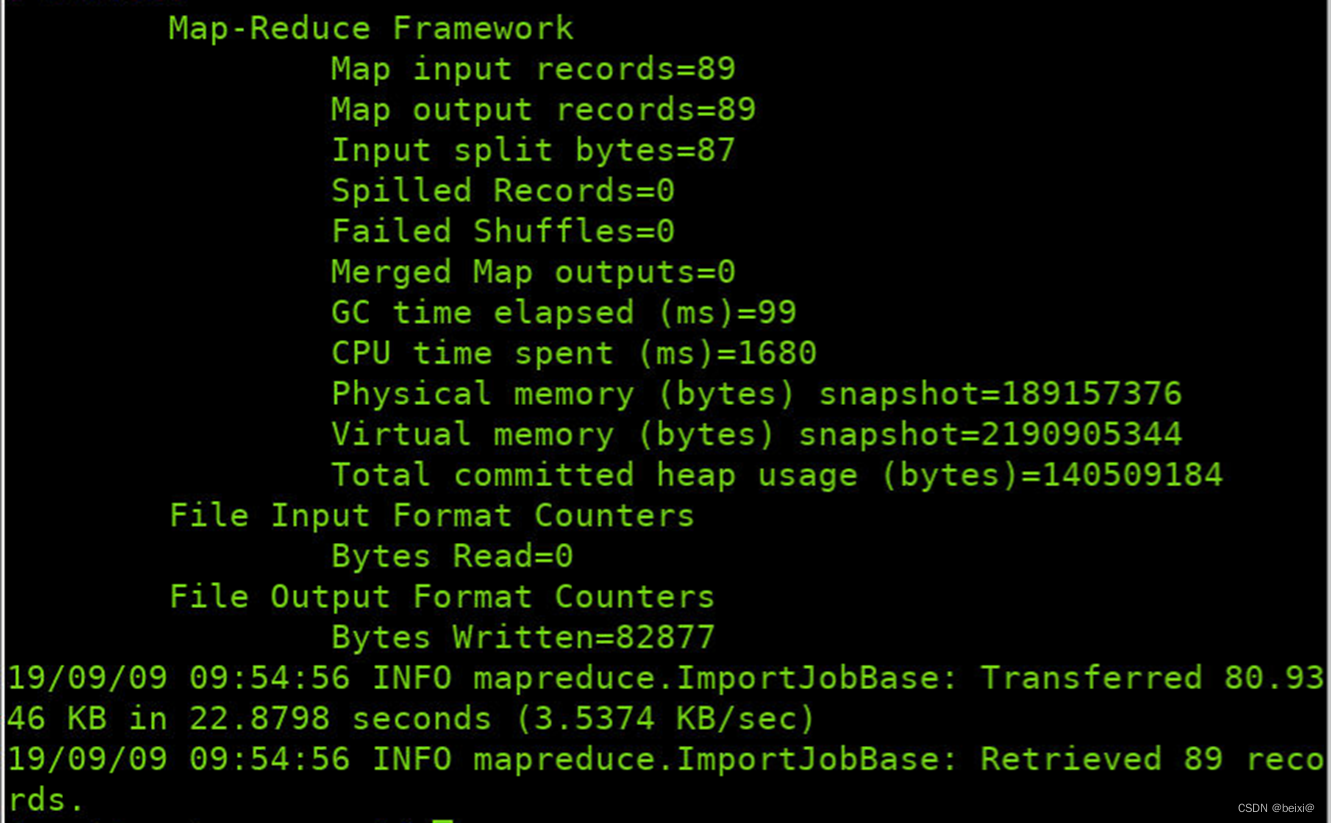
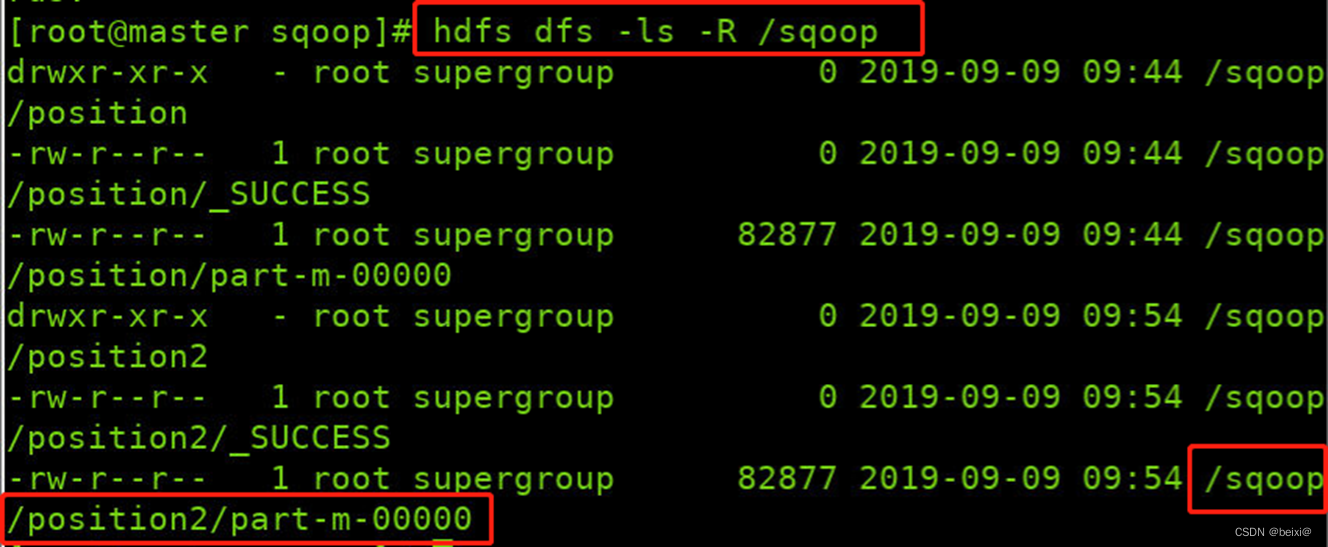
16.查看HDFS中sqoop目录下的内容
hdfs dfs -ls -R /sqoop
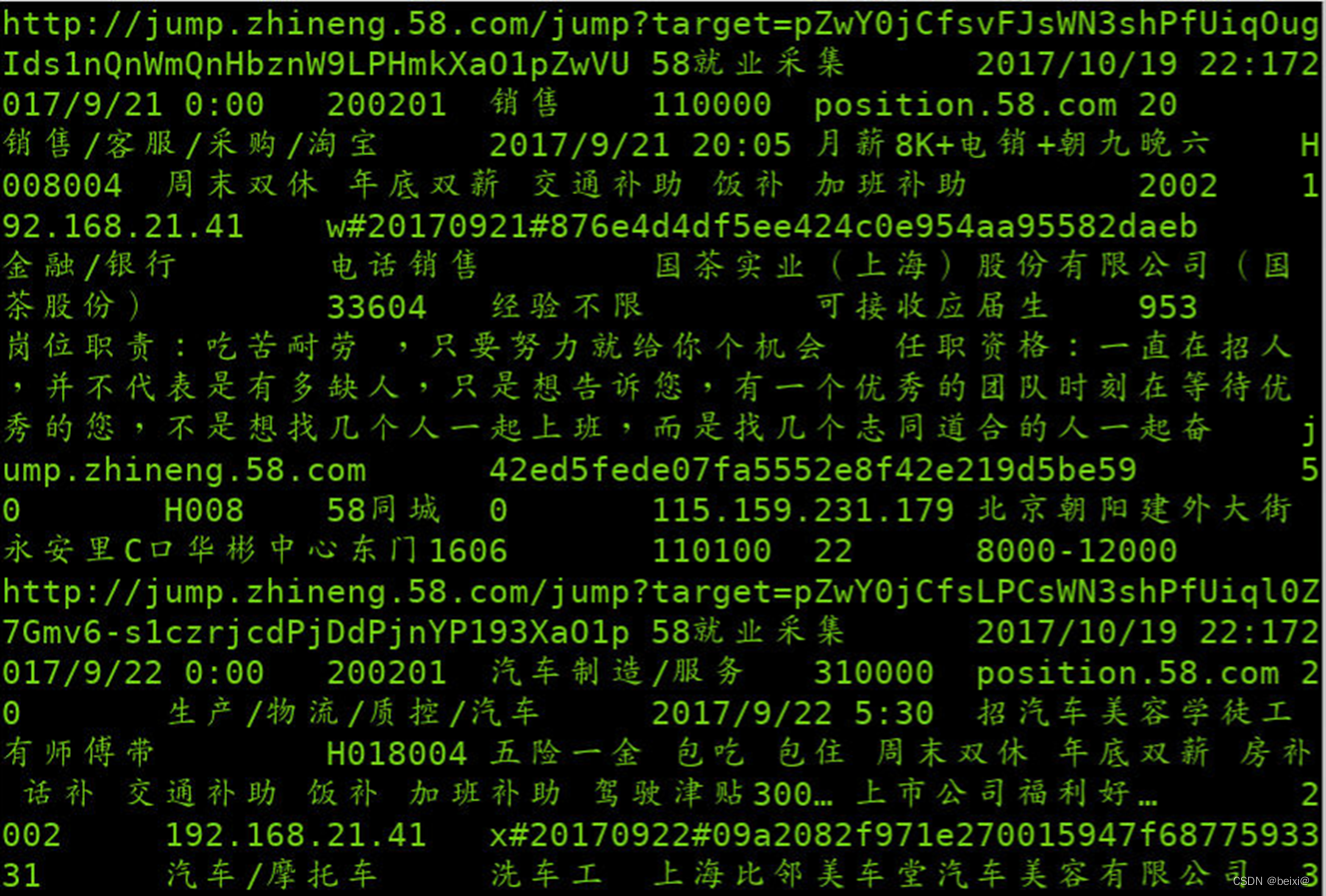
17.查看导入到HDFS的文件内容
hdfs dfs -cat /sqoop/position2/part-m-00000

至此,互联网招聘数据迁移案例实验到到此结束,如果本篇文章对你有帮助记得点赞收藏+关注~